- Overview
- Semantics
- Terms and conditions Tree terms Reals Finite domains
- The constraint store
- Labeling
- Program reformulations
- Constraint handling rules
- Bottom-up evaluation
- Concurrent constraint logic programming
- Applications
- History
- See also
- References
Constraint logic programming is a form of constraint programming, in which logic programming is extended to include concepts from constraint satisfaction. A constraint logic program is a logic program that contains constraints in the body of clauses. An example of a clause including a constraint is {{code|2=prolog|A(X,Y) :- X+Y>0, B(X), C(Y)}}. In this clause, {{code|2=prolog|X+Y>0}} is a constraint; A(X,Y), B(X), and C(Y) are literals as in regular logic programming. This clause states one condition under which the statement A(X,Y) holds: X+Y is greater than zero and both B(X) and C(Y) are true.
As in regular logic programming, programs are queried about the provability of a goal, which may contain constraints in addition to literals. A proof for a goal is composed of clauses whose bodies are satisfiable constraints and literals that can in turn be proved using other clauses. Execution is performed by an interpreter, which starts from the goal and recursively scans the clauses trying to prove the goal. Constraints encountered during this scan are placed in a set called constraint store. If this set is found out to be unsatisfiable, the interpreter backtracks, trying to use other clauses for proving the goal. In practice, satisfiability of the constraint store may be checked using an incomplete algorithm, which does not always detect inconsistency.
Overview
Formally, constraint logic programs are like regular logic programs, but the body of clauses can contain constraints, in addition to the regular logic programming literals. As an example, X>0 is a constraint, and is included in the last clause of the following constraint logic program.
B(X,1):- X<0. B(X,Y):- X=1, Y>0. A(X,Y):- X>0, B(X,Y).
Like in regular logic programming, evaluating a goal such as A(X,1) requires evaluating the body of the last clause with Y=1. Like in regular logic programming, this in turn requires proving the goal B(X,1). Contrary to regular logic programming, this also requires a constraint to be satisfied: X>0, the constraint in the body of the last clause (in regular logic programming, X>0 cannot be proved unless X is bound to a fully ground term and execution of the program will fail if that is not the case).
Whether a constraint is satisfied cannot always be determined when the constraint is encountered. In this case, for example, the value of X is not determined when the last clause is evaluated. As a result, the constraint X>0 is not satisfied nor violated at this point. Rather than proceeding in the evaluation of B(X,1) and then checking whether the resulting value of X is positive afterwards, the interpreter stores the constraint X>0 and then proceeds in the evaluation of B(X,1); this way, the interpreter can detect violation of the constraint X>0 during the evaluation of B(X,1), and backtrack immediately if this is the case, rather than waiting for the evaluation of B(X,1) to conclude.
In general, the evaluation of a constraint logic program proceeds like for a regular logic program, but constraints encountered during evaluation are placed in a set called constraint store. As an example, the evaluation of the goal A(X,1) proceeds by evaluating the body of the first clause with Y=1; this evaluation adds X>0 to the constraint store and requires the goal B(X,1) to be proved. While trying to prove this goal, the first clause is applicable, but its evaluation adds X<0 to the constraint store. This addition makes the constraint store unsatisfiable, and the interpreter backtracks, removing the last addition from the constraint store. The evaluation of the second clause adds X=1 and Y>0 to the constraint store. Since the constraint store is satisfiable and no other literal is left to prove, the interpreter stops with the solution X=1, Y=1.
Semantics
The semantics of constraint logic programs can be defined in terms of a virtual interpreter that maintains a pair 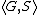 during execution. The first element of this pair is called current goal; the second element is called constraint store. The current goal contains the literals the interpreter is trying to prove and may also contain some constraints it is trying to satisfy; the constraint store contains all constraints the interpreter has assumed satisfiable so far.
during execution. The first element of this pair is called current goal; the second element is called constraint store. The current goal contains the literals the interpreter is trying to prove and may also contain some constraints it is trying to satisfy; the constraint store contains all constraints the interpreter has assumed satisfiable so far.
Initially, the current goal is the goal and the constraint store is empty. The interpreter proceeds by removing the first element from the current goal and analyzing it. The details of this analysis are explained below, but in the end this analysis may produce a successful termination or a failure. This analysis may involve recursive calls and addition of new literals to the current goal and new constraint to the constraint store. The interpreter backtracks if a failure is generated. A successful termination is generated when the current goal is empty and the constraint store is satisfiable.
The details of the analysis of a literal removed from the goal is as follows. After having removed this literal from the front of the goal, it is checked whether it is a constraint or a literal. If it is a constraint, it is added to the constraint store. If it is a literal, a clause whose head has the same predicate of the literal is chosen; the clause is rewritten by replacing its variables with new variables (variables not occurring in the goal): the result is called a fresh variant of the clause; the body of the fresh variant of the clause is then placed in front of the goal; the equality of each argument of the literal with the corresponding one of the fresh variant head is placed in front of the goal as well.
Some checks are done during these operations. In particular, the constraint store is checked for consistency every time a new constraint is added to it. In principle, whenever the constraint store is unsatisfiable the algorithm could backtrack. However, checking unsatisfiability at each step would be inefficient. For this reason, an incomplete satisfiability checker may be used instead. In practice, satisfiability is checked using methods that simplify the constraint store, that is, rewrite it into an equivalent but simpler-to-solve form. These methods can sometimes but not always prove unsatisfiability of an unsatisfiable constraint store.
The interpreter has proved the goal when the current goal is empty and the constraint store is not detected unsatisfiable. The result of execution is the current set of (simplified) constraints. This set may include constraints such as 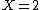 that force variables to a specific value, but may also include constraints like
that force variables to a specific value, but may also include constraints like 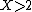 that only bound variables without giving them a specific value.
that only bound variables without giving them a specific value.
Formally, the semantics of constraint logic programming is defined in terms of derivations. A transition is a pair of pairs goal/store, noted 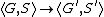 . Such a pair states the possibility of going from state to state
. Such a pair states the possibility of going from state to state  . Such a transition is possible in three possible cases:
. Such a transition is possible in three possible cases:
- an element of {{mvar|G}} is a constraint {{mvar|C}},
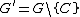 and
and  ; in other words, a constraint can be moved from the goal to the constraint store
; in other words, a constraint can be moved from the goal to the constraint store - an element of {{mvar|G}} is a literal
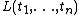 , there exists a clause that, rewritten using new variables, is
, there exists a clause that, rewritten using new variables, is  ,
,  is {{mvar|G}} with replaced by
is {{mvar|G}} with replaced by 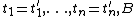 , and
, and 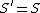 ; in other words, a literal can be replaced by the body of a fresh variant of a clause having the same predicate in the head, adding the body of the fresh variant and the above equalities of terms to the goal
; in other words, a literal can be replaced by the body of a fresh variant of a clause having the same predicate in the head, adding the body of the fresh variant and the above equalities of terms to the goal - {{mvar|S}} and
 are equivalent according to the specific constraint semantics
are equivalent according to the specific constraint semantics
A sequence of transitions is a derivation. A goal {{mvar|G}} can be proved if there exists a derivation from 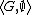 to
to 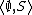 for some satisfiable constraint store {{mvar|S}}. This semantics formalizes the possible evolutions of an interpreter that arbitrarily chooses the literal of the goal to process and the clause to replace literals. In other words, a goal is proved under this semantics if there exists a sequence of choices of literals and clauses, among the possibly many ones, that lead to an empty goal and satisfiable store.
for some satisfiable constraint store {{mvar|S}}. This semantics formalizes the possible evolutions of an interpreter that arbitrarily chooses the literal of the goal to process and the clause to replace literals. In other words, a goal is proved under this semantics if there exists a sequence of choices of literals and clauses, among the possibly many ones, that lead to an empty goal and satisfiable store.
Actual interpreters process the goal elements in a LIFO order: elements are added in the front and processed from the front. They also choose the clause of the second rule according to the order in which they are written, and rewrite the constraint store when it is modified.
The third possible kind of transition is a replacement of the constraint store with an equivalent one. This replacement is limited to those done by specific methods, such as constraint propagation. The semantics of constraint logic programming is parametric not only to the kind of constraints used but also to the method for rewriting the constraint store. The specific methods used in practice replace the constraint store with one that is simpler to solve. If the constraint store is unsatisfiable, this simplification may detect this unsatisfiability sometimes, but not always.
The result of evaluating a goal against a constraint logic program is defined if the goal is proved. In this case, there exists a derivation from the initial pair to a pair where the goal is empty. The constraint store of this second pair is considered the result of the evaluation. This is because the constraint store contains all constraints assumed satisfiable to prove the goal. In other words, the goal is proved for all variable evaluations that satisfy these constraints.
The pairwise equality of terms of two literals is often compactly denoted by  : this is a shorthand for the constraints
: this is a shorthand for the constraints 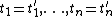 . A common variant of the semantics for constraint logic programming adds directly to the constraint store rather than to the goal.
. A common variant of the semantics for constraint logic programming adds directly to the constraint store rather than to the goal.
Terms and conditions
Different definitions of terms are used, generating different kinds of constraint logic programming: over trees, reals, or finite domains. A kind of constraint that is always present is the equality of terms. Such constraints are necessary because the interpreter adds t1=t2 to the goal whenever a literal P(...t1...) is replaced with the body of a clause fresh variant whose head is P(...t2...).
Tree terms
Constraint logic programming with tree terms emulates regular logic programming by storing substitutions as constraints in the constraint store. Terms are variables, constants, and function symbols applied to other terms. The only constraints considered are equalities and disequalities between terms. Equality is particularly important, as constraints like t1=t2 are often generated by the interpreter. Equality constraints on terms can be simplified, that is solved, via unification:
A constraint t1=t2 can be simplified if both terms are function symbols applied to other terms. If the two function symbols are the same and the number of subterms is also the same, this constraint can be replaced with the pairwise equality of subterms. If the terms are composed of different function symbols or the same functor but on different number of terms, the constraint is unsatisfiable.
If one of the two terms is a variable, the only allowed value the variable can take is the other term. As a result, the other term can replace the variable in the current goal and constraint store, thus practically removing the variable from consideration. In the particular case of equality of a variable with itself, the constraint can be removed as always satisfied.
In this form of constraint satisfaction, variable values are terms.
Reals
Constraint logic programming with real numbers uses real expressions as terms. When no function symbols are used, terms are expressions over reals, possibly including variables. In this case, each variable can only take a real number as a value.
To be precise, terms are expressions over variables and real constants. Equality between terms is a kind of constraint that is always present, as the interpreter generates equality of terms during execution. As an example, if the first literal of the current goal is A(X+1) and the interpreter has chosen a clause that is A(Y-1):-Y=1 after rewriting is variables, the constraints added to the current goal are X+1=Y-1 and 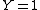 . The rules of simplification used for function symbols are obviously not used:
. The rules of simplification used for function symbols are obviously not used: X+1=Y-1 is not unsatisfiable just because the first expression is built using + and the second using -.
Reals and function symbols can be combined, leading to terms that are expressions over reals and function symbols applied to other terms. Formally, variables and real constants are expressions, as any arithmetic operator over other expressions. Variables, constants (zero-arity-function symbols), and expressions are terms, as any function symbol applied to terms. In other words, terms are built over expressions, while expressions are built over numbers and variables. In this case, variables ranges over real numbers and terms. In other words, a variable can take a real number as a value, while another takes a term.
Equality of two terms can be simplified using the rules for tree terms if none of the two terms is a real expression. For example, if the two terms have the same function symbol and number of subterms, their equality constraint can be replaced with the equality of subterms.
Finite domains
{{see also|Constraint satisfaction problem}}The third class of constraints used in constraint logic programming is that of finite domains. Values of variables are in this case taken from a finite domain, often that of integer numbers. For each variable, a different domain can be specified: X::[1..5] for example means that the value of X is between 1 and 5. The domain of a variable can also be given by enumerating all values a variable can take; therefore, the above domain declaration can be also written X::[1,2,3,4,5]. This second way of specifying a domain allows for domains that are not composed of integers, such as X::[george,mary,john]. If the domain of a variable is not specified, it is assumed to be the set of integers representable in the language. A group of variables can be given the same domain using a declaration like [X,Y,Z]::[1..5].
The domain of a variable may be reduced during execution. Indeed, as the interpreter adds constraints to the constraint store, it performs constraint propagation to enforce a form of local consistency, and these operations may reduce the domain of variables. If the domain of a variable becomes empty, the constraint store is inconsistent, and the algorithm backtracks. If the domain of a variable becomes a singleton, the variable can be assigned the unique value in its domain. The forms of consistency typically enforced are arc consistency, hyper-arc consistency, and bound consistency. The current domain of a variable can be inspected using specific literals; for example, dom(X,D) finds out the current domain D of a variable X.
As for domains of reals, functors can be used with domains of integers. In this case, a term can be an expression over integers, a constant, or the application of a functor over other terms. A variable can take an arbitrary term as a value, if its domain has not been specified to be a set of integers or constants.
The constraint store
The constraint store contains the constraints that are currently assumed satisfiable. It can be considered what the current substitution is for regular logic programming. When only tree terms are allowed, the constraint store contains constraints in the form t1=t2; these constraints are simplified by unification, resulting in constraints of the form variable=term; such constraints are equivalent to a substitution.
However, the constraint store may also contain constraints in the form t1!=t2, if the difference != between terms is allowed. When constraints over reals or finite domains are allowed, the constraint store may also contain domain-specific constraints like X+2=Y/2, etc.
The constraint store extends the concept of current substitution in two ways. First, it does not only contain the constraints derived from equating a literal with the head of a fresh variant of a clause, but also the constraints of the body of clauses. Second, it does not only contain constraints of the form variable=value but also constraints on the considered constraint language. While the result of a successful evaluation of a regular logic program is the final substitution, the result for a constraint logic program is the final constraint store, which may contain constraint of the form variable=value but in general may contain arbitrary constraints.
Domain-specific constraints may come to the constraint store both from the body of a clauses and from equating a literal with a clause head: for example, if the interpreter rewrites the literal A(X+2) with a clause whose fresh variant head is A(Y/2), the constraint X+2=Y/2 is added to the constraint store. If a variable appears in a real or finite domain expression, it can only take a value in the reals or the finite domain. Such a variable cannot take a term made of a functor applied to other terms as a value. The constraint store is unsatisfiable if a variable is bound to take both a value of the specific domain and a functor applied to terms.
After a constraint is added to the constraint store, some operations are performed on the constraint store. Which operations are performed depends on the considered domain and constraints. For example, unification is used for finite tree equalities, variable elimination for polynomial equations over reals, constraint propagation to enforce a form of local consistency for finite domains. These operations are aimed at making the constraint store simpler to be checked for satisfiability and solved.
As a result of these operations, the addition of new constraints may change the old ones. It is essential that the interpreter is able to undo these changes when it backtracks. The simplest case method is for the interpreter to save the complete state of the store every time it makes a choice (it chooses a clause to rewrite a goal). More efficient methods for allowing the constraint store to return to a previous state exist. In particular, one may just save the changes to the constraint store made between two points of choice, including the changes made to the old constraints. This can be done by simply saving the old value of the constraints that have been modified; this method is called trailing. A more advanced method is to save the changes that have been done on the modified constraints. For example, a linear constraint is changed by modifying its coefficient: saving the difference between the old and new coefficient allows reverting a change. This second method is called semantic backtracking,
because the semantics of the change is saved rather than the old version of the constraints only.
Labeling
The labeling literals are used on variables over finite domains to check satisfiability or partial satisfiability of the constraint store and to find a satisfying assignment. A labeling literal is of the form labeling([variables]), where the argument is a list of variables over finite domains. Whenever the interpreter evaluates such a literal, it performs a search over the domains of the variables of the list to find an assignment that satisfies all relevant constraints. Typically, this is done by a form of backtracking: variables are evaluated in order, trying all possible values for each of them, and backtracking when inconsistency is detected.
The first use of the labeling literal is to actual check satisfiability or partial satisfiability of the constraint store. When the interpreter adds a constraint to the constraint store, it only enforces a form of local consistency on it. This operation may not detect inconsistency even if the constraint store is unsatisfiable. A labeling literal over a set of variables enforces a satisfiability check of the constraints over these variables. As a result, using all variables mentioned in the constraint store results in checking satisfiability of the store.
The second use of the labeling literal is to actually determine an evaluation of the variables that satisfies the constraint store. Without the labeling literal, variables are assigned values only when the constraint store contains a constraint of the form X=value and when local consistency reduces the domain of a variable to a single value. A labeling literal over some variables forces these variables to be evaluated. In other words, after the labeling literal has been considered, all variables are assigned a value.
Typically, constraint logic programs are written in such a way labeling literals are evaluated only after as many constraints as possible have been accumulated in the constraint store. This is because labeling literals enforce search, and search is more efficient if there are more constraints to be satisfied. A constraint satisfaction problem is typical solved by a constraint logic program having the following structure:
solve(X):-constraints(X), labeling(X) constraints(X):- (all constraints of the CSP)
When the interpreter evaluates the goal solve(args), it places the body of a fresh variant of the first clause in the current goal. Since the first goal is constraints(X'), the second clause is evaluated, and this operation moves all constraints in the current goal and eventually in the constraint store. The literal labeling(X') is then evaluated, forcing a search for a solution of the constraint store. Since the constraint store contains exactly the constraints of the original constraint satisfaction problem, this operation searches for a solution of the original problem.
Program reformulations
A given constraint logic program may be reformulated to improve its efficiency. A first rule is that labeling literals should be placed after as much constraints on the labeled literals are accumulated in the constraint store. While in theory {{code|2=prolog|A(X):-labeling(X),X>0}} is equivalent to {{code|2=prolog|A(X):-X>0,labeling(X)}}, the search that is performed when the interpreter encounters the labeling literal is on a constraint store that does not contain the constraint X>0. As a result, it may generate solutions, such as X=-1, that are later found out not to satisfy this constraint. On the other hand, in the second formulation the search is performed only when the constraint is already in the constraint store. As a result, search only returns solutions that are consistent with it, taking advantage of the fact that additional constraints reduce the search space.
A second reformulation that can increase efficiency is to place constraints before literals in the body of clauses. Again, {{code|2=prolog|A(X):-B(X),X>0}} and {{code|2=prolog|A(X):-X>0,B(X)}} are in principle equivalent. However, the first may require more computation. For example, if the constraint store contains the constraint X<-2, the interpreter recursively evaluates B(X) in the first case; if it succeeds, it then finds out that the constraint store is inconsistent when adding X>0. In the second case, when evaluating that clause, the interpreter first adds X>0 to the constraint store and then possibly evaluates B(X). Since the constraint store after the addition of X>0 turns out to be inconsistent, the recursive evaluation of B(X) is not performed at all.
A third reformulation that can increase efficiency is the addition of redundant constrains. If the programmer knows (by whatever means) that the solution of a problem satisfies a specific constraint, they can include that constraint to cause inconsistency of the constraint store as soon as possible. For example, if it is known beforehand that the evaluation of B(X) will result in a positive value for X, the programmer may add X>0 before any occurrence of B(X). As an example, A(X,Y):-B(X),C(X) will fail on the goal A(-2,Z), but this is only found out during the evaluation of the subgoal B(X). On the other hand, if the above clause is replaced by {{code|2=prolog|A(X,Y):-X>0,A(X),B(X)}}, the interpreter backtracks as soon as the constraint X>0 is added to the constraint store, which happens before the evaluation of B(X) even starts.
Constraint handling rules
Constraint handling rules were initially defined as a stand-alone formalism for specifying constraint solvers, and were later embedded in logic programming. There are two kinds of constraint handling rules. The rules of the first kind specify that, under a given condition, a set of constraints is equivalent to another one. The rules of the second kind specify that, under a given condition, a set of constraints implies another one. In a constraint logic programming language supporting constraint handling rules, a programmer can use these rules to specify possible rewritings of the constraint store and possible additions of constraints to it. The following are example rules:
A(X) <=> B(X) | C(X) A(X) ==> B(X) | C(X)
The first rule tells that, if B(X) is entailed by the store, the constraint A(X) can be rewritten as C(X). As an example, N*X>0 can be rewritten as X>0 if the store implies that N>0. The symbol <=> resembles equivalence in logic, and tells that the first constraint is equivalent to the latter. In practice, this implies that the first constraint can be replaced with the latter.
The second rule instead specifies that the latter constraint is a consequence of the first, if the constraint in the middle is entailed by the constraint store. As a result, if A(X) is in the constraint store and B(X) is entailed by the constraint store, then C(X) can be added to the store. Differently from the case of equivalence, this is an addition and not a replacement: the new constraint is added but the old one remains.
Equivalence allows for simplifying the constraint store by replacing some constraints with simpler ones; in particular, if the third constraint in an equivalence rule is true, and the second constraint is entailed, the first constraint is removed from the constraint store. Inference allows for the addition of new constraints, which may lead to proving inconsistency of the constraint store, and may generally reduce the amount of search needed to establish its satisfiability.
Logic programming clauses in conjunction with constraint handling rules can be used to specify a method for establishing the satisfiability of the constraint store. Different clauses are used to implement the different choices of the method; the constraint handling rules are used for rewriting the constraint store during execution. As an example, one can implement backtracking with unit propagation this way. Let holds(L) represents a propositional clause, in which the literals in the list L are in the same order as they are evaluated. The algorithm can be implemented using clauses for the choice of assigning a literal to true or false, and constraint handling rules to specify propagation. These rules specify that holds([l|L]) can be removed if l=true follows from the store, and it can be rewritten as holds(L) if l=false follows from the store. Similarly, holds([l]) can be replaced by l=true. In this
example, the choice of value for a variable is implemented using clauses of logic programming; however, it can be encoded in constraint handling rules using an extension called disjunctive constraint handling rules or CHR∨.
Bottom-up evaluation
The standard strategy of evaluation of logic programs is top-down and depth-first: from the goal, a number of clauses are identified as being possibly able to prove the goal, and recursion over the literals of their bodies is performed. An alternative strategy is to start from the facts and use clauses to derive new facts; this strategy is called bottom-up. It is considered better than the top-down one when the aim is that of producing all consequences of a given program, rather than proving a single goal. In particular, finding all consequences of a program in the standard top-down and depth-first manner may not terminate while the bottom-up evaluation strategy terminates.
The bottom-up evaluation strategy maintains the set of facts proved so far during evaluation. This set is initially empty. With each step, new facts are derived by applying a program clause to the existing facts, and are added to the set. For example, the bottom up evaluation of the following program requires two steps:
A(q). B(X):-A(X).
The set of consequences is initially empty. At the first step, A(q) is the only clause whose body can be proved (because it is empty), and A(q) is therefore added to the current set of consequences. At the second step, since A(q) is proved, the second clause can be used and B(q) is added to the consequences. Since no other consequence can be proved from {A(q),B(q)}, execution terminates.
The advantage of the bottom-up evaluation over the top-down one is that cycles of derivations do not produce an infinite loop. This is because adding a consequence to the current set of consequences that already contains it has no effect. As an example, adding a third clause to the above program generates a cycle of derivations in the top-down evaluation:
A(q). B(X):-A(X). A(X):-B(X).
For example, while evaluating all answers to the goal A(X), the top-down strategy would produce the following derivations:
A(q) A(q):-B(q), B(q):-A(q), A(q) A(q):-B(q), B(q):-A(q), A(q):-B(q), B(q):-A(q), A(q)
In other words, the only consequence A(q) is produced first, but then the algorithm cycles over derivations that do not produce any other answer. More generally, the top-down evaluation strategy may cycle over possible derivations, possibly when other ones exist.
The bottom-up strategy does not have the same drawback, as consequences that were already derived has no effect. On the above program, the bottom-up strategy starts adding A(q) to the set of consequences; in the second step, B(X):-A(X) is used to derive B(q); in the third step, the only facts that can be derived from the current consequences are A(q) and B(q), which are however already in the set of consequences. As a result, the algorithm stops.
In the above example, the only used facts were ground literals. In general, every clause that only contains constraints in the body is considered a fact. For example, a clause A(X):-X>0,X<10 is considered a fact as well. For this extended definition of facts, some facts may be equivalent while not syntactically equal. For example, A(q) is equivalent to A(X):-X=q and both are equivalent to A(X):-X=Y, Y=q. To solve this problem, facts are translated into a normal form in which the head contains a tuple of all-different variables; two facts are then equivalent if their bodies are equivalent on the variables of the head, that is, their sets of solutions are the same when restricted to these variables.
As described, the bottom-up approach has the advantage of not considering consequences that have already been derived. However, it still may derive consequences that are entailed by those already derived while not being equal to any of them. As an example, the bottom up evaluation of the following program is infinite:
A(0). A(X):-X>0. A(X):-X=Y+1, A(Y).
The bottom-up evaluation algorithm first derives that A(X) is true for X=0 and X>0. In the second step, the first fact with the third clause allows for the derivation of A(1). In the third step, A(2) is derived, etc. However, these facts are already entailed by the fact that A(X) is true for any nonnegative X. This drawback can be overcome by checking for entailment facts that are to be added to the current set of consequences. If the new consequence is already entailed by the set, it is not added to it. Since facts are stored as clauses, possibly with "local variables", entailment is restricted over the variables of their heads.
Concurrent constraint logic programming
{{main|Concurrent constraint logic programming}}The concurrent versions of constraint logic programming are aimed at programming concurrent processes rather than solving constraint satisfaction problems. Goals in constraint logic programming are evaluated concurrently; a concurrent process is therefore programmed as the evaluation of a goal by the interpreter.
Syntactically, concurrent constraints logic programs are similar to non-concurrent programs, the only exception being that clauses includes guards, which are constraints that may block the applicability of the clause under some conditions. Semantically, concurrent constraint logic programming differs from its non-concurrent versions because a goal evaluation is intended to realize a concurrent process rather than finding a solution to a problem. Most notably, this difference affects how the interpreter behaves when more than one clause is applicable: non-concurrent constraint logic programming recursively tries all clauses; concurrent constraint logic programming chooses only one. This is the most evident effect of an intended directionality of the interpreter, which never revises a choice it has previously taken. Other effects of this are the semantical possibility of having a goal that cannot be proved while the whole evaluation does not fail, and a particular way for equating a goal and a clause head.
Applications
Constraint logic programming has been applied to a number of fields, such as civil engineering, mechanical engineering, digital circuit verification, automated timetabling, air traffic control, finance, and others.
History
Constraint logic programming was introduced by Jaffar and Lassez in 1987. They generalized the observation that the term equations and disequations of Prolog II were a specific form of constraints, and generalized this idea to arbitrary constraint languages. The first implementations of this concept were Prolog III, CLP(R), and CHIP.
See also
- BProlog
- BNR Prolog (aka CLP(BNR))
- Ciao
- CLP(R)
- Distributed Oz Mozart
- ECLiPSe
- GNU Prolog
- SWI-Prolog
References
- {{cite book
| first=Rina
| last=Dechter
| title=Constraint processing
| publisher=Morgan Kaufmann
| year=2003
| url=http://www.ics.uci.edu/~dechter/books/index.html
| isbn=1-55860-890-7
}} {{ISBN|1-55860-890-7}}
- {{cite book
| first=Krzysztof
| last=Apt
| title=Principles of constraint programming
| publisher=Cambridge University Press
| year=2003
| isbn=0-521-82583-0
}} {{ISBN|0-521-82583-0}}
- {{cite book
| first=Kim
| last=Marriott
|author2=Peter J. Stuckey
| title=Programming with constraints: An introduction
| year=1998
| publisher=MIT Press
}} {{ISBN|0-262-13341-5}}
- {{cite book
| first=Thom
| last=Frühwirth
|author2=Slim Abdennadher
| title=Essentials of constraint programming
| year=2003
| publisher=Springer
| isbn=3-540-67623-6
}} {{ISBN|3-540-67623-6}}
- {{cite journal
| first=Joxan
| last=Jaffar
|author2=Michael J. Maher
| title=Constraint logic programming: a survey
| journal=Journal of logic programming
| volume=19/20
| pages=503–581
| year=1994
| doi=10.1016/0743-1066(94)90033-7
}}
- {{cite journal
| first=Alain
| last = Colmerauer
| title=Opening the Prolog III Universe
| journal=Byte
| volume= August
| year=1987
}}{{DEFAULTSORT:Constraint Logic Programming}}
- Attack class
- Attack-class submarine
- Attack (computing)
- Attack-decay-sustain-release envelope
- Attack (disambiguation)
- Attacked!!
- Attacker-class patrol boat
- Attackerman
- Attackers
- Attacker You
- Attack! (film)
- Attack frequency
- Attack From Mars
- Attacking Cavalryman Statue, Iasi
- Attacking Cavalryman Statue, Iași
- Attacking faulty reasoning
- Attacking McEliece by finding low-weight codewords
- Attacking Midfielder (football)
- Attack in the Pacific
- Attackman (lacrosse)
- Attack Marketing
- Attack marketing
- Attack Me with Your Love
- Attack (music)
- Attack No.1