- Mathematical formulation
- TD-Lambda
- TD algorithm in neuroscience
- See also
- Notes
- Bibliography
- External links
While Monte Carlo methods only adjust their estimates once the final outcome is known, TD methods adjust predictions to match later, more accurate, predictions about the future before the final outcome is known.[2] This is a form of bootstrapping, as illustrated with the following example:
"Suppose you wish to predict the weather for Saturday, and you have some model that predicts Saturday's weather, given the weather of each day in the week. In the standard case, you would wait until Saturday and then adjust all your models. However, when it is, for example, Friday, you should have a pretty good idea of what the weather would be on Saturday - and thus be able to change, say, Saturday's model before Saturday arrives."[2]
Temporal difference methods are related to the temporal difference model of animal learning.[3][4][5][6][7]
Mathematical formulation
The tabular TD(0) method, one of the simplest TD methods, estimates the state value function of a finite-state Markov decision process (MDP) under a policy  . Let
. Let 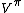 denote the state value function of the MDP with states
denote the state value function of the MDP with states 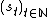 , rewards
, rewards 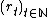 and discount rate
and discount rate  under the policy :
under the policy :
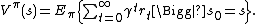
satisfies the Hamilton-Jacobi-Bellman Equation:
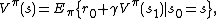
so 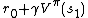 is an unbiased estimate for
is an unbiased estimate for 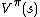 . This observation motivates the following algorithm for estimating .
. This observation motivates the following algorithm for estimating .
The algorithm starts by initializing a table 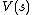 arbitrarily, with one value for each state of the MDP. A positive learning rate
arbitrarily, with one value for each state of the MDP. A positive learning rate  is chosen.
is chosen.
We then repeatedly evaluate the policy , obtain a reward  and update the value function for the old state using the rule:[8]
and update the value function for the old state using the rule:[8]
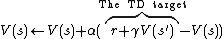
where  and
and  are the old and new states, respectively.
are the old and new states, respectively.
The value  is known as the TD target.
is known as the TD target.
TD-Lambda
TD-Lambda is a learning algorithm invented by Richard S. Sutton based on earlier work on temporal difference learning by Arthur Samuel.[1] This algorithm was famously applied by Gerald Tesauro to create TD-Gammon, a program that learned to play the game of backgammon at the level of expert human players.[9]The lambda ( ) parameter refers to the trace decay parameter, with
) parameter refers to the trace decay parameter, with 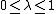 . Higher settings lead to longer lasting traces; that is, a larger proportion of credit from a reward can be given to more distant states and actions when is higher, with
. Higher settings lead to longer lasting traces; that is, a larger proportion of credit from a reward can be given to more distant states and actions when is higher, with 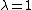 producing parallel learning to Monte Carlo RL algorithms.
producing parallel learning to Monte Carlo RL algorithms.
TD algorithm in neuroscience
The TD algorithm has also received attention in the field of neuroscience. Researchers discovered that the firing rate of dopamine neurons in the ventral tegmental area (VTA) and substantia nigra (SNc) appear to mimic the error function in the algorithm.[3][4][5][6][7] The error function reports back the difference between the estimated reward at any given state or time step and the actual reward received. The larger the error function, the larger the difference between the expected and actual reward. When this is paired with a stimulus that accurately reflects a future reward, the error can be used to associate the stimulus with the future reward.
Dopamine cells appear to behave in a similar manner. In one experiment measurements of dopamine cells were made while training a monkey to associate a stimulus with the reward of juice.[10] Initially the dopamine cells increased firing rates when the monkey received juice, indicating a difference in expected and actual rewards. Over time this increase in firing back propagated to the earliest reliable stimulus for the reward. Once the monkey was fully trained, there was no increase in firing rate upon presentation of the predicted reward. Continually, the firing rate for the dopamine cells decreased below normal activation when the expected reward was not produced. This mimics closely how the error function in TD is used for reinforcement learning.
The relationship between the model and potential neurological function has produced research attempting to use TD to explain many aspects of behavioral research.[11] It has also been used to study conditions such as schizophrenia or the consequences of pharmacological manipulations of dopamine on learning.[12]
See also
- Q-learning
- SARSA
- Rescorla-Wagner model
- PVLV
Notes
2. ^1 {{cite journal |author=Richard Sutton |title=Learning to predict by the methods of temporal differences |journal=Machine Learning |volume=3 |issue=1 |pages=9–44 |year=1988 |doi=10.1007/BF00115009}} (A revised version is available on Richard Sutton's publication page {{Webarchive|url=https://web.archive.org/web/20170330002227/http://incompleteideas.net/sutton/publications.html |date=2017-03-30 }})
3. ^1 {{cite journal|author=Schultz, W, Dayan, P & Montague, PR.|year=1997|title=A neural substrate of prediction and reward|journal=Science|volume=275|issue=5306|pages=1593–1599|doi=10.1126/science.275.5306.1593|pmid=9054347|citeseerx=10.1.1.133.6176}}
4. ^1 {{Cite journal|last=Montague|first=P. R.|last2=Dayan|first2=P.|last3=Sejnowski|first3=T. J.|date=1996-03-01|title=A framework for mesencephalic dopamine systems based on predictive Hebbian learning|journal=The Journal of Neuroscience|volume=16|issue=5|pages=1936–1947|issn=0270-6474|pmid=8774460|via=|doi=10.1523/JNEUROSCI.16-05-01936.1996}}
5. ^1 {{Cite journal|last=Montague|first=P.R.|last2=Dayan|first2=P.|last3=Nowlan|first3=S.J.|last4=Pouget|first4=A.|last5=Sejnowski|first5=T.J.|date=1993|title=Using aperiodic reinforcement for directed self-organization|url=http://www.gatsby.ucl.ac.uk/~dayan/papers/mdnps93.pdf|journal=Advances in Neural Information Processing Systems|volume=5|pages=969–976|via=}}
6. ^1 {{Cite journal|last=Montague|first=P. R.|last2=Sejnowski|first2=T. J.|date=1994|title=The predictive brain: temporal coincidence and temporal order in synaptic learning mechanisms|journal=Learning & Memory|volume=1|issue=1|pages=1–33|issn=1072-0502|pmid=10467583|via=}}
7. ^1 {{Cite journal|last=Sejnowski|first=T.J.|last2=Dayan|first2=P.|last3=Montague|first3=P.R.|date=1995|title=Predictive hebbian learning|url=http://delivery.acm.org/10.1145/230000/225300/p15-sejnowski.pdf?ip=45.3.85.181&id=225300&acc=ACTIVE%20SERVICE&key=B33240AC40EC9E30%2E80AE0C8B3B97B250%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35&__acm__=1526580622_547fa2985566491c27b961d258081cf2|journal=Proceedings of Eighth ACM Conference on Computational Learning Theory|volume=|pages=15–18|via=|doi=10.1145/230000/225300/p15-sejnowski|doi-broken-date=2019-02-17}}
8. ^{{Cite book|title=Reinforcement learning: An introduction|url=http://people.inf.elte.hu/lorincz/Files/RL_2006/SuttonBook.pdf|page=130|deadurl=yes|archiveurl=https://web.archive.org/web/20170712170739/http://people.inf.elte.hu/lorincz/Files/RL_2006/SuttonBook.pdf|archivedate=2017-07-12|df=}}
9. ^{{cite journal|title=Temporal Difference Learning and TD-Gammon|journal=Communications of the ACM|date=March 1995|first=Gerald|last=Tesauro|volume=38|issue=3|pages=58–68|id= |url=http://www.research.ibm.com/massive/tdl.html|accessdate=2010-02-08 | doi= 10.1145/203330.203343}}
10. ^{{cite journal |author=Schultz, W. |year=1998 |title=Predictive reward signal of dopamine neurons |journal=Journal of Neurophysiology |volume=80 |issue=1 |pages=1–27|doi=10.1152/jn.1998.80.1.1 |pmid=9658025 }}
11. ^{{cite journal |author=Dayan, P. |year=2001 |title=Motivated reinforcement learning |journal=Advances in Neural Information Processing Systems |volume=14 |pages=11–18 |publisher=MIT Press |url=http://books.nips.cc/papers/files/nips14/CS01.pdf}}
12. ^{{cite journal |author=Smith, A., Li, M., Becker, S. and Kapur, S. |year=2006 |title=Dopamine, prediction error, and associative learning: a model-based account |journal=Network: Computation in Neural Systems |volume=17 |issue=1 |pages=61–84 |doi=10.1080/09548980500361624 |pmid=16613795}}
Bibliography
- {{cite journal |author=Sutton, R.S., Barto A.G. |year=1990 |title=Time Derivative Models of Pavlovian Reinforcement |journal=Learning and Computational Neuroscience: Foundations of Adaptive Networks |pages=497–537 |url=http://incompleteideas.net/sutton/papers/sutton-barto-90.pdf}}
- {{cite journal |author=Gerald Tesauro |title=Temporal Difference Learning and TD-Gammon |journal=Communications of the ACM |date=March 1995 |volume=38 |issue=3 |pages=58–68 |url=http://www.research.ibm.com/massive/tdl.html | doi = 10.1145/203330.203343}}
- Imran Ghory. Reinforcement Learning in Board Games.
- S. P. Meyn, 2007. [https://web.archive.org/web/20100619011046/https://netfiles.uiuc.edu/meyn/www/spm_files/CTCN/CTCN.html Control Techniques for Complex Networks], Cambridge University Press, 2007. See final chapter, and appendix with abridged [https://web.archive.org/web/20100619010320/https://netfiles.uiuc.edu/meyn/www/spm_files/book.html Meyn & Tweedie].
External links
- Scholarpedia Temporal difference Learning
- TD-Gammon
- TD-Networks Research Group
- Connect Four TDGravity Applet (+ mobile phone version) - self-learned using TD-Leaf method (combination of TD-Lambda with shallow tree search)
- Self Learning Meta-Tic-Tac-Toe Example web app showing how temporal difference learning can be used to learn state evaluation constants for a minimax AI playing a simple board game.
- [https://web.archive.org/web/20131116084228/http://www.cs.colorado.edu/~grudic/teaching/CSCI4202/RL.pdf Reinforcement Learning Problem], document explaining how temporal difference learning can be used to speed up Q-learning
- [https://www.cal-r.org/index.php?id=TD-sim TD-Simulator] Temporal difference simulator for classical conditioning
- Usuda Deep Space Center
- Usuda Station
- USU (disambiguation)
- USU Eastern Prehistoric Museum
- Usueni
- Usufructus
- Usui (disambiguation)
- Usui Kahoru
- Usui Kaoru
- Usui Mikao
- Usui Pass Railway Heritage Park
- Usui (surname)
- Usui Uonuma
- Usuki-shi
- Usuki Station (disambiguation)
- Usuki Station (Kagoshima)
- Usuki Station (Oita)
- Usuki Station (Ōita)
- Usuklyar
- US-UK Mutual Defence Agreement
- Usuk Obio Ediene
- US-UK relations
- Usul
- Usul al-hadith
- Usulatan