- Basic model Sketch of derivation
- Examples
- See also
- References
- External links
Maximal entropy random walk (MERW) is a popular type of biased random walk on a graph, in which transition probabilities are chosen accordingly to the principle of maximum entropy, which says that the probability distribution which best represents the current state of knowledge is the one with largest entropy. While standard random walk chooses for every vertex uniform probability distribution among its outgoing edges, locally maximizing entropy rate, MERW maximizes it globally (average entropy production) by assuming uniform probability distribution among all paths in a given graph.
MERW is used in various fields of science. A direct application is choosing probabilities to maximize transmission rate through a constrained channel, analogously to Fibonacci coding. Its properties also made it useful for example in analysis of complex networks,[1] like link prediction,[2] community detection[3] and centrality measures.[4] Also in image analysis, for example for detecting visual saliency regions,[5] object localization,[6] tampering detection[7] or tractography problem.[8]
Additionally, it recreates some properties of quantum mechanics, suggesting a way to repair the discrepancy between diffusion models and quantum predictions, like Anderson localization.[9]
Basic model
Imagine there is a graph with  vertices, given by adjacency matrix
vertices, given by adjacency matrix  :
:  if there is an edge from vertex
if there is an edge from vertex 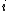 to
to  , 0 otherwise. For simplicity assume it is an undirected graph, what corresponds to symmetric
, 0 otherwise. For simplicity assume it is an undirected graph, what corresponds to symmetric  ; however, MERW can be also generalized for directed and weighted graphs (getting Boltzmann distribution among paths instead of uniform).
; however, MERW can be also generalized for directed and weighted graphs (getting Boltzmann distribution among paths instead of uniform).
We would like to choose a random walk as Markov process on this graph: for every vertex and its outgoing edge to , choose probability  of the walker randomly using this edge after visiting . Formally, find a stochastic matrix
of the walker randomly using this edge after visiting . Formally, find a stochastic matrix  such that
such that
-
 for all
for all  and
and -
 for all .
for all .
Assuming this graph is connected and not periodic, ergodic theory says that evolution of this stochastic process leads to some stationary probability distribution  such that
such that  .
.
Using Shannon entropy for every vertex and averaging over probability of visiting this vertex (to be able to use its entropy), we get the following formula for average entropy production (entropy rate) of a stochastic process:

This definition turns out to be equivalent with asymptotic average entropy (per length) of the probability distribution in the space of paths for this stochastic process.
In the standard random walk, referred here as generic random walk (GRW), we naturally choose that each outgoing edge is equally probable:
.
For a symmetric it leads to a stationary probability distribution with
.
It locally maximizes entropy production (uncertainty) for every vertex, but usually leads to a suboptimal averaged global entropy rate 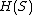 .
.
MERW chooses the stochastic matrix which maximizes , or equivalently assumes uniform probability distribution among all paths in a given graph. Its formula is obtained by first calculating the dominant eigenvalue  and corresponding eigenvector
and corresponding eigenvector  of the adjacency matrix, i.e. the largest
of the adjacency matrix, i.e. the largest  with corresponding
with corresponding  such that
such that  . Then stochastic matrix and stationary probability distribution are given by
. Then stochastic matrix and stationary probability distribution are given by
for which every possible path of length  from the -th to -th vertex has probability
from the -th to -th vertex has probability
.
Its entropy rate is  and the stationary probability distribution is
and the stationary probability distribution is
.
In contrast to GRW, the MERW transition probabilities generally depend on the structure of the entire graph (are nonlocal). Hence, they rather should not be imagined as directly applied by the walker – if randomly looking decisions are performed based on local situation, like a person would do, the GRW approach is rather more appropriate. MERW is based on the principle of maximum entropy, making it the safest assumption when we don't have any additional knowledge about the system. For example, it would be appropriate for modelling our knowledge about an object performing some complex dynamics – not necessarily random, like a particle.
Sketch of derivation
Assume for simplicity that the considered graph is indirected, connected and aperiodic, allowing to conclude from the Perron-Frobenius theorem that the dominant eigenvector is unique. Hence  can be asymptotically (
can be asymptotically ( ) approximated by
) approximated by  (or
(or  in bra-ket notation).
in bra-ket notation).
MERW requires uniform distribution along paths. The number  of paths with length
of paths with length  and vertex in the center is
and vertex in the center is
,
hence for all ,
.
Analogously calculating probability distribution for two succeeding vertices, one obtains that the probability of being at the -th vertex and next at the -th vertex is
.
Dividing by the probability of being at the -th vertex, i.e.  , gives for the conditional probability of the -th vertex being next after the -th vertex
, gives for the conditional probability of the -th vertex being next after the -th vertex
.
Examples
Let us first look at probably the simplest nontrivial situation: Fibonacci coding, where we want to transmit a message as a sequence of 0/1, but not using two successive 1s – after 1 there has to be used 0. To maximize the amount of information transmitted in such sequence, we should assume uniform probability distribution in the space of all possible sequences fulfilling this constraint. To practically use such long sequences, after 1 we have to use 0, but there remains a freedom of choosing the probability of 0 after 0. Let us denote this probability by  , then entropy coding would allow to encode a message using this chosen probability distribution. The stationary probability distribution of symbols for a given turns out to be
, then entropy coding would allow to encode a message using this chosen probability distribution. The stationary probability distribution of symbols for a given turns out to be  . Hence, entropy production is
. Hence, entropy production is  , which is maximized for
, which is maximized for  , known from golden ratio. In contrast, standard random walk would choose suboptimal
, known from golden ratio. In contrast, standard random walk would choose suboptimal  . While choosing larger reduces the amount of information produced after 0, it also reduces frequency of 1, after which we cannot write any information.
. While choosing larger reduces the amount of information produced after 0, it also reduces frequency of 1, after which we cannot write any information.
A more complex example is defected one-dimensional cyclic lattice: let say 1000 nodes connected in a ring, for which all nodes but the defects have self-loop (edge to itself). In standard random walk (GRW) the stationary probability distribution would have defect probability being 2/3 of probability of the remaining vertices – there is nearly no localization, also analogously for standard diffusion, which is infinitesimal limit of GRW. For MERW we have to first find the dominant eigenvector of the adjacency matrix – maximizing in:

for all positions  , where
, where  for defects, 0 otherwise. Substituting
for defects, 0 otherwise. Substituting  and multiplying the equation by −1 we get:
and multiplying the equation by −1 we get:

where  is minimized now, becoming the analog of energy. The formula inside the bracket is discrete Laplace operator, making this equation a discrete analogue of stationary Schrodinger equation. Like in quantum mechanics, MERW predicts that the probability distribution should lead exactly to the one of quantum ground state:
is minimized now, becoming the analog of energy. The formula inside the bracket is discrete Laplace operator, making this equation a discrete analogue of stationary Schrodinger equation. Like in quantum mechanics, MERW predicts that the probability distribution should lead exactly to the one of quantum ground state:  with its strongly localized density (in contrast to standard diffusion). Performing infinitesimal limit, we can get standard continuous stationary Schrodinger equation (
with its strongly localized density (in contrast to standard diffusion). Performing infinitesimal limit, we can get standard continuous stationary Schrodinger equation ( for
for  ) here.[10]
) here.[10]
See also
- Principle of maximum entropy
- Eigenvector centrality
- Markov chain
- Anderson localization
References
2. ^{{cite conference|last1=Li|first1=Rong-Hua|last2=Yu|first2=Jeffrey Xu|last3=Liu|first3=Jianquan|title=Link prediction: the power of maximal entropy random walk|year=2011|pages=1147|doi=10.1145/2063576.2063741|url=https://pdfs.semanticscholar.org/f185/bc2499be95b4312169a7e722bac570c2d509.pdf|conference=Association for Computing Machinery Conference on Information and Knowledge Management|conference-url=http://www.cikm2011.org/}}
3. ^{{cite journal|last1=Ochab|first1=J.K.|last2=Burda|first2=Z.|title=Maximal entropy random walk in community detection|journal=The European Physical Journal Special Topics|volume=216|issue=1|year=2013|pages=73–81|issn=1951-6355|doi=10.1140/epjst/e2013-01730-6}}
4. ^{{cite journal|last1=Delvenne|first1=Jean-Charles|last2=Libert|first2=Anne-Sophie|title=Centrality measures and thermodynamic formalism for complex networks|journal=Physical Review E|volume=83|issue=4|year=2011|issn=1539-3755|doi=10.1103/PhysRevE.83.046117}}
5. ^J.G. Yu, J. Zhao, J. Tian, Y. Tan, Maximal entropy random walk for region-based visual saliency, IEEE Transactions on Cybernetics, 2014.
6. ^L. Wang, J. Zhao, X. Hu, J. Lu, Weakly supervised object localization via maximal entropy random walk, ICIP, 2014.
7. ^P. Korus, J. Huang, Improved Tampering Localization in Digital Image Forensics Based on Maximal Entropy Random Walk, IEEE Signal Processing Letters, 2016.
8. ^V.L. Galinsky, L.R. Frank, Simultaneous multi-scale diffusion estimation and tractography guided by entropy spectrum pathways, IEEE Transactions on Medical Imaging, 2015.
9. ^Z. Burda, J. Duda, J. M. Luck, and B. Waclaw, Localization of the Maximal Entropy Random Walk, Phys. Rev. Lett., 2009.
10. ^J. Duda, Extended Maximal Entropy Random Walk, PhD Thesis, 2012.
External links
- Gábor Simonyi, Y. Lin, Z. Zhang, "Mean first-passage time for maximal-entropy random walks in complex networks". Scientific Reports, 2014.
- Electron Conductance Models Using Maximal Entropy Random Walks Wolfram Demonstration Project
- Edwardsina
- Edwardsina gigantea
- Edwardsina tasmaniensis
- Edward Sinclair
- Edward Sittler
- Edward Sittler, Jr.
- Edward Sizzerhand
- Edwards, John
- Edwards, Jonathan
- Edwards, Jonathon
- Edward S. Jordan
- Edward Skinner King
- Edward S. Lacey
- Edward S. Lampert
- Edward Slattery
- Edward S. Livermore
- Edward Sloman
- Edward Sloman Minor
- Edwards Long-clawed Mouse
- Edward Slota
- Edward Slovik
- Edward S. Marcus High School
- Edward's massasauga
- Edward S. Minor
- Edwards, Missouri