- Formal definition
- Application
- Variants and associated algorithms
- Mixing rates and algorithmic convergence
- References
Stochastic gradient Langevin dynamics (abbreviated as SGLD), is an optimization technique composed of characteristics from Stochastic gradient descent, a Robbins-Monro optimization algorithm, and Langevin dynamics, a mathematical extension of molecular dynamics models. Like stochastic gradient descent, SGLD is an iterative optimization algorithm which introduces additional noise to the stochastic gradient estimator used in SGD to optimize a differentiable objective function.[1] Unlike traditional SGD, SGLD can be used for Bayesian learning, since the method produces samples from a posterior distribution of parameters based on available data. First described by Welling and Teh in 2011, the method has applications in many contexts which require optimization, and is most notably applied in machine learning problems.
Formal definition
Given some parameter vector  , its prior distribution
, its prior distribution  , and a set of data points
, and a set of data points  , Stochastic Gradient Langevin dynamics samples from the posterior distribution
, Stochastic Gradient Langevin dynamics samples from the posterior distribution  by updating the chain:
by updating the chain:

where  is a positive integer,
is a positive integer,  is Gaussian noise,
is Gaussian noise,  is the likelihood of the data given the parameter vector , and our step sizes
is the likelihood of the data given the parameter vector , and our step sizes 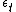 satisfy the following conditions:
satisfy the following conditions:

For early iterations of the algorithm, each parameter update mimics Stochastic Gradient Descent; however, as the algorithm approaches a local minima or maxima, the gradient shrinks to zero and the chain produces samples surrounding the maximum a posteriori mode allowing for posterior inference. This process generates approximate samples from the posterior as by balancing variance from the injected Gaussian noise and stochastic gradient computation.{{citation needed|date=December 2018}}
Application
SGDL is applicable in any optimization context for which it is desirable to quickly obtain posterior samples instead of a maximum a posteriori mode. In doing so, the method maintains the computational efficiency of stochastic gradient descent when compared to traditional gradient descent while providing additional information regarding the landscape around the critical point of the objective function. In practice, SGLD can be applied to the training of Bayesian Neural Networks in Deep Learning, a task in which the method provides a distribution over model parameters. By introducing information about the variance of these parameters, SGLD characterizes the generalizability of these models at certain points in training.[2] Additionally, obtaining samples from a posterior distribution permits uncertainty quantification by means of confidence intervals, a feature which is not possible using traditional stochastic gradient descent.{{citation needed|date=December 2018}}
Variants and associated algorithms
If gradient computations are exact, SGLD reduces down to the Langevin Monte Carlo[3] algorithm, first coined in the literature of lattice field theory. This algorithm is also a reduction of Hybrid or Hamiltonian Monte Carlo, consisting of a single leapfrog step proposal rather than a series of steps.[4] Since SGLD can be formulated as a modification of both Stochastic Gradient Descent and MCMC methods, the method lies at the intersection between optimization and sampling algorithms; the method maintains SGD's ability to quickly converge to regions of low cost while providing samples to facilitate posterior inference.{{citation needed|date=December 2018}}
Considering relaxed constraints on the step sizes such that they do not approach zero asymptotically, SGLD fails to produce samples for which the Metropolis Hastings rejection rate is zero, and thus a MH rejection step becomes necessary.[1] The resulting algorithm, dubbed the Metropolis Adjusted Langevin algorithm,[6] requires the step:

where  is a normal distribution centered one gradient descent step from
is a normal distribution centered one gradient descent step from  and is our target distribution.{{citation needed|date=December 2018}}
and is our target distribution.{{citation needed|date=December 2018}}
Mixing rates and algorithmic convergence
Recent contributions have proven upper bounds on mixing times for both the Traditional Langevin Algorithm and the Metropolis Adjusted Langevin Algorithm.[5] Released in Ma et al., 2018, these bounds define the rate at which the algorithms converge to the true posterior distribution, defined formally as:

where  is an arbitrary error tolerance,
is an arbitrary error tolerance,  is some initial distribution,
is some initial distribution, 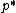 is the posterior distribution, and
is the posterior distribution, and  is the total variation norm. Under some regularity conditions of an L-Lipschitz smooth objective function
is the total variation norm. Under some regularity conditions of an L-Lipschitz smooth objective function 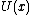 which is m-strongly convex outside of a region of radius
which is m-strongly convex outside of a region of radius  with condition number
with condition number  , we have mixing rate bounds:
, we have mixing rate bounds:


where  and
and  refer to the mixing rates of the Unadjusted Langevin Algorithm and the Metropolis Adjusted Langevin Algorithm respectively. These bounds are important because they show computational complexity is polynomial in dimension
refer to the mixing rates of the Unadjusted Langevin Algorithm and the Metropolis Adjusted Langevin Algorithm respectively. These bounds are important because they show computational complexity is polynomial in dimension  conditional on
conditional on  being
being  .
.
References
2. ^Chaudhari, Pratik, Choromanska, Anna, Soatto, Stefano, Le- Cun, Yann, Baldassi, Carlo, Borgs, Christian, Chayes, Jennifer, Sagun, Levent, and Zecchina, Riccardo. Entropy-sgd: Biasing gradient descent into wide valleys. In ICLR’2017, arXiv:1611.01838, 2017.
3. ^Kennedy, A. D. (1990). The theory of hybrid stochastic algorithms. In Probabilistic Methods in Quantum Field Theory and Quantum Gravity, pages 209–223. Plenum Press.
4. ^R. Neal. Handbook of Markov Chain Monte Carlo, chapter 5: MCMC Using Hamiltonian Dynamics. CRC Press, 2011.
5. ^1 Ma, Y.A., Chen, Y., Jin, C., Flammarion, N. and Jordan, M.I., 2018. Sampling Can Be Faster Than Optimization. arXiv preprint arXiv:1811.08413.
- Maiseyhampton Church
- Maisey Hampton Church
- Mais Galiza
- Mais Gomar
- Maisha Film Lab
- Maishan
- Mai Shiina
- Mai Shiraishi
- Maisie Carr
- Maisie Dobbs (novel)
- Maisie Fawcett
- Maisie Goes to Reno
- Maisie Mac
- Maisie MacKenzie
- Maisie (Meusaidh)
- Maisie Moscow
- Maisie Richardson-Sellers
- Maisie Richardson-Sellers (actress)
- Maisie (song)
- Maisie Ward
- Maisi fisheri
- Maisi frog
- Maisigandi maisamma temple Kadthal
- Maisi (genus)
- Maisin