- Abstract
- History RNN LSTM GRU
- Reversible Recurrent Neural Networks Architectures Exact Arithmetic (1) Reversible GRU (2) Reversible LSTM Finite Precision Arithmetic (1) No Forgetting (2) With Forgetting Algorithm Limitations Advantages
- Applications Machine Translation Language Modeling
- References
Abstract
RNNs(Recurrent Neural Networks)[1] perform outstandingly in processing sequential data. However, RNNs are memory-consuming, which limits the flexibility. Reversible RNNs offer a way to reduce the requirements of memory when being trained, in which the hidden-to-hidden transition can be reversed. In another words, hidden state[2] in reversible RNNs don't have to be recorded any more, being recomputed during backpropagation[3].
History
RNN
Recurrent Neural Network (RNN) is a recursive network which are mainly used to work on sequential data. RNNs not only consider the current input but also use previous inputs. RNNs have the ability to memorize previous inputs due to its internal memory[4]. The ability of "remember" enables RNNs to handle tasks such as handwriting recognition, speech recognition, next word prediction, music composition and image captioning[5].
LSTM
LSTM is a kind of RNN, whose full name is Long Short- Term Memory[6]. Structure of LSTM is more complicated than that of RNN. RNN memorize all the previous data, while LSTM remember some of them. The key to LSTMs is the cell state. LSTM have the ability to remove or add information to the cell state, carefully regulated by structures called gates[7].
GRU
The full name is Gated Recurrent Units. GRUs are a gating mechanism in RNNs. Their performance on some works (such as polyphonic music modeling and speech signal modeling) is similar to that of LSTM. While the structure of GRU is different from that of LSTM[8]. GRU has only 2 gates (update and reset); LSTM has 3 gates (forget, input and output). GRU directly pass the hidden state to next unit, while LSTM save them in memory cell.
Reversible Recurrent Neural Networks Architectures
The ways to construct RevNets can be combined with traditional RNN models to produce reversible RNNs.
Exact Arithmetic
(1) Reversible GRU
GRU equations are used to compute the next hidden state 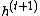 given the current hidden state
given the current hidden state 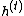 and the current input
and the current input  (omitting biases) [9]:
(omitting biases) [9]:

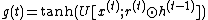

To make this update reversible, the hidden state  is separated into two groups,
is separated into two groups,  . These groups are updated with the following rules used[1]:
. These groups are updated with the following rules used[1]:
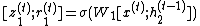

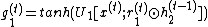
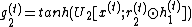
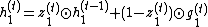

It means that the RevGRU updates are reversible in exact arithmetic: given  ,
,  and
and 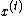 could be used to find
could be used to find 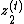 ,
,  , and
, and  by redoing part of forwards computation. Then
by redoing part of forwards computation. Then 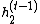 can be found by using [1]:
can be found by using [1]:
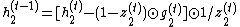
(2) Reversible LSTM
In LSTM, the hidden state is separated into two parts, output state h and cell state  . The update equations are[6]:
. The update equations are[6]:
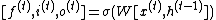
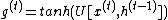
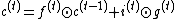

The reversible techniques mentioned before cannot straightforwardly be applied, as the update for  is a zero linear transformation of
is a zero linear transformation of  . Despite this, reversibility can be achieved using the equations[1]:
. Despite this, reversibility can be achieved using the equations[1]:
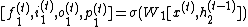


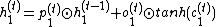
By using  and , The updates are calculated for
and , The updates are calculated for 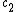 ,
,  in an identical fashion to the above equations. This model is called the Reversible LSTM, or RevLSTM in short.
in an identical fashion to the above equations. This model is called the Reversible LSTM, or RevLSTM in short.
By using and , The updates are calculated for  ,
,  in an identical fashion to the above equations. This model is called the Reversible LSTM, or RevLSTM in short.
in an identical fashion to the above equations. This model is called the Reversible LSTM, or RevLSTM in short.
Finite Precision Arithmetic
RNNs which are reversible in exact arithmetic have be defined before. In practice, the hidden states cannot be perfectly reconstructed due to finite numerical precision. Forgetting is the main roadblock to constructing perfectly reversible recurrent architectures. There are two possible avenues to address this limitation. First is the No Forgetting Model.
(1) No Forgetting
The first step is to remove the forgetting step. For the RevGRU, 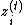 ,
,  ,
,  are computed before, and
are computed before, and  are updated by using[1]:
are updated by using[1]:

This model is termed the No-Forgetting RevGRU or NF-RevGRU. Because the updates of the NF-RevGRU do not discard information, only one hidden state is needed to be store in memory at a given time during training. Similar steps can be taken to define a NF-RevLSTM.
(2) With Forgetting
Reversible RNN in finite precision can be constructed under the assumption that no information is discarded[1]. Nevertheless, if none of the hidden state can be forgotten, then the hidden state at any given time step must contain enough information to reconstruct all previous hidden states[10]. Thus, any information stored in the hidden state at one time step must remain present at all future time steps to ensure exact reconstruction, overwhelming the storage capacity of the model, which indicates that reversible RNN with no-forgetting is not realistic[11].
The impossibility of zero forgetting leads to the second possibility to achieve reversibility: storing information lost from the hidden state during the forward computation, then restoring it in the reverse computation. Fractional forgetting is used, in which a fractional number of bits are allowed to be forgotten.
Algorithm
To allow forgetting of a fractional number of bits, reversible RNN uses a technique introduced by Dougal Maclaurin [18]. to store lost information. The full process of reversible multiplication is shown in detail in Algorithm 1[12].
The algorithm maintains an integer information buffer which stores  mod
mod  at each time step, so integer division of by is reversible. However, this requires enlarging the buffer by
at each time step, so integer division of by is reversible. However, this requires enlarging the buffer by  bits at each time step Dougal Maclaurin[12]. reduced this storage requirement by shifting information from the buffer back onto the hidden state. Reversibility is preserved if the shifted information is small enough so that it does not affect the reverse operation(integer division of by
bits at each time step Dougal Maclaurin[12]. reduced this storage requirement by shifting information from the buffer back onto the hidden state. Reversibility is preserved if the shifted information is small enough so that it does not affect the reverse operation(integer division of by 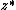 ).
).
At the same time, limiting the amount of information moved from the buffer[12] to the hidden state by setting smaller than  can decrease the noise caused by shifting information from buffer. When
can decrease the noise caused by shifting information from buffer. When 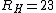 and
and  and
and  , it works well[1].
, it works well[1].
Limitations
The main disadvantage is the high computational cost. Because the reversible RNN needs to reconstruct hidden states during the backwards and manipulate the buffer at each time step which takes about 2-3 times as much computation as regular backpropagation[13][14][15].
Advantages
The mainly advantages compared to traditional RNN is that it reduces the memory requirements of truncated back propagation through time[16]. The main advantage compared to RNNs is that it reduces the memory requirements with roughly equivalent performance to standard models[1][17].
Applications
The ability of "remember" enables RNNs to handle tasks such as handwriting recognition, speech recognition, next word prediction, music composition and image captioning. But RNNs are memory-consuming, which limits RNNs flexibility. Reversible RNNs reduce the need the memory, which widen their usage.
Applications of Reversible Recurrent Neural Networks include:
Machine Translation
(1) New information can be used to generate the next hidden state, like recurrent neural networks, so that language model and translation model can be integrated naturally[18].
(2) A tree structure can be built, as recursive neural networks, so as to generate the translation candidates in a bottom up manner[18].
Language Modeling
References
2. ^{{Citation|title=Hidden Markov model|date=2018-12-07|url=https://en.wikipedia.org/w/index.php?title=Hidden_Markov_model&oldid=872390786|work=Wikipedia|language=en|access-date=2018-12-26}}
3. ^{{Citation|title=Backpropagation|date=2018-12-21|url=https://en.wikipedia.org/w/index.php?title=Backpropagation&oldid=874783441|work=Wikipedia|language=en|access-date=2018-12-26}}
4. ^{{cite arxiv|last=Pascanu|first=Razvan|last2=Gulcehre|first2=Caglar|last3=Cho|first3=Kyunghyun|last4=Bengio|first4=Yoshua|date=2013-12-20|title=How to Construct Deep Recurrent Neural Networks|eprint=1312.6026|class=cs.NE}}
5. ^{{cite arxiv|last=Zilly|first=Julian Georg|last2=Srivastava|first2=Rupesh Kumar|last3=Koutník|first3=Jan|last4=Schmidhuber|first4=Jürgen|date=2016-07-12|title=Recurrent Highway Networks|eprint=1607.03474|class=cs.LG}}
6. ^1 {{Cite journal|last=Sepp Hochreiter and Jürgen Schmidhuber|date=2001|title=Long Short-Term Memory: Tutorial on LSTM Recurrent Nets|url=|journal=Neural Computation|volume=9 (8):1735–1780, 1997|pages=|via=}}
7. ^{{cite arxiv|last=Stephen Merity, Nitish Shirish Keskar, Richard Socher|date=7 Aug 2017|title=Regularizing and Optimizing LSTM Language Models|volume=|pages=|eprint=1708.02182|class=cs.CL}}
8. ^{{cite arxiv|last=Junyoung Chung, Caglar Gulcehre, KyungHyun Cho.|date=11 Dec 2014|title=Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling|volume=|pages=|eprint=1412.3555|class=cs.NE}}
9. ^{{cite arxiv|last=Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio.|date=3 Sep 2014|title=Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation|volume=|pages=|eprint=1406.1078|class=cs.CL}}
10. ^{{Cite web|url=https://ieeexplore.ieee.org/document/818041|title=Learning to forget: continual prediction with LSTM - IET Conference Publication|website=ieeexplore.ieee.org|language=en-US|access-date=2018-12-26}}
11. ^{{Cite journal|last=Klaus Greff, Rupesh K Srivastava, Jan Koutník, Bas R Steunebrink, and Jürgen Schmidhuber.|title=LSTM: A Search Space Odyssey|journal=IEEE Transactions on Neural Networks and Learning Systems,28(10):2222–2232, 2017.|volume=28|issue=10|pages=2222–2232|arxiv=1503.04069|year=2015|doi=10.1109/TNNLS.2016.2582924|pmid=27411231}}
12. ^1 2 3 {{cite arxiv|last=Maclaurin|first=Dougal|last2=Duvenaud|first2=David|last3=Adams|first3=Ryan P.|date=2015-02-11|title=Gradient-based Hyperparameter Optimization through Reversible Learning|eprint=1502.03492|class=stat.ML}}
13. ^{{Cite web|url=https://ieeexplore.ieee.org/document/58337|title=Backpropagation through time: what it does and how to do it - IEEE Journals & Magazine|website=ieeexplore.ieee.org|language=en-US|access-date=2018-12-26}}
14. ^{{Cite journal|last=Williams|first=Ronald J.|last2=Hinton|first2=Geoffrey E.|last3=Rumelhart|first3=David E.|date=Oct 1986|title=Learning representations by back-propagating errors|url=https://www.nature.com/articles/323533a0|journal=Nature|language=en|volume=323|issue=6088|pages=533–536|doi=10.1038/323533a0|issn=1476-4687|via=|bibcode=1986Natur.323..533R}}
15. ^{{cite arxiv|last=Bengio|first=Yoshua|last2=Léonard|first2=Nicholas|last3=Courville|first3=Aaron|date=2013-08-15|title=Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation|eprint=1308.3432|class=cs.LG}}
16. ^{{cite arxiv|last=Bahdanau|first=Dzmitry|last2=Cho|first2=Kyunghyun|last3=Bengio|first3=Yoshua|date=2014-09-01|title=Neural Machine Translation by Jointly Learning to Align and Translate|eprint=1409.0473|class=cs.CL}}
17. ^{{cite arxiv|last=Wu|first=Yonghui|last2=Schuster|first2=Mike|last3=Chen|first3=Zhifeng|last4=Le|first4=Quoc V.|last5=Norouzi|first5=Mohammad|last6=Macherey|first6=Wolfgang|last7=Krikun|first7=Maxim|last8=Cao|first8=Yuan|last9=Gao|first9=Qin|date=2016-09-26|title=Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation|eprint=1609.08144|class=cs.CL}}
18. ^1 {{Cite web|url=https://www.semanticscholar.org/paper/A-Recursive-Recurrent-Neural-Network-for-Machine-Liu-Yang/5d43224147a5bb8b17b6a6fc77bf86490e86991a|title=A Recursive Recurrent Neural Network for Statistical Machine Translation|last=Zhou|first=Ming|last2=Li|first2=Mu|date=2014|website=undefined|language=en|access-date=2018-12-26|last3=Yang|first3=Nan|last4=Liu|first4=Shujie}}
- 1961–62 Mexican Primera División season
- 1961–62 MJHL season
- 1961–62 Montreal Canadiens season
- 1961–62 Nationalliga A
- 1961–62 Nemzeti Bajnoksag I
- 1961–62 Nemzeti Bajnokság I
- 1961–62 Newport County A.F.C. season
- 1961–62 New York Rangers season
- 1961–62 North Carolina Tar Heels men's basketball team
- 1961–62 Northern Rugby Football League season
- 1961–62 Norwegian Main League
- 1961–62 OHA season
- 1961–62 Ohio State Buckeyes men's basketball team
- 1961–62 Philadelphia Warriors season
- 1961–62 Portuguese Liga
- 1961–62 Port Vale FC season
- 1961–62 Port Vale F.C. season
- 1961–62 Port Vale season
- 1961–62 Primeira Divisão
- 1961–62 Scottish Football League
- 1961–62 Segunda Division
- 1961–62 Segunda División
- 1961–62 Serie B
- 1961–62 Serie C
- 1961–62 Slovenian Republic League