- References
In this article, let’s take the latent utility model[1] as an example for the binary response model. The intuition of the latent utility model is that respondents will pick up the choice which will give the highest utility for her. Because the utility is not observable, it is assumed that the latent utility is linear with the some explanatory variables which affects the utility of the choice to the respondent and there is an additive response error capturing the randomness of the choice-making process. In this model, the choice is: 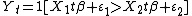 , where
, where 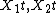 are two vectors of the explanatory covariates,
are two vectors of the explanatory covariates, 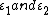 are i.i.d response errors,
are i.i.d response errors,
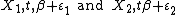
are latent utility of choosing choice 1 and 2. Then the log likelihood function can be given as:
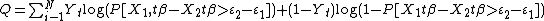
If some distributional assumption about the response error is imposed, then the log likelihood function will have specific close form representation.[2] For instance, if the response error is assumed to be distributed as: 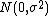 , then the likelihood function can be rewritten as:
, then the likelihood function can be rewritten as:
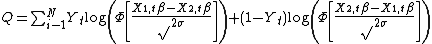
where  is the cumulative distribution function (CDF) for standard normal distribution. Here, even if doesn't have a closed form of representation, its derivative does. Therefore, maximum likelihood estimation can be explicitly computed by solving the first order condition. Alternatively, if the response error is assumed to be distributed as Gumbel
is the cumulative distribution function (CDF) for standard normal distribution. Here, even if doesn't have a closed form of representation, its derivative does. Therefore, maximum likelihood estimation can be explicitly computed by solving the first order condition. Alternatively, if the response error is assumed to be distributed as Gumbel 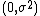 , then the log-likelihood function can be rewritten as:
, then the log-likelihood function can be rewritten as:
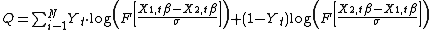
where F is the CDF for the standard logistic distribution, which has a closed form representation.
Both of the models above are based on the distribution assumption about the response error term. Adding specific distribution assumption into the model can make the model computationally tractable due to the existence of the closed form representation. But if the distribution of the error term is mis-sepcified, the estimates based on the distribution assumption will be inconsistent. To get more robust estimator, models which don’t depend on the distribution assumption can be used. The basic idea of the distribution-free model is to replace the two probability term in the log-likelihood function with other weights. The general form of the log-likelihood function can written as:
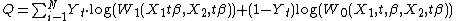
For instance, Manski (1975) proposed a discrete weighting scheme for multi-response model,[3] in the binary context which can be represented as:
where
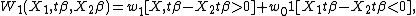
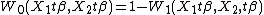
and 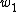 and
and  are two constants in (0,1). The intuition of this weighting scheme is that the probability of the choice depends on the relative order of the certainty part of the utility. Under the discrete weighting scheme, the estimator, which is also called Maximum Score Estimator, does not have very nice asymptotic property,[4] and Horowitz (1992)[5] proposed a smoothed weighting scheme, which can be represented as:
are two constants in (0,1). The intuition of this weighting scheme is that the probability of the choice depends on the relative order of the certainty part of the utility. Under the discrete weighting scheme, the estimator, which is also called Maximum Score Estimator, does not have very nice asymptotic property,[4] and Horowitz (1992)[5] proposed a smoothed weighting scheme, which can be represented as:
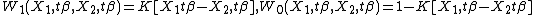
where the weight function K has to satisfy the following conditions:
(1) |K| is bounded over R;
(2) 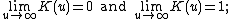
(3) 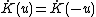
Here, the weight function is analogous to a cumulative distribution function but can be more general and flexible than the weight functions in the models based on specific distribution assumption. The estimator under this weighting scheme is also called Smoothed Maximum Score Estimator. Usually, it is more computationally tractable than the Maximum Score Estimator for its smoothness and it is also more robust than the estimator based on the distribution assumptions.
References
2. ^{{cite book |last=Wooldridge |first=J. |authorlink=Jeffrey Wooldridge |year=2002 |title=Econometric Analysis of Cross Section and Panel Data |publisher=MIT Press |location=Cambridge, Mass |pages=457–460 |isbn=978-0-262-23219-7 }}
3. ^{{cite journal |first=Charles F. |last=Manski |authorlink=Charles F. Manski |year=1975 |title=Maximum Score Estimation of the Stochastic Utility Model of Choice |journal=Journal of Econometrics |volume=3 |issue=3 |pages=205–228 |doi=10.1016/0304-4076(75)90032-9 |citeseerx=10.1.1.587.6474 }}
4. ^{{cite journal |first=Jeankyung |last=Kim |first2=David |last2=Pollard |year=1990 |title=Cube Root Asymptotics |journal=Annals of Statistics |volume=18 |issue=1 |pages=191–219 |jstor=2241541 |doi=10.1214/aos/1176347498 }}
5. ^{{cite journal |first=Joel L. |last=Horowitz |year=1992 |title=A Smoothed Maximum Score Estimator for the Binary Response Model |journal=Econometrica |volume=60 |issue=3 |pages=505–531 |doi=10.2307/2951582 |jstor=2951582 }}
- Armored Bulldozer
- Armored Car (film)
- Armored Command (film)
- Armored core 2 another age
- Armored Core (game series)
- Armored cruiser Georgios Averof (1910)
- Armored cruiser Georgios Averoff (1910)
- Armored dinosaur
- Armored Encounter!
- Armored Encounter
- Armored Encounter! - Subchase!
- Armored Encounter! – Subchase!
- Armored Fist
- Armored Fist 2
- Armored Fist (video game)
- Armored Forces Day (Ukraine)
- Armored military vehicle
- Armored spearhead
- Armored Train of the Foreign Legion
- Armored Warfare (video game)
- Armorel
- Armorel Public Schools
- Armorer, Nicholas
- Armorhead
- Armor Hero Buwang