- Linear models for ordinal regression Latent variable model
- Alternative models
- Software
- See also
- Notes
- References
- Further reading
In statistics, ordinal regression (also called "ordinal classification") is a type of regression analysis used for predicting an ordinal variable, i.e. a variable whose value exists on an arbitrary scale where only the relative ordering between different values is significant. It can be considered an intermediate problem between regression and classification[1][2]. Examples of ordinal regression are ordered logit and ordered probit. Ordinal regression turns up often in the social sciences, for example in the modeling of human levels of preference (on a scale from, say, 1–5 for "very poor" through "excellent"), as well as in information retrieval. In machine learning, ordinal regression may also be called ranking learning.[3]{{efn|Not to be confused with learning to rank.}}
Linear models for ordinal regression
Ordinal regression can be performed using a generalized linear model (GLM) that fits both a coefficient vector and a set of thresholds to a dataset. Suppose one has a set of observations, represented by length-{{mvar|p}} vectors {{math|x1}} through {{math|xn}}, with associated responses {{math|y1}} through {{mvar|yn}}, where each {{mvar|yi}} is an ordinal variable on a scale {{math|1, ..., K}}. For simplicity, and without loss of generality, we assume {{mvar|y}} is a non-decreasing vector, that is, {{mvar|1=yi  yi+1}}. To this data, one fits a length-{{mvar|p}} coefficient vector {{math|w}} and a set of thresholds {{math|θ1, ..., θK−1}} with the property that {{math|θ1 < θ2 < ... < θK−1}}. This set of thresholds divides the real number line into {{mvar|K}} disjoint segments, corresponding to the {{mvar|K}} response levels.
yi+1}}. To this data, one fits a length-{{mvar|p}} coefficient vector {{math|w}} and a set of thresholds {{math|θ1, ..., θK−1}} with the property that {{math|θ1 < θ2 < ... < θK−1}}. This set of thresholds divides the real number line into {{mvar|K}} disjoint segments, corresponding to the {{mvar|K}} response levels.
The model can now be formulated as
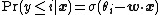
or, the cumulative probability of the response {{mvar|y}} being at most {{mvar|i}} is given by a function {{mvar|σ}} (the inverse link function) applied to a linear function of {{math|x}}. Several choices exist for {{mvar|σ}}; the logistic function
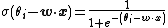
gives the ordered logit model, while using the probit function gives the ordered probit model. A third option is to use an exponential function
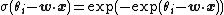
which gives the proportional hazards model.[4]
Latent variable model
The probit version of the above model can be justified by assuming the existence of a real-valued latent variable (unobserved quantity) {{mvar|y*}}, determined by[5]
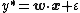
where {{mvar|ε}} is normally distributed with zero mean and unit variance, conditioned on {{math|x}}. The response variable {{mvar|y}} results from an "incomplete measurement" of {{mvar|y*}}, where one only determines the interval into which {{mvar|y*}} falls:
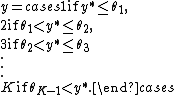
Defining {{math|θ0 {{=}} -∞}} and {{math|θK {{=}} ∞}}, the above can be summarized as {{math|y {{=}} k}} if and only if {{math|θk−1 < y* ≤ θk}}.
From these assumptions, one can derive the conditional distribution of {{mvar|y}} as{{r|wooldridge}}
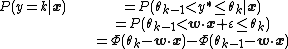
where {{math|Φ}} is the cumulative distribution function of the standard normal distribution, and takes on the role of the inverse link function {{mvar|σ}}. The log-likelihood of the model for a single training example {{math|xi}}, {{mvar|yi}} can now be stated as{{r|wooldridge}}
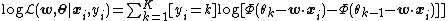
(using the Iverson bracket {{math|[yi {{=}} k]}}.) The log-likelihood of the ordered logit model is analogous, using the logistic function instead of {{math|Φ}}.[6]
Alternative models
In machine learning, alternatives to the latent-variable models of ordinal regression have been proposed. An early result was PRank, a variant of the perceptron algorithm that found multiple parallel hyperplanes separating the various ranks; its output is a weight vector {{math|w}} and a sorted vector of {{math|K−1}} thresholds {{math|θ}}, as in the ordered logit/probit models. The prediction rule for this model is to output the smallest rank {{mvar|k}} such that {{math|wx < θk}}.[7]
Other methods rely on the principle of large-margin learning that also underlies support vector machines.[8][9]
Another approach is given by Rennie and Srebro, who, realizing that "even just evaluating the likelihood of a predictor is not straight-forward" in the ordered logit and ordered probit models, propose fitting ordinal regression models by adapting common loss functions from classification (such as the hinge loss and log loss) to the ordinal case.[10]
Software
ORCA (Ordinal Regression and Classification Algorithms) is a Octave/MATLAB framework including a wide set of ordinal regression methods[11].
See also
- Logistic regression
Notes
{{notelist}}References
2. ^{{Cite journal|last=Gutiérrez|first=P. A.|last2=Pérez-Ortiz|first2=M.|last3=Sánchez-Monedero|first3=J.|last4=Fernández-Navarro|first4=F.|last5=Hervás-Martínez|first5=C.|date=January 2016|title=Ordinal Regression Methods: Survey and Experimental Study|journal=IEEE Transactions on Knowledge and Data Engineering|volume=28|issue=1|pages=127–146|doi=10.1109/TKDE.2015.2457911|issn=1041-4347|hdl=10396/14494}}
3. ^{{cite conference |last1=Shashua |first1=Amnon |first2=Anat |last2=Levin |title=Ranking with large margin principle: Two approaches |conference=NIPS |year=2002}}
4. ^{{cite journal |last=McCullagh |first=Peter |title=Regression models for ordinal data |journal=Journal of the Royal Statistical Society |series=Series B (Methodological) |volume=42 |number=2 | pages=109–142 |year=1980}}
5. ^{{cite book |first=Jeffrey M. |last=Wooldridge |title=Econometric Analysis of Cross Section and Panel Data |publisher=MIT Press |year=2010 |isbn=9780262232586 |pages=655–657}}
6. ^{{cite web |first=Alan |last=Agresti |title=Modeling Ordinal Categorical Data |url=http://www.stat.ufl.edu/~aa/ordinal/agresti_ordinal_tutorial.pdf |date=23 October 2010 |accessdate=23 July 2015}}
7. ^{{cite conference |first1=Koby |last1=Crammer |first2=Yoram |last2=Singer |title=Pranking with ranking |conference=NIPS |year=2001}}
8. ^{{cite journal |title=Support vector ordinal regression |first1=Wei |last1=Chu |first2=S. Sathiya |last2=Keerthi |citeseerx=10.1.1.297.3637 |journal=Neural Computation |year=2007 |doi=10.1162/neco.2007.19.3.792 |pmid=17298234 |volume=19 |issue=3 |pages=792–815}}
9. ^{{cite encyclopedia |title=Large Margin Rank Boundaries for Ordinal Regression |first1=Ralf |last1=Herbrich |first2=Thore |last2=Graepel |first3=Klaus |last3=Obermayer |encyclopedia=Advances in Large Margin Classifiers |publisher=MIT Press |year=2000 |pages=115–132 |url=http://research.microsoft.com/apps/pubs/default.aspx?id=65610}}
10. ^{{cite conference |title=Loss Functions for Preference Levels: Regression with Discrete Ordered Labels |first1=Jason D. M. |last1=Rennie |first2=Nathan |last2=Srebro |conference=Proc. IJCAI Multidisciplinary Workshop on Advances in Preference Handling |year=2005 |url=http://ttic.uchicago.edu/~nati/Publications/RennieSrebroIJCAI05.pdf}}
11. ^{{Citation|title=orca: Ordinal Regression and Classification Algorithms|date=2017-11-21|url=https://github.com/ayrna/orca|publisher=AYRNA|accessdate=2017-11-21}}
Further reading
- {{cite book | last = Agresti | first = Alan | title = Analysis of ordinal categorical data | publisher = Wiley | location = Hoboken, N.J | year = 2010 | isbn = 978-0470082898 }}
- {{cite book |last=Greene |first=William H. |authorlink=William Greene (economist) |title=Econometric Analysis |edition=Seventh |location=Boston |publisher=Pearson Education |year=2012 |isbn=978-0-273-75356-8 |pages=824–842 }}
- {{cite book |last=Hardin |first=James |last2=Hilbe |first2=Joseph |authorlink2=Joseph Hilbe |title=Generalized Linear Models and Extensions |publisher=College Station: Stata Press |date=2007 |edition=2nd | isbn=978-1-59718-014-6}}
- Rybka 3 Aquarium
- Rybka 4
- Rybka (disambiguation)
- Rybka (film)
- Rybka Lututowska
- Rybka Sokolska
- Rybki
- Rybkin
- Rybna
- Rybna (disambiguation)
- Rybna, Lesser Poland Voivodeship
- Rybna nad Zdobnici
- Rybna, Opole Voivodeship
- Rybna, Silesian Voivodeship
- Rybne
- Rybne, Masovian Voivodeship
- Rybne, Podkarpackie Voivodeship
- Rybnica (disambiguation)
- Rybnica, Jelenia Gora County
- Rybnica Lesna
- Rybnica Leśna
- Rybnica, Lublin Voivodeship
- Rybnica-Niwka
- Rybnica, Swietokrzyskie Voivodeship
- Rybnica, West Pomeranian Voivodeship