- Description
- Applications Optional stopping Publication bias Jeffreys–Lindley paradox
- See also
- References
In statistics, almost sure hypothesis testing or a.s. hypothesis testing utilizes almost sure convergence in order to determine the validity of a statistical hypothesis with probability one. This is to say that whenever the null hypothesis is true, then an a.s. hypothesis test will fail to reject the null hypothesis w.p. 1 for all sufficiently large samples. Similarly, whenever the alternative hypothesis is true, then an a.s. hypothesis test will reject the null hypothesis with probability one, for all sufficiently large samples. Along similar lines, an a.s. confidence interval eventually contains the parameter of interest with probability 1. Dembo and Peres (1994) proved the existence of almost sure hypothesis tests.
Description
For simplicity, assume we have a sequence of independent and identically distributed normal random variables,  , with mean
, with mean 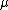 , and unit variance. Suppose that nature or simulation has chosen the true mean to be
, and unit variance. Suppose that nature or simulation has chosen the true mean to be  , then the probability distribution function of the mean, , is given by
, then the probability distribution function of the mean, , is given by

where an Iverson bracket has been used. A naïve approach to estimating this distribution function would be to replace true mean on the right hand side with an estimate such as the sample mean,  , but
, but

which means the approximation to the true distribution function will be off by 0.5 at the true mean. However,  is nothing more than a one-sided 50% confidence interval; more generally, let
is nothing more than a one-sided 50% confidence interval; more generally, let 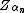 be the critical value used in a one-sided
be the critical value used in a one-sided  confidence interval, then
confidence interval, then

If we set 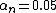 , then the error of the approximation is reduced from 0.5 to 0.05, which is a factor of 10. Of course, if we let
, then the error of the approximation is reduced from 0.5 to 0.05, which is a factor of 10. Of course, if we let  , then
, then

However, this only shows that the expectation is close to the limiting value. Naaman (2016) showed that setting the significance level at  with
with  results in a finite number of type I and type II errors w.p.1 under fairly mild regularity conditions. This means that for each
results in a finite number of type I and type II errors w.p.1 under fairly mild regularity conditions. This means that for each  , there exists an
, there exists an  , such that for all
, such that for all 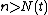 ,
,

where the equality holds w.p. 1. So the indicator function of a one-sided a.s. confidence interval is a good approximation to the true distribution function.
Applications
Optional stopping
For example, suppose a researcher performed an experiment with a sample size of 10 and found no statistically significant result. Then suppose she decided to add one more observation, and retest continuing this process until a significant result was found. Under this scenario, given the initial batch of 10 observations resulted in an insignificant result, the probability that the experiment will be stopped at some finite sample size,  , can be bounded using Boole's inequality
, can be bounded using Boole's inequality

where 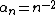 . This compares favorably with fixed significance level testing which has a finite stopping time with probability one; however, this bound will not be meaningful for all sequences of significance level, as the above sum can be greater than one (setting
. This compares favorably with fixed significance level testing which has a finite stopping time with probability one; however, this bound will not be meaningful for all sequences of significance level, as the above sum can be greater than one (setting  would be one example). But even using that bandwidth, if the testing was done in batches of 10, then
would be one example). But even using that bandwidth, if the testing was done in batches of 10, then

which results in a relatively large probability that the process will never end.
Publication bias
As another example of the power of this approach, if an academic journal only accepts papers with p-values less than 0.05, then roughly 1 in 20 independent studies of the same effect would find a significant result when there was none. However, if the journal required a minimum sample size of 100 and a maximum significance level is given by 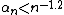 , then one would expect roughly 1 in 250 studies would find an effect when there was none (if the minimum sample size was 30, it would still be 1 in 60). If the maximum significance level was given by
, then one would expect roughly 1 in 250 studies would find an effect when there was none (if the minimum sample size was 30, it would still be 1 in 60). If the maximum significance level was given by  (which will have better small sample performance with regard to type I error when multiple comparisons are a concern), one would expect roughly 1 in 10000 studies would find an effect when there was none (if the minimum sample size was 30, it would be 1 in 900). Additionally, A.S. hypothesis testing is robust to the multiple comparisons.
(which will have better small sample performance with regard to type I error when multiple comparisons are a concern), one would expect roughly 1 in 10000 studies would find an effect when there was none (if the minimum sample size was 30, it would be 1 in 900). Additionally, A.S. hypothesis testing is robust to the multiple comparisons.
Jeffreys–Lindley paradox
Lindley's paradox occurs when
- The result is "significant" by a frequentist test, at, for example, the 5% level, indicating sufficient evidence to reject the null hypothesis, and
- The posterior probability of the null hypothesis is high, indicating strong evidence that the null hypothesis is in better agreement with the data than is the alternative hypothesis.
However, the paradox does not apply to a.s. hypothesis tests. The Bayesian and the frequentist will eventually reach the same conclusion.
See also
- Bayes factor
- Lindley's paradox
- Confidence interval
- Hypothesis testing
References
- {{cite journal
| last=Naaman |first=Michael
| title=Almost sure hypothesis testing and a resolution of the Jeffreys–Lindley paradox
| journal=Electronic Journal of Statistics
| volume=10 |issue=1| pages=1526–1550| year=2016
}}
- {{cite journal
| last1=Dembo |first1=Amir
| last2=Peres |first2=Yuval
| title=A topological criterion for hypothesis testing
| journal=The Annals of Statistics
| volume=22 |issue=1| pages=106–117| year=1994
}}
- Bishop Kearney High School (New York City)
- Bishop Kelley Catholic School
- Bishop Kelley School
- Bishop Kelly High School
- Bishop Kenny High School
- Bishop Keough Regional High School
- Bishop Kevin Vann
- Bishop Kinkell
- Bishop Lamont
- Bishop Landulf
- Bishop Laud
- Bishop LeBlond High School
- Bishop Len Brennan
- Bishop loughlin
- Bishop Loughlin Memorial High School
- Bishop Louglin
- Bishop Louglin Memorial High
- Bishop Louglin Memorial High School
- Bishop L. Robinson (police commissioner)
- Bishop Ludden Junior/Senior High School
- Bishop Luers Highschool
- Bishop Luers High School
- Bishop luffa
- Bishop Luffa CofE Comprehensive
- Bishop Luffa school