- Definition Formal definition
- References
- External links
}}
The decentralized partially observable Markov decision process (Dec-POMDP) [1][2] is a model for coordination and decision-making among multiple agents. It is a probabilistic model that can consider uncertainty in outcomes, sensors and communication (i.e., costly, delayed, noisy or nonexistent communication). it is a generalization of a Markov decision process (MDP) and a partially observable Markov decision process (POMDP) to consider multiple decentralized agents.
Definition
Formal definition
A Dec-POMDP is a 7-tuple 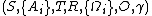 , where
, where
-
 is a set of states,
is a set of states, -
 is a set of actions for agent i, with
is a set of actions for agent i, with 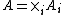 is the set of joint actions,
is the set of joint actions, -
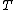 is a set of conditional transition probabilities between states,
is a set of conditional transition probabilities between states, 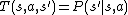 ,
, -
 is the reward function.
is the reward function. -
 is a set of observations for agent i, with
is a set of observations for agent i, with  is the set of joint observations,
is the set of joint observations, -
 is a set of conditional observation probabilities
is a set of conditional observation probabilities  , and
, and -
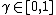 is the discount factor.
is the discount factor.
At each time step, each agent takes an action 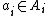 , the state updates based on the transition function
, the state updates based on the transition function  (using the current state and the joint action), each agent observes an observation based on the observation function
(using the current state and the joint action), each agent observes an observation based on the observation function 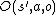 (using the next state and the joint action) and a reward is generated for the whole team based on the reward function
(using the next state and the joint action) and a reward is generated for the whole team based on the reward function 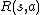 . The goal is to maximize expected cumulative reward over a finite or infinite number of steps. These time steps repeat until some given horizon (called finite horizon) or forever (called infinite horizon). The discount factor
. The goal is to maximize expected cumulative reward over a finite or infinite number of steps. These time steps repeat until some given horizon (called finite horizon) or forever (called infinite horizon). The discount factor  maintains a finite sum in the infinite-horizon case (
maintains a finite sum in the infinite-horizon case (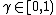 ).
).
References
2. ^{{Cite book|title=A Concise Introduction to Decentralized POMDPs {{!}} SpringerLink|last=Oliehoek|first=Frans A.|last2=Amato|first2=Christopher|language=en-gb|doi=10.1007/978-3-319-28929-8|series = SpringerBriefs in Intelligent Systems|year = 2016|isbn = 978-3-319-28927-4|url = http://www.fransoliehoek.net/docs/OliehoekAmato16book.pdf}}
External links
- maspan.org
- The Dec-POMDP page
- Model 1840 Heavy Cavalry Saber
- Model 1840 Heavy Cavalry Sabre
- Model 1840 Light Artilery Sabre
- Model 1840 Light Artillery Sabre
- Model 1840 NCO sword
- Model 1842 Musket
- Model 1850 Staff & Field Officer's Sword
- Model 1854 Lorenz rifle
- Model 1860 Light Cavalry Sabre
- Model 1885 Remington Lee Navy Rifle
- Model 1887
- Model 1888 Commission Rifle
- Model 1911
- Model 1914 grenade
- Model 1924/1929D machine gun
- Model 1968 recoilless gun
- Model 2500 telephone
- Model 299
- Model 30
- Model 30 Express
- Model 360
- Model 43
- Model 43 grenade
- Model 45
- Model 45A