- Data dependencies Flow dependency Anti-dependency Output dependency
- Control Dependency Construction of Control Dependences
- Implications
- References
A data dependency in computer science is a situation in which a program statement (instruction) refers to the data of a preceding statement. In compiler theory, the technique used to discover data dependencies among statements (or instructions) is called dependence analysis.
There are three types of dependencies: data, name, and control.
Data dependencies
Assuming statement  and
and  , depends on if:
, depends on if:

where:
-
 is the set of memory locations read by
is the set of memory locations read by  and
and -
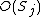 is the set of memory locations written by
is the set of memory locations written by 
- and there is a feasible run-time execution path from to
This Condition is called Bernstein Condition, named by A. J. Bernstein.
Three cases exist:
- Anti-dependence:
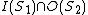 ,
,  and reads something before overwrites it
and reads something before overwrites it - Flow (data) dependence:
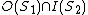 ,
, 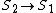 and writes before something read by
and writes before something read by - Output dependence:
 , and both write the same memory location.
, and both write the same memory location.
Flow dependency
A Flow dependency, also known as a data dependency or true dependency or read-after-write (RAW), occurs when an instruction depends on the result of a previous instruction:
1. A = 3 2. B = A 3. C = B
Instruction 3 is truly dependent on instruction 2, as the final value of C depends on the instruction updating B. Instruction 2 is truly dependent on instruction 1, as the final value of B depends on the instruction updating A. Since instruction 3 is truly dependent upon instruction 2 and instruction 2 is truly dependent on instruction 1, instruction 3 is also truly dependent on instruction 1. Instruction level parallelism is therefore not an option in this example.
[1]Anti-dependency
An anti-dependency, also known as write-after-read (WAR), occurs when an instruction requires a value that is later updated. In the following example, instruction 2 anti-depends on instruction 3 — the ordering of these instructions cannot be changed, nor can they be executed in parallel (possibly changing the instruction ordering), as this would affect the final value of A.
1. B = 3 2. A = B + 1 3. B = 7
An anti-dependency is an example of a name dependency. That is, renaming of variables could remove the dependency, as in the next example:
1. B = 3 N. B2 = B 2. A = B2 + 1 3. B = 7
A new variable, B2, has been declared as a copy of B in a new instruction, instruction N. The anti-dependency between 2 and 3 has been removed, meaning that these instructions may now be executed in parallel. However, the modification has introduced a new dependency: instruction 2 is now truly dependent on instruction N, which is truly dependent upon instruction 1. As flow dependencies, these new dependencies are impossible to safely remove.
[1]Output dependency
An output dependency, also known as write-after-write (WAW), occurs when the ordering of instructions will affect the final output value of a variable. In the example below, there is an output dependency between instructions 3 and 1 — changing the ordering of instructions in this example will change the final value of A, thus these instructions cannot be executed in parallel.
1. B = 3 2. A = B + 1 3. B = 7
As with anti-dependencies, output dependencies are name dependencies. That is, they may be removed through renaming of variables, as in the below modification of the above example:
1. B2 = 3 2. A = B2 + 1 3. B = 7
A commonly used naming convention for data dependencies is the following: Read-after-Write or RAW (flow dependency), Write-After-Read or WAR (anti-dependency), or Write-after-Write or WAW (output dependency).
[1]Control Dependency
An instruction B has a control dependency on a preceding instruction A if the outcome of A determines whether B should be executed or not. In the following example, the instruction has a control dependency on instruction . However,  does not depend on because is always executed irrespective of the outcome of .
does not depend on because is always executed irrespective of the outcome of .
S1. if (a == b) S2. a = a + b S3. b = a + b
Intuitively, there is control dependence between two statements A and B if
- B could be possibly executed after A
- The outcome of the execution of A will determine whether B will be executed or not.
A typical example is that there are control dependences between the condition part of an if statement and the statements in its true/false bodies.
A formal definition of control dependence can be presented as follows:
A statement is said to be control dependent on another statement iff
- there exists a path
 from to such that every statement ≠ within will be followed by in each possible path to the end of the program and
from to such that every statement ≠ within will be followed by in each possible path to the end of the program and - will not necessarily be followed by , i.e. there is an execution path from to the end of the program that does not go through .
Expressed with the help of (post-)dominance the two conditions are equivalent to
- post-dominates all
- does not post-dominate
Construction of Control Dependences
Control dependences are essentially the dominance frontier in the reverse graph of the control flow graph (CFG).[2] Thus, one way of constructing them, would be to construct the post-dominance frontier of the CFG, and then reversing it to obtain a control dependence graph.
The following is a pseudo-code for constructing the post-dominance frontier:
for each X in a bottom-up traversal of the dominator tree do: PostDominanceFrontier(X) ← ∅ for each Y ∈ Predecessors(X) do: if immediatePostDominator(Y) ≠ X: then PostDominanceFrontier(X) ← PostDominanceFrontier(X) ∪ {Y} done for each Z ∈ Children(X) do: for each Y ∈ PostDominanceFrontier(Z) do: if immediatePostDominator(Y) ≠ X: then PostDominanceFrontier(X) ← PostDominanceFrontier(X) ∪ {Y} done doneHere, Children(X) is the set of nodes in the CFG that are post-dominated by X, and Predecessors(X) are the set of nodes in the CFG that directly precede X in the CFG.
Once the post-dominance frontier map is computed, reversing it will result in a map from the nodes in the CFG to the nodes that have a control dependence on them.
Implications
Conventional programs are written assuming the sequential execution model. Under this model, instructions execute one after the other, atomically (i.e., at any given point of time only one instruction is executed) and in the order specified by the program.
However, dependencies among statements or instructions may hinder parallelism — parallel execution of multiple instructions, either by a parallelizing compiler or by a processor exploiting instruction-level parallelism. Recklessly executing multiple instructions without considering related dependences may cause danger of getting wrong results, namely hazards.
References
2. ^{{Cite journal|title = An Efficient Method of Computing Static Single Assignment Form|url = http://doi.acm.org/10.1145/75277.75280|publisher = ACM|journal = Proceedings of the 16th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages|date = 1989-01-01|location = New York, NY, USA|isbn = 0897912942|pages = 25–35|series = POPL '89|doi = 10.1145/75277.75280|first = R.|last = Cytron|first2 = J.|last2 = Ferrante|first3 = B. K.|last3 = Rosen|first4 = M. N.|last4 = Wegman|first5 = F. K.|last5 = Zadeck}}
- Enkianthoideae
- Enkianthus campanulatus
- Enkianthus perulatus
- Enki (disambiguation)
- En kille och en tjej
- Enkiri Village: Dead End Survival
- Enkitta Mothathe
- Enklava (film)
- Enko-ji
- En komikers uppväxt
- En kommentoi
- En Kongelig Affaere
- En Kongelig Affære
- En kongelig affære
- Enkopings RK
- Enkopings SK HK
- En kort, en lång
- Enkorton
- Enkou
- Enkplatz (Vienna U-Bahn)
- Enkrateia
- ENKS
- Enku Museum
- ENKUR (gene)
- Enkuru