local p = {}
local mRedirect = require('Module:Redirect')
-- Get a redirect target (or nil if not a redirect) without using the expensive title object property .isRedirectlocal function getRedirectTarget(titleObject)
local content = titleObject:getContent()
if not content then return nil end
return mRedirect.getTargetFromText(content)
end
local errors
-- Return blank text, or an error message if requestedlocal function err(text)
if errors then error(text, 2) end
return ""
end
-- In text, match pre..list[1]..post or pre..list[2]..post or ...local function matchany(text, pre, list, post)
local match
for i = 1, #list do
match = mw.ustring.match(text, pre .. list[i] .. post)
if match then return match end
end
return nil
end
-- Initialise this big table once to save timelocal unwantedTemplates = {"[Ee]fn", "[Ee]fn%-[lu][arg]", "[Ee]l[mn]", "[Rr]p?", "[Ss]fn[bmp]", "[Ss]f[bn]", "NoteTag", "#[Tt]ag:%s*[Rr]ef", "[Rr]efn?",
"[CcDd]n", "[Cc]itation[%- _]needed", "[Dd]isambiguation needed", "[Ff]eatured article", "[Gg]ood article",
"[Dd]ISPLAYTITLE", "[Ss]hort[ _]+description", "[Cc]itation", "[Cc]ite[%- _]+[%w_%s]-", "[Cc]oor[%w_%s]-",
"[Uu]?n?[Rr]eliable source[%?%w_%s]-", "[Rr]s%??", "[Vv]c", "[Vv]erify credibility", "[Bb]y[ _]*[Ww]ho[m]*%??", "[Ww]ikisource[ -_]*multi", "[Ii]nflation[ _/-]*[Ff]n",
"[Bb]iblesource",
-- aliases for Clarification needed
"[Cc]f[ny]", "[Cc]larification[ _]+inline", "[Cc]larification[%- _]*needed", "[Cc]larification", "[Cc]larify%-inline", "[Cc]larify%-?me",
"[Cc]larify[ _]+inline", "[Cc]larify", "[Cc]LARIFY", "[Cc]onfusing%-inline", "[Cc]onfusing%-short", "[Ee]xplainme", "[Hh]uh[ _]*%??", "[Ww]hat%?",
"[Ii]nline[ _]+[Uu]nclear", "[Ii]n[ _]+what[ _]+sense", "[Oo]bscure", "[Pp]lease[ _]+clarify", "[Uu]nclear[ _]+inline", "[Ww]hat's[ _]+this%?",
"[Gg]eoQuelle", "[Nn]eed[s]+[%- _]+[Ii][Pp][Aa]", "[Ii]PA needed",
-- aliases for Clarification needed lead
"[Cc]itation needed %(?lea?de?%)?", "[Cc]nl", "[Ff]act %(?lea?de?%)?", "[Ll]ead citation needed", "[Nn]ot in body", "[Nn]ot verified in body",
-- Primary source etc.
"[Pp]s[ci]", "[Nn]psn", "[Nn]on%-primary[ _]+source[ _]+needed", "[Ss]elf%-published[%w_%s]-", "[Uu]ser%-generated[%w_%s]-",
"[Pp]rimary source[%w_%s]-", "[Ss]econdary source[%w_%s]-", "[Tt]ertiary source[%w_%s]-", "[Tt]hird%-party[%w_%s]-",
-- aliases for Disambiguation (page) and similar
"[Bb]egriffsklärung", "[Dd][Aa][Bb]", "[Dd]big", "[%w_%s]-%f[%w][Dd]isam[%w_%s]-", "[Hh][Nn][Dd][Ii][Ss]",
-- aliases for Failed verification
"[Bb]adref", "[Ff]aile?[ds] ?[rv][%w_%s]-", "[Ff][Vv]", "[Nn][Ii]?[Cc][Gg]", "[Nn]ot ?in ?[crs][%w_%s]-", "[Nn]ot specifically in source",
"[Vv]erification[%- _]failed",
-- aliases for When
"[Aa]s[ _]+of[ _]+when%??", "[Aa]s[ _%-]+of%??", "[Cc]larify date", "[Dd]ate[ _]*needed", "[Nn]eeds?[ _]+date", "[Rr]ecently", "[Ss]ince[ _]+when%??",
"[Ww]HEN", "[Ww]hen%??",
-- aliases for Update
"[Nn]ot[ _]*up[ _]*to[ _]*date","[Oo]u?[Tt][Dd]","[Oo]ut[%- _]*o?f?[%- _]*dated?", "[Uu]pdate", "[Uu]pdate[ _]+sect", "[Uu]pdate[ _]+Watch",
-- aliases for Pronunciation needed
"[Pp]ronunciation%??[%- _]*n?e?e?d?e?d?", "[Pp]ronounce", "[Rr]equested[%- _]*pronunciation", "[Rr]e?q?pron", "[Nn]eeds[%- _]*pronunciation",
-- Chart, including Chart/start etc.
"[Cc]hart", "[Cc]hart/[%w_%s]-",
-- Cref and others
"[Cc]ref2?", "[Cc]note",
-- Explain and others
"[Ee]xplain", "[Ff]urther*explanation*needed", "[Ee]laboration*needed", "[Ee]xplanation*needed",
-- TOC templates
"[Cc][Oo][Mm][Pp][Aa][Cc][Tt][ _]*[Tt][Oo][Cc][8]*[5]*", "[Tt][Oo][Cc]", "09[Aa][Zz]", "[Tt][Oo][Cc]*[Cc][Oo][Mm][Pp][Aa][Cc][Tt]", "[Tt][Oo][Cc]*[Ss][Mm][Aa][Ll][Ll]", "[Cc][Oo][Mm][Pp][Aa][Cc][Tt][ _]*[Aa][Ll][Pp][Hh][Aa][Bb][Ee][Tt][Ii][Cc][ _]*[Tt][Oo][Cc]",
"DEFAULTSORT:.-"
}
-- Help gsub to remove unwanted templates and pseudo-templates such as #tag:ref and DEFAULTSORTlocal function striptemplate(t)
-- If template is unwanted then return "" (gsub will replace by nothing), else return nil (gsub will keep existing string)
if matchany(t, "^{{%s*", unwantedTemplates, "%s*%f[|}]") then return "" end
-- If template is wanted but produces an unwanted reference then return the string with |shortref or |ref removed
local noref = mw.ustring.gsub(t, "|%s*shortref%s*%f[|}]", "")
noref = mw.ustring.gsub(noref, "|%s*ref%s*%f[|}]", "")
-- If a wanted template has unwanted nested templates, purge them too
noref = mw.ustring.sub(noref, 1, 2) .. mw.ustring.gsub(mw.ustring.sub(noref, 3), "%b{}", striptemplate)
-- Replace {{audio}} by its text parameter: {{Audio|Foo.ogg|Bar}} → Bar
noref = mw.ustring.gsub(noref, "^{{%s*[Aa]udio.-|.-|(.-)%f[|}].*", "%1")
-- Replace {{Nihongo foot}} by its text parameter: {{Nihongo foot|English|英語|eigo}} → English
noref = mw.ustring.gsub(noref, "^{{%s*[Nn]ihongo[ _]+foot%s*|(.-)%f[|}].*", "%1")
if noref ~= t then return noref end
return nil -- not an unwanted template: keep
end
-- Get a page's content, following redirects, and processing file description pages for files.-- Also returns the page name, or the target page name if a redirect was followed, or false if no page foundlocal function getContent(page, frame)
local title = mw.title.new(page) -- Read description page (for :File:Foo rather than File:Foo)
if not title then return false, false end
local redir = getRedirectTarget(title)
if redir then title = mw.title.new(redir) end
return title:getContent(), redir or title.prefixedText
end
-- Check image for suitabilitylocal function checkimage(image)
local page = matchany(image, "", {"[Ff]ile", "[Ii]mage"}, "%s*:[^|%]]*") -- match File:(name) or Image:(name)
if not page then return false end
-- Limit to image types: .gif, .jpg, .jpeg, .png, .svg, .tiff, .xcf (exclude .ogg audio etc.)
if not matchany(page, "%.", {"[Gg][Ii][Ff]", "[Jj][Pp][Ee]?[Gg]", "[Pp][Nn][Gg]", "[Ss][Vv][Gg]", "[Tt][Ii][Ff][Ff]", "[Xx][Cc][Ff]"}, "%s*$") then
return false
end
local desc, rtitle = getContent(page) -- get file description and title after following any redirect
if desc and desc ~= "" then -- found description on local wiki
if mw.ustring.match(desc, "[Nn]on%-free") then return false end
desc = mw.ustring.gsub(desc, "%b{}", striptemplate) -- remove DEFAULTSORT etc. to avoid side effects of frame:preprocess
elseif not rtitle then
return false
else
-- try commons
desc = "{{" .. rtitle .. "}}"
end
frame = frame or mw.getCurrentFrame()
desc = frame:preprocess(desc)
return ( desc and desc ~= "" and not mw.ustring.match(desc, "[Nn]on%-free") ) and true or false -- hide non-free image
end
-- Attempt to parse or , either anywhere (start=false) or at the start only (start=true)local function parseimage(text, start)
local startre = ""
if start then startre = "^" end -- a true flag restricts search to start of string
local image = matchany(text, startre .. "%[%[%s*", {"[Ff]ile", "[Ii]mage"}, "%s*:.*") -- [[File: or [[Image: ...
if image then
image = mw.ustring.match(image, "%b[]%s*") -- matching ... to handle wikilinks nested in caption
end
return image
end
-- Parse a caption, which ends at a | (end of parameter) or } (end of infobox) but may contain nested [..] and {..}local function parsecaption(caption)
if not caption then return nil end
local len = mw.ustring.len(caption)
local pos = 1
while pos <= len do
local linkstart, linkend = mw.ustring.find(caption, "%b[]", pos)
linkstart = linkstart or len + 1 -- avoid comparison with nil when no link
local templatestart, templateend = mw.ustring.find(caption, "%b{}", pos)
templatestart = templatestart or len + 1 -- avoid comparison with nil when no template
local argend = mw.ustring.find(caption, "[|}]", pos) or len + 1
if linkstart < templatestart and linkstart < argend then
pos = linkend + 1 -- skip wikilink
elseif templatestart < argend then
pos = templateend + 1 -- skip template
else -- argument ends before the next wikilink or template
return mw.ustring.sub(caption, 1, argend - 1)
end
end
end
-- Attempt to construct a block from {{infobox ... |image= ...}}local function argimage(text)
local token = nil
local hasNamedArgs = mw.ustring.find(text, "|") and mw.ustring.find(text, "=")
if not hasNamedArgs then return nil end -- filter out any template that obviously doesn't contain an image
-- ensure image map is captured
text = mw.ustring.gsub(text, '', '|imagemap=')
-- find all images
local hasImages = false
local images = {}
local capture_from = 1
while capture_from < mw.ustring.len(text) do
local argname, position, image = mw.ustring.match(text, "|%s*([^=|]-[Ii][Mm][Aa][Gg][Ee][^=|]-)%s*=%s*()(.*)", capture_from)
if image then -- ImageCaption=, image_size=, image_upright=, etc. do not introduce an image
local lcArgname = mw.ustring.lower(argname)
if mw.ustring.find(lcArgname, "caption")
or mw.ustring.find(lcArgname, "size")
or mw.ustring.find(lcArgname, "upright") then
image = nil
end
end
if image then
hasImages = true
images[position] = image
capture_from = position
else
capture_from = mw.ustring.len(text)
end
end
capture_from = 1
while capture_from < mw.ustring.len(text) do
local position, image = mw.ustring.match(text, "|%s*[^=|]-[Pp][Hh][Oo][Tt][Oo][^=|]-%s*=%s*()(.*)", capture_from)
if image then
hasImages = true
images[position] = image
capture_from = position
else
capture_from = mw.ustring.len(text)
end
end
capture_from = 1
while capture_from < mw.ustring.len(text) do
local position, image = mw.ustring.match(text, "|%s*[^=|{}]-%s*=%s*()%[?%[?([^|{}]*%.%a%a%a%a?)%s*%f[|}]", capture_from)
if image then
hasImages = true
if not images[position] then
images[position] = image
end
capture_from = position
else
capture_from = mw.ustring.len(text)
end
end
if not hasImages then return nil end
-- find all captions
local captions = {}
capture_from = 1
while capture_from < mw.ustring.len(text) do
local position, caption = mw.ustring.match(text, "|%s*[^=|]*[Cc][Aa][Pp][Tt][Ii][Oo][Nn][^=|]*%s*=%s*()([^\]+)", capture_from)
if caption then
-- extend caption to parse "| caption = Foo {{Template\ on\ multiple lines}} Bar\"
local bracedCaption = mw.ustring.match(text, "^[^\]-%b{}[^\]+", position);
if bracedCaption and bracedCaption ~= "" then caption = bracedCaption end
caption = mw.text.trim(caption)
local captionStart = mw.ustring.sub(caption, 1, 1)
if captionStart == '|' or captionStart == '}' then caption = nil end
end
if caption then
-- find nearest image, and use same index for captions table
local i = position
while i > 0 and not images[i] do
i = i - 1
if images[i] then
if not captions[i] then
captions[i] = parsecaption(caption)
end
end
end
capture_from = position
else
capture_from = mw.ustring.len(text)
end
end
-- find all alt text
local altTexts = {}
for position, altText in mw.ustring.gmatch(text, "|%s*[Aa][Ll][Tt]%s*=%s*()([^\]*)") do
if altText then
-- altText is terminated by }} or |, but first skip any matched ... and {{...}}
local lookfrom = math.max( -- find position after whichever comes last: start of string, end of last ]] or end of last }}
mw.ustring.match(altText, ".*{%b{}}()") or 1, -- if multiple {{...}}, .* consumes all but one, leaving the last for %b
mw.ustring.match(altText, ".*%[%b[]%]()") or 1)
local len = mw.ustring.len(altText)
local aftertext = math.min( -- find position after whichever comes first: end of string, }} or |
mw.ustring.match(altText, "()}}", lookfrom) or len+1,
mw.ustring.match(altText, "()|", lookfrom) or len+1)
altText = mw.ustring.sub(altText, 1, aftertext-1) -- chop off |... or }}... which is not part of ... or {{...}}
altText = mw.text.trim(altText)
local altTextStart = mw.ustring.sub(altText, 1, 1)
if altTextStart == '|' or altTextStart == '}' then altText = nil end
end
if altText then
-- find nearest image, and use same index for altTexts table
local i = position
while i > 0 and not images[i] do
i = i - 1
if images[i] then
if not altTexts[i] then
altTexts[i] = altText
end
end
end
end
end
-- find all image sizes
local imageSizes = {}
for position, imageSizeMatch in mw.ustring.gmatch(text, "|%s*[Ii][Mm][Aa][Gg][Ee][ _]?[Ss][Ii][Zz][Ee]%s*=%s*()([^}|\]*)") do
local imageSize = mw.ustring.match(imageSizeMatch, "=%s*([^}|\]*)")
if imageSize then
imageSize = mw.text.trim(imageSize )
local imageSizeStart = mw.ustring.sub(imageSize, 1, 1)
if imageSizeStart == '|' or imageSizeStart == '}' then imageSize = nil end
end
if imageSize then
-- find nearest image, and use same index for imageSizes table
local i = position
while i > 0 and not images[i] do
i = i - 1
if images[i] then
if not imageSizes[i] then
imageSizes[i] = imageSize
end
end
end
end
end
-- sort the keys of the images table (in a table sequence), so that images can be iterated over in order
local keys = {}
for key, val in pairs(images) do
table.insert(keys, key)
end
table.sort(keys)
-- add in relevant optional parameters for each image: caption, alt text and image size
local imageTokens = {}
for _, index in ipairs(keys) do
local image = images[index]
local token = parseimage(image, true) -- look for image= etc.
if not token then
image = mw.ustring.match(image, "^[^}|\]*") -- remove later arguments
token = "[[" -- Add File: unless name already begins File: or Image:
if not matchany(image, "^", {"[Ff]ile", "[Ii]mage"}, "%s*:") then
token = token .. "File:"
end
token = token .. image
local caption = captions[index]
if caption and mw.ustring.match(caption, "%S") then token = token .. "|" .. caption end
local alt = altTexts[index]
if alt then token = token .. "|alt=" .. alt end
local image_size = imageSizes[index]
if image_size and mw.ustring.match(image_size, "%S") then token = token .. "|" .. image_size end
token = token .. "]]"
end
token = mw.ustring.gsub(token, "\","") .. "\"
table.insert(imageTokens, token)
end
return imageTokens
end
-- Help gsub convert imagemaps into standard imageslocal function convertImagemap(imagemap)
local image = matchany(imagemap, "[>\]%s*", {"[Ii]mage:", "[Ff]ile:"}, "[^\]*")
if image then
return "\]%s*", "", 1) .. "">" .. mw.ustring.gsub(image, "[>\]%s*", "", 1) .. ""
else
return "" -- remove entire block if image can't be extracted
end
end
-- Convert a comma-separated list of numbers or min-max ranges into a list of booleans, e.g. "1,3-5" → {1=true,2=false,3=true,4=true,5=true}local function numberflags(str)
local ranges = mw.text.split(str, ",") -- parse ranges, e.g. "1,3-5" → {"1","3-5"}
local flags = {}
for _, r in pairs(ranges) do
local min, max = mw.ustring.match(r, "^%s*(%d+)%s*%-%s*(%d+)%s*$") -- "3-5" → min=3 max=5
if not max then min, max = mw.ustring.match(r, "^%s*((%d+))%s*$") end -- "1" → min=1 max=1
if max then
for p = min, max do flags[p] = true end
end
end
return flags
end
-- a basic parser to trim down extracted wikitext-- @param text : Wikitext to be processed-- @param options : A table of options...-- options.paraflags : Which number paragraphs to keep, as either a string (e.g. `1,3-5`) or a table (e.g. `{1=true,2=false,3=true,4=true,5=true}`. If not present, all paragraphs will be kept.-- options.fileflags : table of which files to keep, as either a string (e.g. `1,3-5`) or a table (e.g. `{1=true,2=false,3=true,4=true,5=true}`-- options.fileargs : args for the syntax, such as `left`-- @param filesOnly : If set, only return the files and not the proselocal function parse(text, options, filesOnly)
local allparas = true -- keep all paragraphs?
if options.paraflags then
if type(options.paraflags) ~= "table" then options.paraflags = numberflags(options.paraflags) end
for _, v in pairs(options.paraflags) do
if v then allparas = false end -- if any para specifically requested, don't keep all
end
end
if filesOnly then
allparas = false
options.paraflags = {}
end
local maxfile = 0 -- for efficiency, stop checking images after this many have been found
if options.fileflags then
if type(options.fileflags) ~= "table" then options.fileflags = numberflags(options.fileflags) end
for k, v in pairs(options.fileflags) do
if v and k > maxfile then maxfile = k end -- set maxfile = highest key in fileflags
end
end
local fileargs = options.fileargs and mw.text.trim(options.fileargs)
if fileargs == then fileargs = nil end
local leadstart = nil -- have we found some text yet?
local t = "" -- the stripped down output text
local filetext = "" -- output text with concatenated \ entries
local files = 0 -- how many images so far
local paras = 0 -- how many paragraphs so far
local startLine = true -- at the start of a line (no non-spaces found since last \)?
text = mw.ustring.gsub(text,"^%s*","") -- remove initial white space
repeat -- loop around parsing a template, image or paragraph
local token = mw.ustring.match(text, "^%b{}%s*") or false -- {{Template}}
if not leadstart and not token then token = mw.ustring.match(text, "^%b<>%s*%b{}%s*") end -- allow
local line = mw.ustring.match(text, "[^\]*")
if token and line and mw.ustring.len(token) < mw.ustring.len(line) then -- template is followed by text (but it may just be other templates)
line = mw.ustring.gsub(line, "%b{}", "") -- remove all templates from this line
line = mw.ustring.gsub(line, "%b<>", "") -- remove all HTML tags from this line
-- if anything is left, other than an incomplete further template or an image, keep the template: it counts as part of the line
if mw.ustring.find(line, "%S") and not matchany(line, "^%s*", { "{{", "%[%[%s*[Ff]ile:", "%[%[%s*[Ii]mage:" }, "") then
token = nil
end
end
if token then -- found a template which is not the prefix to a line of text
if leadstart then -- lead has already started, so keep the template within the text, unless it's a whole line (navbox etc.)
if not filesOnly and not startLine then t = t .. token end
elseif files < maxfile then -- discard template, but if we are still collecting images...
local images = argimage(token) or {}
if not images then
local image = parseimage(token, false) -- look for embedded , |image=, etc.
if image then table.insert(images, image) end
end
for _, image in ipairs(images) do
if files < maxfile and checkimage(image) then -- if image is found and qualifies (not a sound file, non-free, etc.)
files = files + 1 -- count the file, whether displaying it or not
if options.fileflags and options.fileflags[files] then -- if displaying this image
image = mw.ustring.gsub(image, "|%s*frameless%s*%f[|%]]", "") -- make image a thumbnail, not frameless etc.
image = mw.ustring.gsub(image, "|%s*framed?%s*%f[|%]]", "")
if not matchany(image, "|%s*", {"thumb", "thumbnail"}, "%s*%f[|%]]") then
image = mw.ustring.gsub(image, "(%]%]%s*)$", "|thumb%1")
end
if fileargs then image = mw.ustring.gsub(image, "(%]%]%s*)$", "|" .. fileargs .. "%1") end
filetext = filetext .. image
end
end
end
end
else -- the next token in text is not a template
token = parseimage(text, true)
if token then -- the next token in text looks like an image
if files < maxfile and checkimage(token) then -- if more images are wanted and this is a wanted image
files = files + 1
if options.fileflags and options.fileflags[files] then
local image = token -- copy token for manipulation by adding |right etc. without changing the original
if fileargs then image = mw.ustring.gsub(image, "(%]%]%s*)$", "|" .. fileargs .. "%1") end
filetext = filetext .. image
end
end
else -- got a paragraph, which ends at a file, image, blank line or end of text
local afterend = mw.ustring.len(text) + 1
local blankpos = mw.ustring.find(text, "\%s*\") or afterend -- position of next paragraph delimiter (or end of text)
local endpos = math.min( -- find position of whichever comes first: [[File:, [[Image: or paragraph delimiter
mw.ustring.find(text, "%[%[%s*[Ff]ile%s*:") or afterend,
mw.ustring.find(text, "%[%[%s*[Ii]mage%s*:") or afterend,
blankpos)
token = mw.ustring.sub(text, 1, endpos-1)
if blankpos < afterend and blankpos == endpos then -- paragraph ends with a blank line
token = token .. mw.ustring.match(text, "\%s*\", blankpos)
end
local isHatnote = not(leadstart) and mw.ustring.sub(token, 1, 1) == ':'
if not isHatnote then
leadstart = leadstart or mw.ustring.len(t) + 1 -- we got a paragraph, so mark the start of the lead section
paras = paras + 1
if allparas or (options.paraflags and options.paraflags[paras]) then t = t .. token end -- add if this paragraph wanted
end
end -- of "else got a paragraph"
end -- of "else not a template"
if token then text = mw.ustring.sub(text, mw.ustring.len(token)+1) end -- remove parsed token from remaining text
startLine = mw.ustring.find(token, "\%s*$"); -- will the next token be the first non-space on a line?
until not text or text == "" or not token or token == "" -- loop until all text parsed
text = mw.ustring.gsub(t, "\+$", "") -- remove trailing line feeds, so "{{Transclude text excerpt|Foo}} more" flows on one line
return filetext, text
end
local function cleanupText(text, leadOnly)
text = mw.ustring.gsub(text, "","") -- remove HTML comments
if leadOnly then
text = mw.ustring.gsub(text, "\==.*","") -- remove first ==Heading== and everything after it
text = mw.ustring.gsub(text, "^==.*","") -- ...even if it's the start of the article (blank lead)
end
text = mw.ustring.gsub(text, "<[Nn][Oo][Ii][Nn][Cc][Ll][Uu][Dd][Ee]>.-", "") -- remove noinclude bits
text = mw.ustring.gsub(text, "<%s*[Rr][Ee][Ff][^>]-/%s*>", "") -- remove refs cited elsewhere
text = mw.ustring.gsub(text, "<%s*[Rr][Ee][Ff].->.-<%s*/%s*[Rr][Ee][Ff]%s*>", "") -- remove refs
text = mw.ustring.gsub(text, "<%s*[Ss][Cc][Oo][Rr][Ee].->.-<%s*/%s*[Ss][Cc][Oo][Rr][Ee]%s*>", "") -- remove musical scores
text = mw.ustring.gsub(text, "<%s*[Ii][Mm][Aa][Gg][Ee][Mm][Aa][Pp].->.-<%s*/%s*[Ii][Mm][Aa][Gg][Ee][Mm][Aa][Pp]%s*>", convertImagemap) -- convert imagemaps into standard images
text = mw.ustring.gsub(text, "%b{}", striptemplate) -- remove unwanted templates such as references
text = mw.ustring.gsub(text, "%s*{{%s*[Tt][Oo][Cc].-}}", "") -- remove most common tables of contents
text = mw.ustring.gsub(text, "%s*__[A-Z]*TOC__", "") -- remove TOC behavior switches
text = mw.ustring.gsub(text, "\%s*{{%s*[Pp]p%-.-}}", "\") -- remove protection templates
text = mw.ustring.gsub(text, "%s*{{[^{|}]*[Ss]idebar%s*}}", "") -- remove most sidebars
text = mw.ustring.gsub(text, "%s*{{[^{|}]*%-[Ss]tub%s*}}", "") -- remove most stub templates
text = mw.ustring.gsub(text, "%s*%[%[%s*:?[Cc]ategory:.-%]%]", "") -- remove categories
text = mw.ustring.gsub(text, "^:[^\]+\","") -- remove DIY hatnote indented with a colon
return text
end
-- Parse a ==Section== from a pagelocal function getsection(text, section, mainonly)
local escapedSection = mw.ustring.gsub(mw.uri.decode(section), "([%^%$%(%)%%%.%[%]%*%+%-%?])", "%%%1") -- %26 → & etc, then ^ → %^ etc.
local level, content = mw.ustring.match(text .. "\", "\(==+)%s*" .. escapedSection .. "%s*==.-\(.*)")
if not content then return nil end -- no such section
local nextsection
if mainonly then
nextsection = "\==.*" -- Main part of section terminates at any level of header
else
nextsection = "\==" .. mw.ustring.rep("=?", #level - 2) .. "[^=].*" -- "===" → "\===?[^=].*", matching "==" or "===" but not "===="
end
content = mw.ustring.gsub(content, nextsection, "") -- remove later sections with headings at this level or higher
return content
end
-- Remove unmatchedlocal function fixtags(text, tag)
local startcount = 0
for i in mw.ustring.gmatch(text, "<%s*" .. tag .. "%f[^%w_].->") do startcount = startcount + 1 end
local endcount = 0
for i in mw.ustring.gmatch(text, "<%s*/" .. tag .. "%f[^%w_].->") do endcount = endcount + 1 end
if startcount > endcount then -- more
local i = 0
text = mw.ustring.gsub(text, "<%s*" .. tag .. "%f[^%w_].->", function(t)
i = i + 1
if i > endcount then return "" else return nil end
end) -- "end" here terminates the anonymous replacement function(t) passed to gsub
elseif endcount > startcount then -- more than
text = mw.ustring.gsub(text, "<%s*/" .. tag .. "%f[^%w_].->", "", endcount - startcount)
end
return text
end
-- Main function returns a string value: text of the lead of a pagelocal function main(pagenames, options)
if not pagenames or #pagenames < 1 then return err("No page names given") end
local pagename
local text
local pagecount = #pagenames
local firstpage = pagenames[1] or "(nil)" -- save for error message, as it the name will be deleted
-- read the page, or a random one if multiple pages were provided
if pagecount > 1 then math.randomseed(os.time()) end
while not text and pagecount > 0 do
local pagenum = 1
if pagecount > 1 then pagenum = math.random(pagecount) end -- pick a random title
pagename = pagenames[pagenum]
if pagename and pagename ~= "" then
pagename = mw.ustring.match(pagename, "%[%[%s*(.-)[%]|]") or pagename -- "Bar" → "Foo"
pagename = mw.ustring.gsub(pagename, "^%s+", "") -- strip leading ...
pagename = mw.ustring.gsub(pagename, "%s+$", "") -- ...and trailing white space
if pagename and pagename ~= "" then
local pn, section = mw.ustring.match(pagename, "(.-)#(.*)")
pagename = pn or pagename
text, normalisedPagename = getContent(pagename)
if not normalisedPagename then
return err("No title for page name " .. pagename)
else
pagename = normalisedPagename
end
if text and options.nostubs then
local isStub = mw.ustring.find(text, "%s*{{[^{|}]*%-[Ss]tub%s*}}")
if isStub then text = nil end
end
if not section then
section = mw.ustring.match(pagename, ".-#(.*)") -- parse redirect to Page#Section
end
if text and section then text = getsection(text, section) end
end
end
if not text then table.remove(pagenames, pagenum) end -- this one didn't work; try another
pagecount = pagecount - 1 -- ensure that we exit the loop after at most #pagenames iterations
end
if not text then return err("Cannot read a valid page: first name is " .. firstpage) end
text = cleanupText(text, true)
local filetext
filetext, text = parse(text, options)
-- replace the bold title or synonym near the start of the article by a wikilink to the article
local lang = mw.language.getContentLanguage()
local pos = mw.ustring.find(text, "" .. lang:ucfirst(pagename) .. "", 1, true) -- look for "Foo is..." (uc) or "A foo is..." (lc)
or mw.ustring.find(text, "" .. lang:lcfirst(pagename) .. "", 1, true) -- plain search: special characters in pagename represent themselves
if pos then
local len = mw.ustring.len(pagename)
text = mw.ustring.sub(text, 1, pos + 2) .. "" .. mw.ustring.sub(text, pos + 3, pos + len + 2) .. "" .. mw.ustring.sub(text, pos + len + 3, -1) -- link it
else -- look for anything unlinked in bold, assumed to be a synonym of the title (e.g. a person's birth name)
text = mw.ustring.gsub(text, "()(.-'*)", function(a, b)
if a < 100 and not mw.ustring.find(b, "%[") then ---if early in article and not wikilinked
return "" .. b .. "" -- replace Foo by Foo
else
return nil -- instruct gsub to make no change
end
end, 1) -- "end" here terminates the anonymous replacement function(a, b) passed to gsub
end
text = filetext .. text
-- Seek and destroy unterminated templates and wikilinks
repeat -- hide matched {{template}}s including nested templates
local t = text
text = mw.ustring.gsub(text, "{(%b{})}", "\\27{\\27%1\\27}\\27"); -- {{sometemplate}} → E{Esometemplate}E}E where E represents escape
text = mw.ustring.gsub(text, "(< *math[^>]*>[^<]-)}}(.-< */math *>)", "%1}\\27}\\27%2"); -- 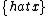 →
→ 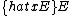
until text == t
repeat -- do similar for wikilinks
local t = text
text = mw.ustring.gsub(text, "%[(%b[])%]", "\\27[\\27%1\\27]\\27");
until text == t
text = text.gsub(text, "([{}%[%]])%1[^\\27].*", ""); -- remove unmatched {{, }}, or and everything thereafter, avoiding ]E]E etc.
text = text.gsub(text, "([{}%[%]])%1$", ""); -- remove unmatched {{, }}, or at end of text
text = mw.ustring.gsub(text, "\\27", ""); -- unhide matched pairs: E{E{ → {{, ]E]E → ]], etc.
-- Ensure div tags match
text = fixtags(text, "div")
if options.more then text = text .. " " .. options.more .. "" end -- wikilink to article for more info
return text
end
-- Shared template invocation code for lead and random functionslocal function invoke(frame, func)
-- args = { 1,2,... = page names, paragraphs = list e.g. "1,3-5", files = list, more = text}
local args = {} -- args[k] = frame.args[k] or frame:getParent().args[k] for all k in either (numeric or not)
for k, v in pairs(frame:getParent().args) do args[k] = v end
for k, v in pairs(frame.args) do args[k] = v end -- args from a Lua call have priority over parent args from template
errors = args["errors"] -- set the module level boolean used in local function err
local articlecount = #args -- must be 1 except with selected=Foo and Foo=Somepage
if articlecount < 1 and not (func == "selected" and args[func] and args[args[func]]) then
return err("No articles provided")
end
local pagenames = {}
if func == "lead" then
pagenames = { args[1] }
elseif func == "linked" or func == "listitem" then
-- Read named page and find its wikilinks
local page = args[1]
local text, title = getContent(page)
if not title then
return err("No title for page name " .. page)
elseif not text then
return err("No content for page name " .. page)
end
if args["section"] then -- check relevant section only
text = getsection(text, args["section"], args["sectiononly"])
if not text then return err("No section " .. args["section"] .. " in page " .. page) end
end
-- replace annotated links with real links
text = mw.ustring.gsub(text, "{{%s*[Aa]nnotated[ _]link%s*|%s*(.-)%s*}}", "%1")
if func == "linked" then
for p in mw.ustring.gmatch(text, "%[%[%s*([^%]|\]*)") do table.insert(pagenames, p) end
else -- listitem: first wikilink on a line beginning *, :#, etc. except in "See also" or later section
text = mw.ustring.gsub(text, "\== *See also.*", "")
for p in mw.ustring.gmatch(text, "\*[%*#][^\]-%[%[%s*([^%]|\]*)") do table.insert(pagenames, p) end
end
elseif func == "random" then
-- accept any number of page names. If more than one, we'll pick one randomly
for i, p in pairs(args) do
if p and type(i) == 'number' then table.insert(pagenames, p) end
end
elseif func == "selected" then
local articlekey = args[func]
if tonumber(articlekey) then -- normalise article number into the range 1..#args
articlekey = articlekey % articlecount
if articlekey == 0 then articlekey = articlecount end
end
pagenames = { args[articlekey] }
end
local options = args -- pick up miscellaneous options: more, errors, fileargs
options.paraflags = numberflags(args["paragraphs"] or "") -- parse paragraphs, e.g. "1,3-5" → {"1","3-5"}
options.fileflags = numberflags(args["files"] or "") -- parse file numbers
if options.more and options.more == "" then options.more = "Read more..." end -- more= is short for this default text
local text = main(pagenames, options)
return frame:preprocess(text)
end
-- Entry points for template callers using #invoke:function p.lead(frame) return invoke(frame, "lead") end -- {{Transclude lead excerpt}} reads the first and only article
function p.linked(frame) return invoke(frame, "linked") end -- {{Transclude linked excerpt}} reads a randomly selected article linked from the given page
function p.listitem(frame) return invoke(frame, "listitem") end -- {{Transclude list item excerpt}} reads a randomly selected article listed on the given page
function p.random(frame) return invoke(frame, "random") end -- {{Transclude random excerpt}} reads any article (default for invoke with one argument)
function p.selected(frame) return invoke(frame, "selected") end -- {{Transclude selected excerpt}} reads the article whose key is in the selected= parameter
-- Entry points for other Lua modulesfunction p.getContent(page, frame) return getContent(page, frame) end
function p.getsection(text, section) return getsection(text, section) end
function p.parse(text, options, filesOnly) return parse(text, options, filesOnly) end
function p.argimage(text) return argimage(text) end
function p.checkimage(image) return checkimage(image) end
function p.parseimage(text, start) return parseimage(text, start) end
function p.cleanupText(text, leadOnly) return cleanupText(text, leadOnly) end
function p.main(pagenames, options) return main(pagenames, options) end
function p.numberflags(str) return numberflags(str) end
return p
- Poniards
- Poniatow
- Poniatowski Bridge
- Poniatowski bridge
- Poniatowskiego Bridge
- Poniatów
- Poniatów, Lower Silesian Voivodeship
- Ponicova River (Caraș)
- Ponicova River (Danube)
- Poni Hoax
- Ponikovica
- Ponikowo
- Ponikve Airport
- Ponikvica
- Ponikwa
- Ponikwa, Lower Silesian Voivodeship
- Poniky
- Poni Province
- Poni Province, Burkina Faso
- Ponitrie Protected Landscape Area
- Ponitz
- Ponivezh
- Ponița River
- Ponji pit
- Ponk