- Estimation of distribution algorithms (EDAs)
- Univariate factorizations Univariate marginal distribution algorithm (UMDA) Population-based incremental learning (PBIL) Compact genetic algorithm (cGA)
- Bivariate factorizations Mutual information maximizing input clustering (MIMIC) Bivariate marginal distribution algorithm (BMDA)
- Multivariate factorizations Extended compact genetic algorithm (eCGA) Bayesian optimization algorithm (BOA) Linkage-tree Genetic Algorithm (LTGA)
- Other
- Related
- References
EDAs belong to the class of evolutionary algorithms. The main difference between EDAs and most conventional evolutionary algorithms is that evolutionary algorithms generate new candidate solutions using an implicit distribution defined by one or more variation operators, whereas EDAs use an explicit probability distribution encoded by a Bayesian network, a multivariate normal distribution, or another model class. Similarly as other evolutionary algorithms, EDAs can be used to solve optimization problems defined over a number of representations from vectors to LISP style S expressions, and the quality of candidate solutions is often evaluated using one or more objective functions.
The general procedure of an EDA is outlined in the following:
t = 0
initialize model M(0) to represent uniform distribution over admissible solutions
while (termination criteria not met)
P = generate N>0 candidate solutions by sampling M(t) F = evaluate all candidate solutions in P M(t+1) = adjust_model(P,F,M(t)) t = t + 1
Using explicit probabilistic models in optimization allowed EDAs to feasibly solve optimization problems that were notoriously difficult for most conventional evolutionary algorithms and traditional optimization techniques, such as problems with high levels of epistasis{{Citation needed|date=September 2017}}. Nonetheless, the advantage of EDAs is also that these algorithms provide an optimization practitioner with a series of probabilistic models that reveal a lot of information about the problem being solved. This information can in turn be used to design problem-specific neighborhood operators for local search, to bias future runs of EDAs on a similar problem, or to create an efficient computational model of the problem.
For example, if the population is represented by bit strings of length 4, the EDA can represent the population of promising solution using a single vector of four probabilities (p1, p2, p3, p4) where each component of p defines the probability of that position being a 1. Using this probability vector it is possible to create an arbitrary number of candidate solutions.
Estimation of distribution algorithms (EDAs)
This section describes the models built by some well known EDAs of different levels of complexity. It is always assumed a population  at the generation
at the generation  , a selection operator
, a selection operator  , a model-building operator
, a model-building operator  and a sampling operator
and a sampling operator 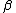 .
.
Univariate factorizations
The most simple EDAs assume that decision variables are independent, i.e.  . Therefore, univariate EDAs rely only on univariate statistics and multivariate distributions must be factorized as the product of
. Therefore, univariate EDAs rely only on univariate statistics and multivariate distributions must be factorized as the product of  univariate probability distributions,
univariate probability distributions,

Such factorizations are used in many different EDAs, next we describe some of them.
Univariate marginal distribution algorithm (UMDA)
The UMDA[5] is a simple EDA that uses an operator  to estimate marginal probabilities from a selected population
to estimate marginal probabilities from a selected population  . By assuming contain
. By assuming contain  elements, produces probabilities:
elements, produces probabilities:

Every UMDA step can be described as follows

Population-based incremental learning (PBIL)
The PBIL,[6] represents the population implicitly by its model, from which it samples new solutions and updates the model. At each generation,  individuals are sampled and
individuals are sampled and  are selected. Such individuals are then used to update the model as follows
are selected. Such individuals are then used to update the model as follows

where  is a parameter defining the learning rate, a small value determines that the previous model
is a parameter defining the learning rate, a small value determines that the previous model  should be only slightly modified by the new solutions sampled. PBIL can be described as
should be only slightly modified by the new solutions sampled. PBIL can be described as

Compact genetic algorithm (cGA)
The CGA,[7] also relies on the implicit populations defined by univariate distributions. At each generation , two individuals  are sampled,
are sampled,  . The population is then sort in decreasing order of fitness,
. The population is then sort in decreasing order of fitness,  , with
, with  being the best and
being the best and  being the worst solution. The CGA estimates univariate probabilities as follows
being the worst solution. The CGA estimates univariate probabilities as follows

where, is a constant defining the learning rate, usually set to  . The CGA can be defined as
. The CGA can be defined as
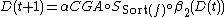
Bivariate factorizations
Although univariate models can be computed efficiently, in many cases they are not representative enough to provide better performance than GAs. In order to overcome such a drawback, the use of bivariate factorizations was proposed in the EDA community, in which dependencies between pairs of variables could be modeled. A bivariate factorization can be defined as follows, where  contains a possible variable dependent to
contains a possible variable dependent to  , i.e.
, i.e.  .
.
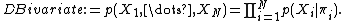
Bivariate and multivariate distributions are usually represented as Probabilistic Graphical Models (graphs), in which edges denote statistical dependencies (or conditional probabilities) and vertices denote variables. To learn the structure of a PGM from data linkage-learning is employed.
Mutual information maximizing input clustering (MIMIC)
The MIMIC[8] factorizes the joint probability distribution in a chain-like model representing successive dependencies between variables. It finds a permutation of the decision variables,  , such that
, such that  minimizes the Kullback-Leibler divergence in relation to the true probability distribution, i.e.
minimizes the Kullback-Leibler divergence in relation to the true probability distribution, i.e.  . MIMIC models a distribution
. MIMIC models a distribution

New solutions are sampled from the leftmost to the rightmost variable, the first is generated independently and the others according to conditional probabilities. Since the estimated distribution must be recomputed each generation, MIMIC uses concrete populations in the following way
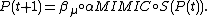
Bivariate marginal distribution algorithm (BMDA)
The BMDA[9] factorizes the joint probability distribution in bivariate distributions. First, a randomly chosen variable is added as a node in a graph, the most dependent variable to one of those in the graph is chosen among those not yet in the graph, this procedure is repeated until no remaining variable depends on any variable in the graph (verified according to a threshold value).
The resulting model is a forest with multiple trees rooted at nodes  . Considering
. Considering  the non-root variables, BMDA estimates a factorized distribution in which the root variables can be sampled independently, whereas all the others must be conditioned to the parent variable .
the non-root variables, BMDA estimates a factorized distribution in which the root variables can be sampled independently, whereas all the others must be conditioned to the parent variable .

Each step of BMDA is defined as follows

Multivariate factorizations
The next stage of EDAs development was the use of multivariate factorizations. In this case, the joint probability distribution is usually factorized in a number of components of limited size  .
.

The learning of PGMs encoding multivariate distributions is a computationally expensive task, therefore, it is usual for EDAs to estimate multivariate statistics from bivariate statistics. Such relaxation allows PGM to be built in polynomial time in ; however, it also limits the generality of such EDAs.
Extended compact genetic algorithm (eCGA)
The ECGA[10] was one of the first EDA to employ multivariate factorizations, in which high-order dependencies among decision variables can be modeled. Its approach factorizes the joint probability distribution in the product of multivariate marginal distributions. Assume  is a set of subsets, in which every
is a set of subsets, in which every  is a linkage set, containing
is a linkage set, containing 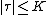 variables. The factorized joint probability distribution is represented as follows
variables. The factorized joint probability distribution is represented as follows

The ECGA popularized the term "linkage-learning" as denoting procedures that identify linkage sets. Its linkage-learning procedure relies on two measures: (1) the Model Complexity (MC) and (2) the Compressed Population Complexity (CPC). The MC quantifies the model representation size in terms of number of bits required to store all the marginal probabilities

The CPC, on the other hand, quantifies the data compression in terms of entropy of the marginal distribution over all partitions, where is the selected population size,  is the number of decision variables in the linkage set
is the number of decision variables in the linkage set  and
and 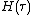 is the joint entropy of the variables in
is the joint entropy of the variables in

The linkage-learning in ECGA works as follows: (1) Insert each variable in a cluster, (2) compute CCC = MC + CPC of the current linkage sets, (3) verify the increase on CCC provided by joining pairs of clusters, (4) effectively joins those clusters with highest CCC improvement. This procedure is repeated until no CCC improvements are possible and produces a linkage model  . The ECGA works with concrete populations, therefore, using the factorized distribution modeled by ECGA, it can be described as
. The ECGA works with concrete populations, therefore, using the factorized distribution modeled by ECGA, it can be described as

Bayesian optimization algorithm (BOA)
The BOA[11][12][13] uses Bayesian networks to model and sample promising solutions. Bayesian networks are directed acyclic graphs, with nodes representing variables and edges representing conditional probabilities between pair of variables. The value of a variable  can be conditioned on a maximum of
can be conditioned on a maximum of  other variables, defined in . BOA builds a PGM encoding a factorized joint distribution, in which the parameters of the network, i.e. the conditional probabilities, are estimated from the selected population using the maximum likelihood estimator.
other variables, defined in . BOA builds a PGM encoding a factorized joint distribution, in which the parameters of the network, i.e. the conditional probabilities, are estimated from the selected population using the maximum likelihood estimator.

The Bayesian network structure, on the other hand, must be built iteratively (linkage-learning). It starts with a network without edges and, at each step, adds the edge which better improves some scoring metric (e.g. Bayesian information criterion (BIC) or Bayesian-Dirichlet metric with likelihood equivalence (BDe)).[14] The scoring metric evaluates the network structure according to its accuracy in modeling the selected population. From the built network, BOA samples new promising solutions as follows: (1) it computes the ancestral ordering for each variable, each node being preceded by its parents; (2) each variable is sampled conditionally to its parents. Given such scenario, every BOA step can be defined as
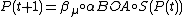
Linkage-tree Genetic Algorithm (LTGA)
The LTGA[15] differs from most EDA in the sense it does not explicitly model a probabilisty distribution but only a linkage model, called linkage-tree. A linkage 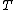 is a set of linkage sets with no probability distribution associated, therefore, there is no way to sample new solutions directly from . The linkage model is a linkage-tree produced stored as a Family of sets (FOS).
is a set of linkage sets with no probability distribution associated, therefore, there is no way to sample new solutions directly from . The linkage model is a linkage-tree produced stored as a Family of sets (FOS).

The linkage-tree learning procedure is a hierarchical clustering algorithm, which work as follows. At each step the two closest clusters 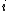 and
and  are merged, this procedure repeats until only one cluster remains, each subtree is stored as a subset
are merged, this procedure repeats until only one cluster remains, each subtree is stored as a subset  .
.
The LTGA uses  to guide an "optimal mixing" procedure which resembles a recombination operator but only accepts improving moves. We denote it as
to guide an "optimal mixing" procedure which resembles a recombination operator but only accepts improving moves. We denote it as 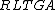 , where the notation
, where the notation 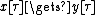 indicates the transfer of the genetic material indexed by from
indicates the transfer of the genetic material indexed by from  to
to  .
.
Input: A family of subsets. '''for each'''

 :=
:= 
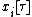 :=
:= 
 {{algorithm-end}}
{{algorithm-end}}The LTGA does not implement typical selection operators, instead, selection is performed during recombination. Similar ideas have been usually applied into local-search heuristics and, in this sense, the LTGA can be seen as an hybrid method. In summary, one step of the LTGA is defined as
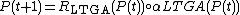
Other
- Probability collectives (PC)[16][17]
- Hill climbing with learning (HCwL)[18]
- Estimation of multivariate normal algorithm (EMNA){{Citation needed|date=June 2018}}
- Estimation of Bayesian networks algorithm (EBNA){{Citation needed|date=June 2018}}
- Stochastic hill climbing with learning by vectors of normal distributions (SHCLVND)[19]
- Real-coded PBIL{{Citation needed|date=June 2018}}
- Selfish Gene Algorithm (SG)[20]
- Compact Differential Evolution (cDE)[21] and its variants[22][23][24][25][26][27]
- Compact Particle Swarm Optimization (cPSO)[28]
- Compact Bacterial Foraging Optimization (cBFO)[29]
- Probabilistic incremental program evolution (PIPE)[30]
- Estimation of Gaussian networks algorithm (EGNA){{Citation needed|date=June 2018}}
- Estimation multivariate normal algorithm with thresheld convergence[31]
- Dependency Structure Matrix Genetic Algorithm (DSMGA)[32][33]
Related
- CMA-ES
- Cross-entropy method
References
2. ^{{cite book|author1=Pedro Larrañaga|author2=Jose A. Lozano|title=Estimation of Distribution Algorithms a New Tool for Evolutionary Computation|date=2002|publisher=Springer US|location=Boston, MA|isbn=978-1-4615-1539-5}}
3. ^{{cite book|author1=Jose A. Lozano|author2=Larrañaga, P.|author3=Inza, I.|author4=Bengoetxea, E.|title=Towards a new evolutionary computation advances in the estimation of distribution algorithms|date=2006|publisher=Springer|location=Berlin|isbn=978-3-540-32494-2}}
4. ^{{cite book|last1=Pelikan|first1=Martin|last2=Sastry|first2=Kumara|last3=Cantú-Paz|first3=Erick|title=Scalable optimization via probabilistic modeling : from algorithms to applications ; with 26 tables|date=2006|publisher=Springer|location=Berlin|isbn=978-3540349532}}
5. ^{{cite journal|last1=Mühlenbein|first1=Heinz|title=The Equation for Response to Selection and Its Use for Prediction|journal=Evol. Computation|date=1 September 1997|volume=5|issue=3|pages=303–346|doi=10.1162/evco.1997.5.3.303|url=http://dl.acm.org/citation.cfm?id=1326756|issn=1063-6560}}
6. ^{{cite journal|last1=Baluja|first1=Shummet|title=Population-Based Incremental Learning: A Method for Integrating Genetic Search Based Function Optimization and Competitive Learning|date=1 January 1994|url=http://dl.acm.org/citation.cfm?id=865123|publisher=Carnegie Mellon University}}
7. ^{{cite journal|last1=Harik|first1=G.R.|last2=Lobo|first2=F.G.|last3=Goldberg|first3=D.E.|title=The compact genetic algorithm|journal=IEEE Transactions on Evolutionary Computation|date=1999|volume=3|issue=4|pages=287–297|doi=10.1109/4235.797971}}
8. ^{{cite journal|last1=Bonet|first1=Jeremy S. De|last2=Isbell|first2=Charles L.|last3=Viola|first3=Paul|title=MIMIC: Finding Optima by Estimating Probability Densities|journal=Advances in Neural Information Processing Systems|date=1 January 1996|pages=424|citeseerx=10.1.1.47.6497}}
9. ^{{cite book|last1=Pelikan|first1=Martin|last2=Muehlenbein|first2=Heinz|title=The Bivariate Marginal Distribution Algorithm|journal=Advances in Soft Computing|date=1 January 1999|pages=521–535|doi=10.1007/978-1-4471-0819-1_39|isbn=978-1-85233-062-0|citeseerx=10.1.1.55.1151}}
10. ^{{cite book|last1=Harik|first1=Georges Raif|title=Learning Gene Linkage to Efficiently Solve Problems of Bounded Difficulty Using Genetic Algorithms|publisher=University of Michigan|url=http://dl.acm.org/citation.cfm?id=269517|year=1997}}
11. ^{{cite journal|last1=Pelikan|first1=Martin|last2=Goldberg|first2=David E.|last3=Cantu-Paz|first3=Erick|title=BOA: The Bayesian Optimization Algorithm|date=1 January 1999|pages=525–532|publisher=Morgan Kaufmann|citeseerx=10.1.1.46.8131}}
12. ^{{cite book|last1=Pelikan|first1=Martin|title=Hierarchical Bayesian optimization algorithm : toward a new generation of evolutionary algorithms|date=2005|publisher=Springer|location=Berlin [u.a.]|isbn=978-3-540-23774-7|edition=1st}}
13. ^{{cite journal|last1=Wolpert|first1=David H.|last2=Rajnarayan|first2=Dev|title=Using Machine Learning to Improve Stochastic Optimization|journal=Proceedings of the 17th AAAI Conference on Late-Breaking Developments in the Field of Artificial Intelligence|date=1 January 2013|pages=146–148|url=http://dl.acm.org/citation.cfm?id=2908286.2908335|series=Aaaiws'13-17}}
14. ^{{cite journal|last1=Larrañaga|first1=Pedro|last2=Karshenas|first2=Hossein|last3=Bielza|first3=Concha|last4=Santana|first4=Roberto|title=A review on probabilistic graphical models in evolutionary computation|journal=Journal of Heuristics|date=21 August 2012|volume=18|issue=5|pages=795–819|doi=10.1007/s10732-012-9208-4|url=http://oa.upm.es/15826/}}
15. ^{{cite book|last1=Thierens|first1=Dirk|title=The Linkage Tree Genetic Algorithm|journal=Parallel Problem Solving from Nature, PPSN XI|date=11 September 2010|pages=264–273|doi=10.1007/978-3-642-15844-5_27|isbn=978-3-642-15843-8}}
16. ^{{cite journal|last1=WOLPERT|first1=DAVID H.|last2=STRAUSS|first2=CHARLIE E. M.|last3=RAJNARAYAN|first3=DEV|title=ADVANCES IN DISTRIBUTED OPTIMIZATION USING PROBABILITY COLLECTIVES|journal=Advances in Complex Systems|date=December 2006|volume=09|issue=4|pages=383–436|doi=10.1142/S0219525906000884|citeseerx=10.1.1.154.6395}}
17. ^{{cite journal|last1=Pelikan|first1=Martin|last2=Goldberg|first2=David E.|last3=Lobo|first3=Fernando G.|title=A Survey of Optimization by Building and Using Probabilistic Models|journal=Computational Optimization and Applications|date=2002|volume=21|issue=1|pages=5–20|doi=10.1023/A:1013500812258}}
18. ^{{Cite journal|last=Rudlof|first=Stephan|last2=Köppen|first2=Mario|date=1997|title=Stochastic Hill Climbing with Learning by Vectors of Normal Distributions|url=http://citeseerx.ist.psu.edu/viewdoc/similar?doi=10.1.1.19.3536&type=ab|language=en}}
19. ^{{Cite journal|last=Rudlof|first=Stephan|last2=Köppen|first2=Mario|date=1997|title=Stochastic Hill Climbing with Learning by Vectors of Normal Distributions|pages=60––70|citeseerx=10.1.1.19.3536}}
20. ^{{Cite book|last=Corno|first=Fulvio|last2=Reorda|first2=Matteo Sonza|last3=Squillero|first3=Giovanni|date=1998-02-27|title=The selfish gene algorithm: a new evolutionary optimization strategy|publisher=ACM|pages=349–355|doi=10.1145/330560.330838|isbn=978-0897919692}}
21. ^{{Cite journal|last=Mininno|first=Ernesto|last2=Neri|first2=Ferrante|last3=Cupertino|first3=Francesco|last4=Naso|first4=David|date=2011|title=Compact Differential Evolution|journal=IEEE Transactions on Evolutionary Computation|language=en-US|volume=15|issue=1|pages=32–54|doi=10.1109/tevc.2010.2058120|issn=1089-778X}}
22. ^{{Cite journal|last=Iacca|first=Giovanni|last2=Caraffini|first2=Fabio|last3=Neri|first3=Ferrante|date=2012|title=Compact Differential Evolution Light: High Performance Despite Limited Memory Requirement and Modest Computational Overhead|journal=Journal of Computer Science and Technology|language=en|volume=27|issue=5|pages=1056–1076|doi=10.1007/s11390-012-1284-2|issn=1000-9000}}
23. ^{{Citation|last=Iacca|first=Giovanni|title=Opposition-Based Learning in Compact Differential Evolution|date=2011|last2=Neri|first2=Ferrante|last3=Mininno|first3=Ernesto|work=Applications of Evolutionary Computation|pages=264–273|publisher=Springer Berlin Heidelberg|language=en|doi=10.1007/978-3-642-20525-5_27|isbn=9783642205248}}
24. ^{{Cite book|last=Mallipeddi|first=Rammohan|last2=Iacca|first2=Giovanni|last3=Suganthan|first3=Ponnuthurai Nagaratnam|last4=Neri|first4=Ferrante|last5=Mininno|first5=Ernesto|date=2011|title=Ensemble strategies in Compact Differential Evolution|journal=2011 IEEE Congress of Evolutionary Computation (CEC)|language=en-US|publisher=IEEE|volume=|pages=|doi=10.1109/cec.2011.5949857|isbn=9781424478347}}
25. ^{{Cite journal|last=Neri|first=Ferrante|last2=Iacca|first2=Giovanni|last3=Mininno|first3=Ernesto|date=2011|title=Disturbed Exploitation compact Differential Evolution for limited memory optimization problems|journal=Information Sciences|volume=181|issue=12|pages=2469–2487|doi=10.1016/j.ins.2011.02.004|issn=0020-0255}}
26. ^{{Cite book|last=Iacca|first=Giovanni|last2=Mallipeddi|first2=Rammohan|last3=Mininno|first3=Ernesto|last4=Neri|first4=Ferrante|last5=Suganthan|first5=Pannuthurai Nagaratnam|date=2011|title=Global supervision for compact Differential Evolution|journal=2011 IEEE Symposium on Differential Evolution (SDE)|language=en-US|publisher=IEEE|volume=|pages=|doi=10.1109/sde.2011.5952051|isbn=9781612840710}}
27. ^{{Cite book|last=Iacca|first=Giovanni|last2=Mallipeddi|first2=Rammohan|last3=Mininno|first3=Ernesto|last4=Neri|first4=Ferrante|last5=Suganthan|first5=Pannuthurai Nagaratnam|date=2011|title=Super-fit and population size reduction in compact Differential Evolution|journal=2011 IEEE Workshop on Memetic Computing (MC)|language=en-US|publisher=IEEE|volume=|pages=|doi=10.1109/mc.2011.5953633|isbn=9781612840659}}
28. ^{{Cite journal|last=Neri|first=Ferrante|last2=Mininno|first2=Ernesto|last3=Iacca|first3=Giovanni|date=2013|title=Compact Particle Swarm Optimization|journal=Information Sciences|volume=239|pages=96–121|doi=10.1016/j.ins.2013.03.026|issn=0020-0255}}
29. ^{{Citation|last=Iacca|first=Giovanni|title=Compact Bacterial Foraging Optimization|date=2012|last2=Neri|first2=Ferrante|last3=Mininno|first3=Ernesto|work=Swarm and Evolutionary Computation|pages=84–92|publisher=Springer Berlin Heidelberg|language=en|doi=10.1007/978-3-642-29353-5_10|isbn=9783642293528}}
30. ^{{Cite journal|last=Salustowicz|first=null|last2=Schmidhuber|first2=null|date=1997|title=Probabilistic incremental program evolution|journal=Evolutionary Computation|volume=5|issue=2|pages=123–141|issn=1530-9304|pmid=10021756|doi=10.1162/evco.1997.5.2.123}}
31. ^{{Cite book|last=Tamayo-Vera|first=Dania|last2=Bolufe-Rohler|first2=Antonio|last3=Chen|first3=Stephen|date=2016|title=Estimation multivariate normal algorithm with thresheld convergence|journal=2016 IEEE Congress on Evolutionary Computation (CEC)|language=en-US|publisher=IEEE|volume=|pages=|doi=10.1109/cec.2016.7744223|isbn=9781509006236}}
32. ^{{Citation|last=Yu|first=Tian-Li|title=Genetic Algorithm Design Inspired by Organizational Theory: Pilot Study of a Dependency Structure Matrix Driven Genetic Algorithm|date=2003|work=Genetic and Evolutionary Computation — GECCO 2003|pages=1620–1621|publisher=Springer Berlin Heidelberg|language=en|doi=10.1007/3-540-45110-2_54|isbn=9783540406037|last2=Goldberg|first2=David E.|last3=Yassine|first3=Ali|last4=Chen|first4=Ying-Ping}}
33. ^{{Cite book|last=Hsu|first=Shih-Huan|last2=Yu|first2=Tian-Li|date=2015-07-11|title=Optimization by Pairwise Linkage Detection, Incremental Linkage Set, and Restricted / Back Mixing: DSMGA-II|publisher=ACM|pages=519–526|doi=10.1145/2739480.2754737|isbn=9781450334723|arxiv=1807.11669}}
- Ulee Lheue
- Ulegyria
- Uleh Kari Asalem
- Uleh Karim
- Uleiota
- Ulejoe, Tartu
- Ulek Mayang
- Uleksandr Fedenko
- Ulele Spring
- Ulemine Vaika
- Ulemiste Keskus
- Ulemiste Tunnel
- Ulemjiin Chanar
- Ulendo Airlink
- Ulenge Island Front Range Lighthouse
- Ulenge Island Rear Range Lighthouse
- Ulenge Lighthouse
- Uleni
- Ule (surname)
- Uletovski
- Uletovski District
- Uletovskii
- Uletovskii District
- Uletovskii Raion
- Uletovski Raion