- Motivation and description of the method
- Examples Discrete Case - coin flipping Continuous Case - location parameter Continuous case - scale parameter Continuous case - Bertrand's paradox
- Discussion
- Notes
- References
The principle of transformation groups is a rule for assigning epistemic probabilities in a statistical inference problem. It was first suggested by Edwin T. Jaynes [1] and can be seen as a generalisation of the principle of indifference.
This can be seen as a method to create objective ignorance probabilities in the sense that two people who apply the principle and are confronted with the same information will assign the same probabilities.
Motivation and description of the method
The method is motivated by the following normative principle, or desideratum:
In two problems where we have the same prior information we should assign the same prior probabilitiesThe method then comes about from "transforming" a given problem into an equivalent one. This method has close connections with group theory, and to a large extent is about finding symmetry in a given problem, and then exploiting this symmetry to assign prior probabilities.
In problems with discrete variables (e.g. dice, cards, categorical data) the principle reduces to the principle of indifference, as the "symmetry" in the discrete case is a permutation of the labels, that is the permutation group is the relevant transformation group for this problem.
In problems with continuous variables, this method generally reduces to solving a differential equation. Given that differential equations do not always lead to unique solutions, this method cannot be guaranteed to produce a unique solution. However, in a large class of the most common types of parameters it does lead to unique solutions (see the examples below)
Examples
Discrete Case - coin flipping
Consider a problem where all you are told is that there is a coin, and it has a head (H) and a tail (T). Denote this information by I. You are then asked "what is the probability of Heads?". Call this problem 1 and denote the probability P(H|I). Consider another question "what is the probability of Tails?". Call this problem 2 and denote this probability by P(T|I).
Now from the information which was actually in the question, there is no distinction between heads and tails. The whole paragraph above could be re-written with "Heads" and "Tails" interchanged, and "H" and "T" interchanged, and the problem statement would not be any different. Using the desideratum then demands that
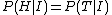
The probabilities must add to 1, this means that
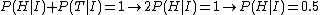 .
.
Thus we have a unique solution. This argument easily extents to N categories, to give the "flat" prior probability 1/N.
This provides a consistency based argument to the principle of indifference which goes as follows: if someone is truly ignorant about a discrete/countable set of outcomes apart from their potential existence, but does not assign them equal prior probabilities, then they are assigning different probabilities when given the same information.
This can be alternatively phrased as: a person who does not use the principle of indifference to assign prior probabilities to discrete variables, is either not ignorant about them, or reasoning inconsistently.
Continuous Case - location parameter
This is the easiest example for continuous variables. It is given by stating one is "ignorant" of the location parameter in a given problem. The statement that a parameter is a "location parameter" is that the sampling distribution, or likelihood of an observation X depends on a parameter  only through the difference
only through the difference
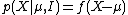
for some normalised, but otherwise arbitrary distribution f(.). Examples of location parameters include mean parameter of normal distribution with known variance and median parameter of Cauchy distribution with known inter-quartile range.
The two "equivalent problems" in this case, given ones knowledge of the sampling distribution , but no other knowledge about , is simply given by a "shift" of equal magnitude in X and . This is because of the relation:
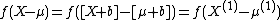
So simply "shifting" all quantities up by some number b and solving in the "shifted space" and then "shifting" back to the original one should give exactly the same answer as if we just worked on the original space. Making the transformation from to 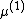 has a Jacobian of simply 1, and so the prior probability
has a Jacobian of simply 1, and so the prior probability 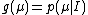 must satisfy the functional equation:
must satisfy the functional equation:
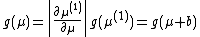
And the only function which satisfies this equation is the "constant prior":
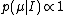
Thus the uniform prior is justified for expressing complete ignorance of a location parameter.
Continuous case - scale parameter
As in the above argument, a statement that  is a scale parameter means that the sampling distribution has the functional form:
is a scale parameter means that the sampling distribution has the functional form:
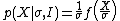
Where, as before f(.) is a normalised probability density function. The requirement that probabilities be finite and positive forces the condition  . Examples include the standard deviation of a normal distribution with known mean, the gamma distribution. The "symmetry" in this problem is found by noting that
. Examples include the standard deviation of a normal distribution with known mean, the gamma distribution. The "symmetry" in this problem is found by noting that
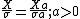
But, unlike in the location parameter case, the Jacobian of this transformation in the sample space and the parameter space is a, not 1. so the sampling probability changes to:
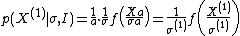
Which is invariant (i.e. has the same form before and after the transformation), and the prior probability changes to:
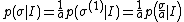
Which has the unique solution (up to a proportionality constant):
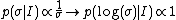
Which is the well-known Jeffreys prior for scale parameters, which is "flat" on the log scale, although it should be noted that it is derived using a different argument to that here, based on the Fisher information function. The fact that these two methods give the same results in this case does not imply it in general.
Continuous case - Bertrand's paradox
Edwin Jaynes used this principle to provide a resolution to Bertrand's Paradox[2]
by stating his ignorance about the exact position of the circle. The details are available in the reference or in the link.
Discussion
This argument depends crucially on I; changing the information may result in a different probability assignment. It is just as crucial as changing axioms in deductive logic - small changes in the information can lead to large changes in the probability assignments allowed by "consistent reasoning".
To illustrate suppose that the coin flipping example also states as part of the information that the coin has a side (S) (i.e. it is a real coin). Denote this new information by N. The same argument using "complete ignorance", or more precisely, the information actually described, gives:
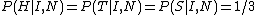
But this seems absurd to most people - intuition tells us that we should have P(S) very close to zero. This is because most people's intuition do not see "symmetry" between a coin landing on its side compared to landing on heads. Our intuition says that the particular "labels" actually carry some information about the problem. A simple argument could be used to make this more formal mathematically (e.g. the physics of the problem make it difficult for a flipped coin to land on its side) - we make a distinction between "thick" coins and "thin" coins [here thickness is measured relative to the coin's diameter]. It could reasonably be assumed that:
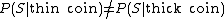
Note that this new information probably wouldn't break the symmetry between "heads" and "tails", so that permutation would still apply in describing "equivalent problems", and we would require:
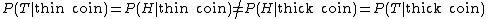
This is a good example of how the principle of transformation groups can be used to "flesh out" personal opinions. All of the information used in the derivation is explicitly stated. If a prior probability assignment doesn't "seem right" according to what your intuition tells you, then there must be some "background information" which has not been put into the problem.[3] It is then the task to try and work out what that information is. In some sense, by combining the method of transformation groups with one's intuition can be used to "weed out" the actual assumptions one has. This makes it a very powerful tool for prior elicitation.
Introducing the thickness of the coin is permissible because it was not specified in the problem, so this is still only using information in the question{{Huh|date=December 2017}}. Introducing a "nuisance parameter" and then making the answer invariant to this parameter is a very useful technique for solving supposedly "ill-posed" problems like Bertrand's Paradox. This has been called "the well-posing strategy" by some.[4]
The real power of this principle lies in its application to continuous parameters, where the notion of "complete ignorance" is not so well defined as in the discrete case. However, if applied with infinite limits, it often gives improper prior distributions. Note that the discrete case for a countably infinite set, such as (0,1,2,...) also produces an improper discrete prior. For most cases where the likelihood is sufficiently "steep" this does not present a problem. However, in order to be absolutely sure to avoid incoherent results and paradoxes, the prior distribution should be approached via a well defined and well behaved limiting process. One such process is the use of a sequence of priors with increasing range, such as 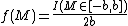 where the limit
where the limit 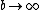 is to be taken at the end of the calculation i.e. after the normalisation of the posterior distribution. What this effectively is doing, is ensuring that one is taking the limit of the ratio, and not the ratio of two limits. See Limit of a function#Properties for details on limits and why this order of operations is important.
is to be taken at the end of the calculation i.e. after the normalisation of the posterior distribution. What this effectively is doing, is ensuring that one is taking the limit of the ratio, and not the ratio of two limits. See Limit of a function#Properties for details on limits and why this order of operations is important.
If the limit of the ratio does not exist or diverges, then this gives an improper posterior (i.e. a posterior which does not integrate to one). This indicates that the data are so uninformative about the parameters that the prior probability of arbitrarily large values still matters in the final answer. In some sense, an improper posterior means that the information contained in the data has not "ruled out" arbitrarily large values. Looking at the improper priors this way, it seems to make some sense that "complete ignorance" priors should be improper, because the information used to derive them is so meager that it cannot rule out absurd values on its own. From a state of complete ignorance, only the data or some other form of additional information can rule out such absurdities.
Notes
2. ^http://bayes.wustl.edu/etj/articles/well.pdf
3. ^http://bayes.wustl.edu/etj/articles/cmonkeys.pdf
4. ^{{cite journal |doi=10.1086/519028 |jstor=519028 |title=Bertrand's Paradox and the Principle of Indifference |year=2007 |last1=Shackel |first1=Nicholas |journal=Philosophy of Science |volume=74 |issue=2 |pages=150|url=http://orca.cf.ac.uk/3803/1/Shackel%20Bertrand%27s%20paradox%205.pdf }}
References
- Edwin Thompson Jaynes. Probability Theory: The Logic of Science. Cambridge University Press, 2003. {{ISBN|0-521-59271-2}}.
- Jean Gérault
- Jean Haefliger
- Jean haefliger
- Jean Hall
- Jean Halley
- Jean Hamilton (disambiguation)
- Jean Hamilton Walls
- Jean Hamlin
- Jean Harisson Marcelin
- Jean Harpedenne II
- Jean Harrower
- Jean Hatzfeld
- Jean Hatzfeld (hellenist)
- Jean Hay
- Jean Hay Bright
- Jean H. Baker
- Jean Headberry
- Jean Hegland
- Jean Helen St. Clair Campbell
- Jean Henault
- Jean Hendriks
- Jean Henri Bancal des Issarts
- Jean Henri Desmercières
- Jean Henri Gallier
- Jean-Henri-Guillaume Krombach