- Principle
- Formal explanations Notations Reproducibility and producibility Exhaustive history and complexity
- Algorithm
- Notes and references Bibliography Application
- External links
The Lempel-Ziv complexity was first presented in the article On the Complexity of Finite Sequences (IEEE Trans. On IT-22,1 1976), by two Israeli computer scientists, Abraham Lempel and Jacob Ziv. This complexity measure is related to Kolmogorov complexity, but the only function it uses is the recursive copy (i.e., the shallow copy).
The underlying mechanism in this complexity measure is the starting point for some algorithms for lossless data compression, like LZ77, LZ78 and LZW. Even though it is based on an elementary principle of words copying, this complexity measure is not too restrictive in the sense that it satisfies the main qualities expected by such a measure: sequences with a certain regularity do not have a too large complexity, and the complexity grows as the sequence grows in length and irregularity.
The Lempel-Ziv complexity can be used to measure the repetitiveness of binary sequences and text, like song lyrics or prose.
Principle
Let S be a binary sequence, of length n, for which we have to compute the Lempel-Ziv complexity, denoted C(S). The sequence is read from the left.
Imagine you have a delimiting line, which can be moved in the sequence during the calculation. At first, this line is set just after the first symbol, at the beginning of the sequence. This initial position is called position 1, from where we have to move it to a position 2, which is considered the initial position for the next step (and so on). We have to move the delimiter (starting in position 1) the further possible to the right, so that the sub-word between position 1 and the delimiter position be a word of the sequence that starts before the position 1 of the delimiter.
As soon as the delimiter is set on a position where this condition is not met, we stop, move the delimiter to this position, and start again by marking this position as a new initial position (i.e., position 1). Keep iterating until the end of the sequence. The Lempel-Ziv complexity corresponds to the number of iterations needed to finish this procedure.
Said differently, the Lempel-Ziv complexity is the number of different sub-strings (or sub-words) encountered as the binary sequence is viewed as a stream (from left to right).
Formal explanations
The method proposed by Lempel and Ziv uses three notions: reproducibility, producibility and exhaustive history of a sequence, that we defined here.
Notations
Let S be a binary sequence of length n (i.e., n symbols taking value 0 or 1). Let S(i,j), with On the one hand, a sequence S of length n is said to be reproducible from its prefix S(1,j) when S(j+1,n) is a sub-word of S(1,n-1). This is denoted S(1,j)→S. Said differently, S is reproducible from its prefix S(1,j) if the rest of the sequence, S(j+1,n), is nothing but a copy of another sub-word (starting at an index i < j+1) of S(1,n-1). To prove that the sequence S can be reproduced by one of its prefix S(1,j), you have to show that: On the other hand, the producibility, is defined from the reproducibility : a sequence S is producible from its prefix S(1,j) if S(1,n-1) is reproducible from S(1,j). This is denoted S(1,j)⇒S. Said differently, S(j+1,n-1) has to be a copy of another sub-word of S(1,n-2). The last symbol of S can be a new symbol (but could not be), possibly leading to the production of a new sub-word (hence the term producibility). From the definition of productibility, the empty string Λ=S(1,0) ⇒ S(1,1). So by a recursive production process, at step i we have S(1,hi) ⇒ S(1,hi+1), so we can build S from its prefixes. And as S(1,i) ⇒ S(1,i+1) (with hi+1 =hi + 1) is always true, this production process of S takes at most n=l(S) steps. Let m, A component of S, Hi(S), is said to be exhaustive if S(1,hi) is the longest sequence produced by S(1,hi-1) (i.e., S(1,hi-1) ⇒ S(1,hi)) but so that S(1,hi-1) does not produce S(1,hi) (denoted ). The history of S is said to be exhaustive if all its component are exhaustive, except possibly the last one. From the definition, one can show that any sequence S has only one exhaustive history, and this history is the one with the smallest number of component from all the possible histories of S. Finally, the number of component of this unique exhaustive history of S is called the Lempel-Ziv complexity of S. Hopefully, there exists a very efficient method for computing this complexity, in a linear number of operation ( A formal description of this method is given by the following algorithm: // S is a binary sequence of size n i := 0 C := 1 u := 1 v := 1 vmax := v while u + v <= n do end while if v != 1 then end si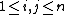 , be the sub-word of S from index i to index j (if j
, be the sub-word of S from index i to index j (if j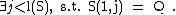
Reproducibility and producibility
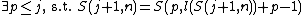
Exhaustive history and complexity
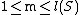 , be the number of steps necessary for this product process of S. S can be written in a decomposed form, called history of S, and denoted H(S), defined like this:
, be the number of steps necessary for this product process of S. S can be written in a decomposed form, called history of S, and denoted H(S), defined like this: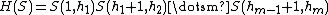
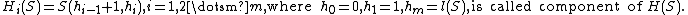
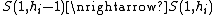 The index p which allows to have the longest production is called pointer.
The index p which allows to have the longest production is called pointer. Algorithm
 for
for 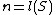 length of the sequence S).
length of the sequence S). if S[i + v] = S[u + v] then v := v + 1 else vmax := max(v, vmax) i := i + 1 if i = u then // all the pointers have been treated C := C + 1 u := u + vmax v := 1 i := 0 vmax := v else v := 1 end if end if
Notes and references
Bibliography
Application
External links
- Laser raditation
- Laser range-finder
- Laser Rangefinder
- Laser range scanners
- La Serrania
- La Serranía
- La Serre
- La Serre-Bussiere-Vieille
- La Serre-Bussière-Vieille
- La Serre (disambiguation)
- Laser Resurfacing
- Laser rod
- Laser Rods
- LASERS
- Lasers
- Laser (sailboat)
- Laser scanning confocal microscopy
- Laserscope
- Laser-shooting
- Laser shows
- LaserSoft Imaging
- Lasersoft Imaging AG
- Laser Spectroscopy
- Laser Speed
- Laser spray