- Training IBM Models HMM
- Software
- References
Bitext word alignment or simply word alignment is the natural language processing task of identifying translation relationships among the words (or more rarely multiword units) in a bitext, resulting in a bipartite graph between the two sides of the bitext, with an arc between two words if and only if they are translations of one another. Word alignment is typically done after sentence alignment has already identified pairs of sentences that are translations of one another.
Bitext word alignment is an important supporting task for most methods of statistical machine translation. The parameters of statistical machine translation models are typically estimated by observing word-aligned bitexts,[1] and conversely automatic word alignment is typically done by choosing that alignment which best fits a statistical machine translation model. Circular application of these two ideas results in an instance of the expectation-maximization algorithm.[2]
This approach to training is an instance of unsupervised learning, in that the system is not given examples of the kind of output desired, but is trying to find values for the unobserved model and alignments which best explain the observed bitext. Recent work has begun to explore supervised methods which rely on presenting the system with a (usually small) number of manually aligned sentences.[3] In addition to the benefit of the additional information provided by supervision, these models are typically also able to more easily take advantage of combining many features of the data, such as context, syntactic structure, part-of-speech, or translation lexicon information, which are difficult to integrate into the generative statistical models traditionally used.
Besides the training of machine translation systems, other applications of word alignment include translation lexicon induction, word sense discovery, word sense disambiguation and the cross-lingual projection of linguistic information.
Training
IBM Models
{{Main article|IBM alignment models}}The IBM models[4] are used in Statistical machine translation to train a translation model and an alignment model. They are an instance of the Expectation–maximization algorithm: in the expectation-step the translation probabilities within each sentence are computed, in the maximization step they are accumulated to global translation probabilities.
Features:
- IBM Model 1: lexical alignment probabilities
- IBM Model 2: absolute positions
- IBM Model 3: fertilities (supports insertions)
- IBM Model 4: relative positions
- IBM Model 5: fixes deficiencies (ensures that no two words can be aligned to the same position)
HMM
Vogel et. al[5] developed an approach featuring lexical translation probabilities and relative alignment by mapping the problem to a Hidden Markov model. The states and observations represent the source and target words respectively. The transition probabilities model the alignment probabilities. In training the translation and alignment probabilities can be obtained from 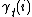 and
and 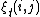 in the Forward-backward algorithm.
in the Forward-backward algorithm.
Software
- [https://github.com/moses-smt/giza-pp GIZA++] (free software under GPL)
- The most widely used alignment toolkit, implementing the famous IBM models with a variety of improvements
- [https://code.google.com/p/berkeleyaligner/ The Berkeley Word Aligner] (free software under GPL)
- Another widely used aligner implementing alignment by agreement, and discriminative models for alignment
- [https://code.google.com/p/nile/ Nile] (free software under GPL)
- A supervised word aligner that is able to use syntactic information on the source and target side
- pialign (free software under the Common Public License)
- An aligner that aligns both words and phrases using Bayesian learning and inversion transduction grammars
- Natura Alignment Tools (NATools, free software under GPL)
- UNL aligner (free software under Creative Commons Attribution 3.0 Unported License)
- Geometric Mapping and Alignment (GMA) (free software under GPL)
- [https://anymalign.limsi.fr/ Anymalign] (free software under GPL)
References
2. ^Och, F.J. and Tillmann, C. and Ney, H. and others 1999, Improved alignment models for statistical machine translation, Proc. of the Joint SIGDAT Conf. on Empirical Methods in Natural Language Processing and Very Large Corpora
3. ^ACL 2005: Building and Using Parallel Texts for Languages with Scarce Resources {{webarchive |url=https://web.archive.org/web/20090509231708/http://www.cse.unt.edu/~rada/wpt05/ |date=May 9, 2009 }}
4. ^{{cite book |last=Philipp Koehn |first= |date=2009 |title=Statistical Machine Translation |url=http://www.statmt.org/book/ |location= |publisher=Cambridge University Press |page=86ff |isbn=0521874157 |access-date= 21 October 2015 }}
5. ^S. Vogel, H. Ney and C. Tillmann. 1996. [https://aclanthology.info/pdf/C/C96/C96-2141.pdf HMM-based Word Alignment in Statistical Translation]. In COLING ’96: The 16th International Conference on Computational Linguistics, pp. 836-841, Copenhagen, Denmark.
- You're So Cool
- You're So Damn Hot
- You're So Good to Me
- You're So Good To Me
- You're So Great
- You're So Last Summer
- You're So Pretty – We're So Pretty
- You're So Right for Me
- You're So Right For Me
- You're so Vain
- You're so vain
- You're So Vain, You Probably Think This Zit Is About You
- You're Speaking My Language
- You're Special
- You're Still Here
- You're Still The One
- You're Still the One
- You're Supposed To Be My Friend
- You're Supposed to Be My Friend
- You're the Apple of My Eye
- You're the Best
- You're the Best Thing That Ever Happened to Me
- You're the Cream in My Coffee
- You're The Cream In My Coffee
- You're the First, the Last, My Everything