- Specification Dirichlet-multinomial as a compound distribution Dirichlet-multinomial as an urn model
- Properties Moments Matrix notation Aggregation
- Likelihood function For a set of individual outcomes Joint distribution Conditional distribution In a Bayesian network Multiple Dirichlet priors with the same hyperprior Multiple Dirichlet priors with the same hyperprior, with dependent children Multiple Dirichlet priors with shifting prior membership A combined example: LDA topic models A second example: Naive Bayes document clustering
- Related distributions
- Uses
- See also
- References
pdf_image =| cdf_image =| name =Dirichlet-Multinomial| type =mass| parameters =number of trials (positive integer)
| support =
| pdf =
| cdf =| mean =
| median =| mode =| variance =
||
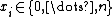
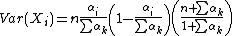
||
skewness =| kurtosis =| entropy =| mgf =
with[1]| char =
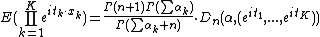
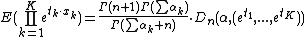
with
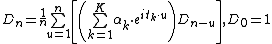 [1]|
[1]|
with
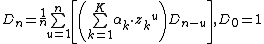 [1]|
[1]|
}}
In probability theory and statistics, the Dirichlet-multinomial distribution is a family of discrete multivariate probability distributions on a finite support of non-negative integers. It is also called the Dirichlet compound multinomial distribution (DCM) or multivariate Pólya distribution (after George Pólya). It is a compound probability distribution, where a probability vector p is drawn from a Dirichlet distribution with parameter vector  , and an observation drawn from a multinomial distribution with probability vector p and number of trials n. The compounding corresponds to a Polya urn scheme. It is frequently encountered in Bayesian statistics, empirical Bayes methods and classical statistics as an overdispersed multinomial distribution.
, and an observation drawn from a multinomial distribution with probability vector p and number of trials n. The compounding corresponds to a Polya urn scheme. It is frequently encountered in Bayesian statistics, empirical Bayes methods and classical statistics as an overdispersed multinomial distribution.
It reduces to the categorical distribution as a special case when n = 1. It also approximates the multinomial distribution arbitrarily well for large α. The Dirichlet-multinomial is a multivariate extension of the beta-binomial distribution, as the multinomial and Dirichlet distributions are multivariate versions of the binomial distribution and beta distributions, respectively.
Specification
Dirichlet-multinomial as a compound distribution
The Dirichlet distribution is a conjugate distribution to the multinomial distribution. This fact leads to an analytically tractable compound distribution.
For a random vector of category counts 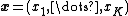 , distributed according to a multinomial distribution, the marginal distribution is obtained by integrating on the distribution for p which can be thought of as a random vector following a Dirichlet distribution:
, distributed according to a multinomial distribution, the marginal distribution is obtained by integrating on the distribution for p which can be thought of as a random vector following a Dirichlet distribution:
which results in the following explicit formula:
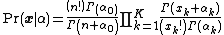
where  is defined as the sum
is defined as the sum 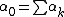 . Another form for this same compound distribution, written more compactly in terms of the beta function, B, is as follows:
. Another form for this same compound distribution, written more compactly in terms of the beta function, B, is as follows:
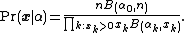
The latter form emphasizes the fact that zero count categories can be ignored in the calculation - a useful fact when the number of categories is very large and sparse (e.g. word counts in documents).
Observe that the pdf is the Beta-binomial distribution when 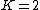 . It can also be shown that it approaches the multinomial distribution as
. It can also be shown that it approaches the multinomial distribution as 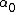 approaches infinity. The parameter governs the degree of overdispersion or burstiness relative to the multinomial. Alternative choices to denote found in the literature are S and A.
approaches infinity. The parameter governs the degree of overdispersion or burstiness relative to the multinomial. Alternative choices to denote found in the literature are S and A.
Dirichlet-multinomial as an urn model
The Dirichlet-multinomial distribution can also be motivated via an urn model for positive integer values of the vector α, known as the Polya urn model. Specifically, imagine an urn containing balls of K colors numbering 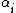 for the ith color, where random draws are made. When a ball is randomly drawn and observed, then two balls of the same color are returned to the urn. If this is performed n times, then the probability of observing the random vector
for the ith color, where random draws are made. When a ball is randomly drawn and observed, then two balls of the same color are returned to the urn. If this is performed n times, then the probability of observing the random vector  of color counts is a Dirichlet-multinomial with parameters n and α.
of color counts is a Dirichlet-multinomial with parameters n and α.
Note that if the random draws are with simple replacement (no balls over and above the observed ball are added to the urn), then the distribution follows a multinomial distribution and if the random draws are made without replacement, the distribution follows a multivariate hypergeometric distribution.
Properties
Moments
Once again, let and let 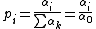 , then the expected number of times the outcome i was observed over n trials is
, then the expected number of times the outcome i was observed over n trials is
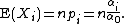
The covariance matrix is as follows. Each diagonal entry is the variance of a beta-binomially distributed random variable, and is therefore
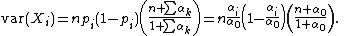
The off-diagonal entries are the covariances:
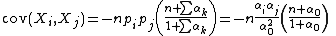
for i, j distinct.
All covariances are negative because for fixed n, an increase in one component of a Dirichlet-multinomial vector requires a decrease in another component.
This is a K × K positive-semidefinite matrix of rank K − 1.
The entries of the corresponding correlation matrix are
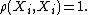
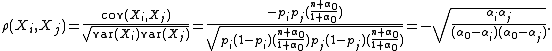
Note that the sample size drops out of this expression.
Each of the k components separately has a beta-binomial distribution.
The support of the Dirichlet-multinomial distribution is the set
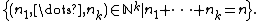
Its number of elements is
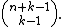
Matrix notation
In matrix notation,
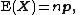
and
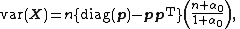
with {{math|pT}} = the row vector transpose of the column vector {{math|p}}. Letting
, we can write alternatively
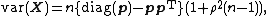
The parameter 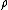 is known as the "intra class" or "intra cluster" correlation. It is this positive correlation which gives rise to overdispersion relative to the multinomial distribution.
is known as the "intra class" or "intra cluster" correlation. It is this positive correlation which gives rise to overdispersion relative to the multinomial distribution.
Aggregation
If
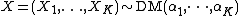
then, if the random variables with subscripts i and j are dropped from the vector and replaced by their sum,
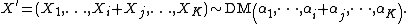
This aggregation property may be used to derive the marginal distribution of  mentioned above.
mentioned above.
Likelihood function
Conceptually, we are making N independent draws from a categorical distribution with K categories. Let us represent the independent draws as random categorical variables  for
for 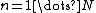 . Let us denote the number of times a particular category
. Let us denote the number of times a particular category  has been seen (for
has been seen (for 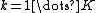 ) among all the categorical variables as
) among all the categorical variables as  . Note that
. Note that 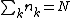 . Then, we have two separate views onto this problem:
. Then, we have two separate views onto this problem:
- A set of
 categorical variables
categorical variables 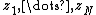 .
. - A single vector-valued variable
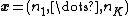 , distributed according to a multinomial distribution.
, distributed according to a multinomial distribution.
The former case is a set of random variables specifying each individual outcome, while the latter is a variable specifying the number of outcomes of each of the K categories. The distinction is important, as the two cases have correspondingly different probability distributions.
The parameter of the categorical distribution is 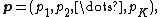 where
where  is the probability to draw value ;
is the probability to draw value ;  is likewise the parameter of the multinomial distribution
is likewise the parameter of the multinomial distribution 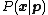 . Rather than specifying directly, we give it a conjugate prior distribution, and hence it is drawn from a Dirichlet distribution with parameter vector
. Rather than specifying directly, we give it a conjugate prior distribution, and hence it is drawn from a Dirichlet distribution with parameter vector 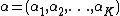 .
.
By integrating out , we obtain a compound distribution. However, the form of the distribution is different depending on which view we take.
For a set of individual outcomes
Joint distribution
For categorical variables 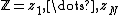 , the marginal joint distribution is obtained by integrating out :
, the marginal joint distribution is obtained by integrating out :
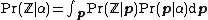
which results in the following explicit formula:
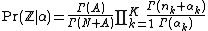
where  is the gamma function, with
is the gamma function, with
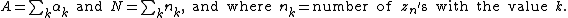
Note that, although the variables do not appear explicitly in the above formula, they enter in through the values.
Conditional distribution
Another useful formula, particularly in the context of Gibbs sampling, asks what the conditional density of a given variable is, conditioned on all the other variables (which we will denote 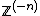 ). It turns out to have an extremely simple form:
). It turns out to have an extremely simple form:
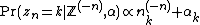
where 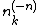 specifies the number of counts of category seen in all variables other than .
specifies the number of counts of category seen in all variables other than .
It may be useful to show how to derive this formula. In general, conditional distributions are proportional to the corresponding joint distributions, so we simply start with the above formula for the joint distribution of all the values and then eliminate any factors not dependent on the particular in question. To do this, we make use of the notation defined above, and note that
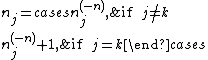
We also use the fact that
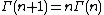
Then:
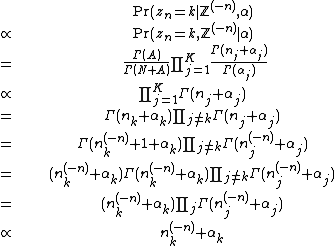
In general, it is not necessary to worry about the normalizing constant at the time of deriving the equations for conditional distributions. The normalizing constant will be determined as part of the algorithm for sampling from the distribution (see Categorical distribution#Sampling). However, when the conditional distribution is written in the simple form above, it turns out that the normalizing constant assumes a simple form:
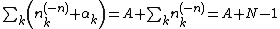
Hence
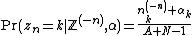
This formula is closely related to the Chinese restaurant process, which results from taking the limit as 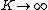 .
.
In a Bayesian network
In a larger Bayesian network in which categorical (or so-called "multinomial") distributions occur with Dirichlet distribution priors as part of a larger network, all Dirichlet priors can be collapsed provided that the only nodes depending on them are categorical distributions. The collapsing happens for each Dirichlet-distribution node separately from the others, and occurs regardless of any other nodes that may depend on the categorical distributions. It also occurs regardless of whether the categorical distributions depend on nodes additional to the Dirichlet priors (although in such a case, those other nodes must remain as additional conditioning factors). Essentially, all of the categorical distributions depending on a given Dirichlet-distribution node become connected into a single Dirichlet-multinomial joint distribution defined by the above formula. The joint distribution as defined this way will depend on the parent(s) of the integrated-out Dirichet prior nodes, as well as any parent(s) of the categorical nodes other than the Dirichlet prior nodes themselves.
In the following sections, we discuss different configurations commonly found in Bayesian networks. We repeat the probability density from above, and define it using the symbol 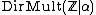 :
:
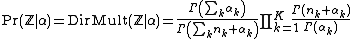
Multiple Dirichlet priors with the same hyperprior
Imagine we have a hierarchical model as follows:
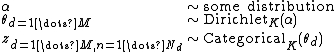
In cases like this, we have multiple Dirichet priors, each of which generates some number of categorical observations (possibly a different number for each prior). The fact that they are all dependent on the same hyperprior, even if this is a random variable as above, makes no difference. The effect of integrating out a Dirichlet prior links the categorical variables attached to that prior, whose joint distribution simply inherits any conditioning factors of the Dirichlet prior. The fact that multiple priors may share a hyperprior makes no difference:
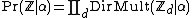
where  is simply the collection of categorical variables dependent on prior d.
is simply the collection of categorical variables dependent on prior d.
Accordingly, the conditional probability distribution can be written as follows:
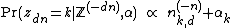
where 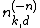 specifically means the number of variables among the set , excluding
specifically means the number of variables among the set , excluding 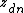 itself, that have the value .
itself, that have the value .
Note in particular that we need to count only the variables having the value k that are tied together to the variable in question through having the same prior. We do not want to count any other variables also having the value k.
Multiple Dirichlet priors with the same hyperprior, with dependent children
Now imagine a slightly more complicated hierarchical model as follows:
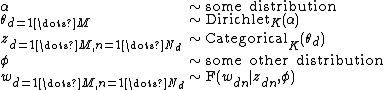
This model is the same as above, but in addition, each of the categorical variables has a child variable dependent on it. This is typical of a mixture model.
Again, in the joint distribution, only the categorical variables dependent on the same prior are linked into a single Dirichlet-multinomial:
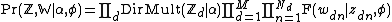
The conditional distribution of the categorical variables dependent only on their parents and ancestors would have the identical form as above in the simpler case. However, in Gibbs sampling it is necessary to determine the conditional distribution of a given node dependent not only on  and ancestors such as
and ancestors such as  but on all the other parameters.
but on all the other parameters.
Note however that we derived the simplified expression for the conditional distribution above simply by rewriting the expression for the joint probability and removing constant factors. Hence, the same simplification would apply in a larger joint probability expression such as the one in this model, composed of Dirichlet-multinomial densities plus factors for many other random variables dependent on the values of the categorical variables.
This yields the following:
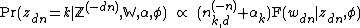
Here the probability density of  appears directly. To do random sampling over , we would compute the unnormalized probabilities for all K possibilities for using the above formula, then normalize them and proceed as normal using the algorithm described in the categorical distribution article.
appears directly. To do random sampling over , we would compute the unnormalized probabilities for all K possibilities for using the above formula, then normalize them and proceed as normal using the algorithm described in the categorical distribution article.
NOTE: Correctly speaking, the additional factor that appears in the conditional distribution is derived not from the model specification but directly from the joint distribution. This distinction is important when considering models where a given node with Dirichlet-prior parent has multiple dependent children, particularly when those children are dependent on each other (e.g. if they share a parent that is collapsed out). This is discussed more below.
Multiple Dirichlet priors with shifting prior membership
Now imagine we have a hierarchical model as follows:

Here we have a tricky situation where we have multiple Dirichlet priors as before and a set of dependent categorical variables, but the relationship between the priors and dependent variables isn't fixed, unlike before. Instead, the choice of which prior to use is dependent on another random categorical variable. This occurs, for example, in topic models, and indeed the names of the variables above are meant to correspond to those in latent Dirichlet allocation. In this case, the set 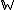 is a set of words, each of which is drawn from one of
is a set of words, each of which is drawn from one of  possible topics, where each topic is a Dirichlet prior over a vocabulary of
possible topics, where each topic is a Dirichlet prior over a vocabulary of  possible words, specifying the frequency of different words in the topic. However, the topic membership of a given word isn't fixed; rather, it's determined from a set of latent variables
possible words, specifying the frequency of different words in the topic. However, the topic membership of a given word isn't fixed; rather, it's determined from a set of latent variables 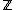 . There is one latent variable per word, a -dimensional categorical variable specifying the topic the word belongs to.
. There is one latent variable per word, a -dimensional categorical variable specifying the topic the word belongs to.
In this case, all variables dependent on a given prior are tied together (i.e. correlated) in a group, as before — specifically, all words belonging to a given topic are linked. In this case, however, the group membership shifts, in that the words are not fixed to a given topic but the topic depends on the value of a latent variable associated with the word. However, note that the definition of the Dirichlet-multinomial density doesn't actually depend on the number of categorical variables in a group (i.e. the number of words in the document generated from a given topic), but only on the counts of how many variables in the group have a given value (i.e. among all the word tokens generated from a given topic, how many of them are a given word). Hence, we can still write an explicit formula for the joint distribution:
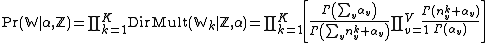
Here we use the notation 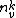 to denote the number of word tokens whose value is word symbol v and which belong to topic k.
to denote the number of word tokens whose value is word symbol v and which belong to topic k.
The conditional distribution still has the same form:
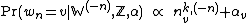
Here again, only the categorical variables for words belonging to a given topic are linked (even though this linking will depend on the assignments of the latent variables), and hence the word counts need to be over only the words generated by a given topic. Hence the symbol 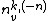 , which is the count of words tokens having the word symbol v, but only among those generated by topic k, and excluding the word itself whose distribution is being described.
, which is the count of words tokens having the word symbol v, but only among those generated by topic k, and excluding the word itself whose distribution is being described.
(Note that the reason why excluding the word itself is necessary, and why it even makes sense at all, is that in a Gibbs sampling context, we repeatedly resample the values of each random variable, after having run through and sampled all previous variables. Hence the variable will already have a value, and we need to exclude this existing value from the various counts that we make use of.)
A combined example: LDA topic models
We now show how to combine some of the above scenarios to demonstrate how to Gibbs sample a real-world model, specifically a smoothed latent Dirichlet allocation (LDA) topic model.
The model is as follows:

Essentially we combine the previous three scenarios: We have categorical variables dependent on multiple priors sharing a hyperprior; we have categorical variables with dependent children (the latent variable topic identities); and we have categorical variables with shifting membership in multiple priors sharing a hyperprior. Note also that in the standard LDA model, the words are completely observed, and hence we never need to resample them. (However, Gibbs sampling would equally be possible if only some or none of the words were observed. In such a case, we would want to initialize the distribution over the words in some reasonable fashion — e.g. from the output of some process that generates sentences, such as a machine translation model — in order for the resulting posterior latent variable distributions to make any sense.)
Using the above formulas, we can write down the conditional probabilities directly:
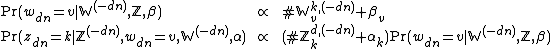
Here we have defined the counts more explicitly to clearly separate counts of words and counts of topics:
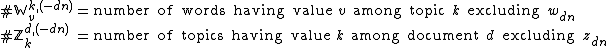
Note that, as in the scenario above with categorical variables with dependent children, the conditional probability of those dependent children appears in the definition of the parent's conditional probability. In this case, each latent variable has only a single dependent child word, so only one such term appears. (If there were multiple dependent children, all would have to appear in the parent's conditional probability, regardless of whether there was overlap between different parents and the same children, i.e. regardless of whether the dependent children of a given parent also have other parents. In a case where a child has multiple parents, the conditional probability for that child appears in the conditional probability definition of each of its parents.)
Note, critically, however, that the definition above specifies only the unnormalized conditional probability of the words, while the topic conditional probability requires the actual (i.e. normalized) probability. Hence we have to normalize by summing over all word symbols:
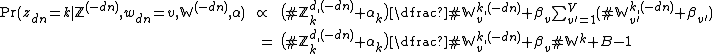
where

It's also worth making another point in detail, which concerns the second factor above in the conditional probability. Remember that the conditional distribution in general is derived from the joint distribution, and simplified by removing terms not dependent on the domain of the conditional (the part on the left side of the vertical bar). When a node  has dependent children, there will be one or more factors
has dependent children, there will be one or more factors 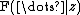 in the joint distribution that are dependent on . Usually there is one factor for each dependent node, and it has the same density function as the distribution appearing the mathematical definition. However, if a dependent node has another parent as well (a co-parent), and that co-parent is collapsed out, then the node will become dependent on all other nodes sharing that co-parent, and in place of multiple terms for each such node, the joint distribution will have only one joint term. We have exactly that situation here. Even though has only one child
in the joint distribution that are dependent on . Usually there is one factor for each dependent node, and it has the same density function as the distribution appearing the mathematical definition. However, if a dependent node has another parent as well (a co-parent), and that co-parent is collapsed out, then the node will become dependent on all other nodes sharing that co-parent, and in place of multiple terms for each such node, the joint distribution will have only one joint term. We have exactly that situation here. Even though has only one child 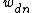 , that child has a Dirichlet co-parent that we have collapsed out, which induces a Dirichlet-multinomial over the entire set of nodes
, that child has a Dirichlet co-parent that we have collapsed out, which induces a Dirichlet-multinomial over the entire set of nodes 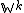 .
.
It happens in this case that this issue does not cause major problems, precisely because of the one-to-one relationship between and . We can rewrite the joint distribution as follows:
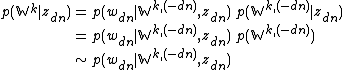
where we note that in the set 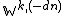 (i.e. the set of nodes excluding ), none of the nodes have as a parent. Hence it can be eliminated as a conditioning factor (line 2), meaning that the entire factor can be eliminated from the conditional distribution (line 3).
(i.e. the set of nodes excluding ), none of the nodes have as a parent. Hence it can be eliminated as a conditioning factor (line 2), meaning that the entire factor can be eliminated from the conditional distribution (line 3).
A second example: Naive Bayes document clustering
Here is another model, with a different set of issues. This is an implementation of an unsupervised Naive Bayes model for document clustering. That is, we would like to classify documents into multiple categories (e.g. "spam" or "non-spam", or "scientific journal article", "newspaper article about finance", "newspaper article about politics", "love letter") based on textual content. However, we don't already know the correct category of any documents; instead, we want to cluster them based on mutual similarities. (For example, a set of scientific articles will tend to be similar to each other in word use but very different from a set of love letters.) This is a type of unsupervised learning. (The same technique can be used for doing semi-supervised learning, i.e. where we know the correct category of some fraction of the documents and would like to use this knowledge to help in clustering the remaining documents.)
The model is as follows:

In many ways, this model is very similar to the LDA topic model described above, but it assumes one topic per document rather than one topic per word, with a document consisting of a mixture of topics. This can be seen clearly in the above model, which is identical to the LDA model except that there is only one latent variable per document instead of one per word. Once again, we assume that we are collapsing all of the Dirichlet priors.
The conditional probability for a given word is almost identical to the LDA case. Once again, all words generated by the same Dirichlet prior are interdependent. In this case, this means the words of all documents having a given label — again, this can vary depending on the label assignments, but all we care about is the total counts. Hence:
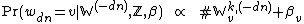
where
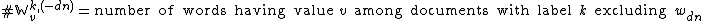
However, there is a critical difference in the conditional distribution of the latent variables for the label assignments, which is that a given label variable has multiple children nodes instead of just one — in particular, the nodes for all the words in the label's document. This relates closely to the discussion above about the factor 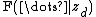 that stems from the joint distribution. In this case, the joint distribution needs to be taken over all words in all documents containing a label assignment equal to the value of
that stems from the joint distribution. In this case, the joint distribution needs to be taken over all words in all documents containing a label assignment equal to the value of 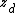 , and has the value of a Dirichlet-multinomial distribution. Furthermore, we cannot reduce this joint distribution down to a conditional distribution over a single word. Rather, we can reduce it down only to a smaller joint conditional distribution over the words in the document for the label in question, and hence we cannot simplify it using the trick above that yields a simple sum of expected count and prior. Although it is in fact possible to rewrite it as a product of such individual sums, the number of factors is very large, and is not clearly more efficient than directly computing the Dirichlet-multinomial distribution probability.
, and has the value of a Dirichlet-multinomial distribution. Furthermore, we cannot reduce this joint distribution down to a conditional distribution over a single word. Rather, we can reduce it down only to a smaller joint conditional distribution over the words in the document for the label in question, and hence we cannot simplify it using the trick above that yields a simple sum of expected count and prior. Although it is in fact possible to rewrite it as a product of such individual sums, the number of factors is very large, and is not clearly more efficient than directly computing the Dirichlet-multinomial distribution probability.
Related distributions
The one-dimensional version of the Dirichlet-multinomial distribution is known as the Beta-binomial distribution.
Uses
The Dirichlet-multinomial distribution is used in automated document classification and clustering, genetics, economy, combat modeling, and quantitative marketing.
{{more footnotes|date=June 2012}}See also
- Beta-binomial distribution
- Chinese restaurant process
- Dirichlet process
- Generalized Dirichlet distribution
- Krichevsky–Trofimov estimator
References
- Elkan, C. (2006) Clustering documents with an exponential-family approximation of the Dirichlet compound multinomial distribution. ICML, 289-296
- Johnson, N. L., Kotz, S. and Balakrishnan, N. (1997) Discrete multivariate distributions (Vol. 165). New York: Wiley.
- Kvam, P. and Day, D. (2001) The multivariate Polya distribution in combat modeling. Naval Research Logistics, 48, 1-17
- Madsen, RE., Kauchak, D. and Elkan, C. (2005) Modeling Word Burstiness Using the Dirichlet Distribution. ICML, 545-552
- Minka, T. (2003) Estimating a Dirichlet distribution. Technical report Microsoft Research. Includes Matlab code for fitting distributions to data.
- Mosimann, J. E. (1962) [https://www.jstor.org/stable/2333468 On the compound multinomial distribution, the multivariate β-distribution, and correlations among proportions]. Biometrika, 49(1-2), 65-82.
- Wagner, U. and Taudes, A. (1986) A Multivariate Polya Model of Brand Choice and Purchase Incidence. Marketing Science, 5(3), 219-244.
- Lycee Francais International Marguerite Duras
- Lycee Francais International M. Pagnol
- Lycee Francais International Rochambeau
- Lycee francais international Rochambeau
- Lycee francais international Victor-Segalen
- Lycee francais international Victor Segalen
- Lycee Francais International Victor Segalen
- Lycee Francais Jacques-Prevert
- Lycee francais Jacques-Prevert
- Lycee Francais Jacques Prevert
- Lycee francais Jacques Prevert
- Lycee francais Jacques PREVERT d'Accra
- Lycee francais Jacques Prevert de Saly
- Lycee Francais Jacques Prevert de Saly
- Lycee francais Jacques PREVERT d’Accra
- Lycee francais Jean-Giono
- Lycee Francais Jean-Giono
- Lycee Francais Jean Giono
- Lycee francais Jean Giono Turin
- Lycee Francais Jean Giono Turin
- Lycee francais Jean-Marie Gustave Le Clezio
- Lycee francais Jean Marie Gustave Le CLEZIO
- Lycee francais Jean Marie Gustave Le Clezio
- Lycee Francais Jean Marie Gustave Le Clezio
- Lycee Francais Jean-Marie Gustave Le Clezio