- Theoretical background
- Generality
- GAM fitting methods
- The rank reduced framework Bayesian smoothing priors Smoothing parameter estimation
- Software
- Model checking
- Model selection
- Caveats
- See also
- References
- External links
In statistics, a generalized additive model (GAM) is a generalized linear model in which the linear predictor depends linearly on unknown smooth functions of some predictor variables, and interest focuses on inference about these smooth functions.
GAMs were originally developed by Trevor Hastie and Robert Tibshirani[1] to blend properties of generalized linear models with additive models.
The model relates a univariate response variable, Y, to some predictor variables, xi. An exponential family distribution is specified for Y (for example normal, binomial or Poisson distributions) along with a link function g (for example the identity or log functions) relating the expected value of Y to the predictor variables via a structure such as
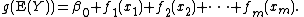
The functions fi may be functions with a specified parametric form (for example a polynomial, or an un-penalized regression spline of a variable) or may be specified non-parametrically, or semi-parametrically, simply as 'smooth functions', to be estimated by non-parametric means. So a typical GAM might use a scatterplot smoothing function, such as a locally weighted mean, for f1(x1), and then use a factor model for f2(x2). This flexibility to allow non-parametric fits with relaxed assumptions on the actual relationship between response and predictor, provides the potential for better fits to data than purely parametric models, but arguably with some loss of interpretability.
Theoretical background
It had been known since the 1950s (via. the Kolmogorov–Arnold representation theorem) that any multivariate function could be represented as sums and compositions of univariate functions.
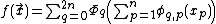
Unfortunately, though the Kolmogorov–Arnold representation theorem asserts the existence of a function of this form, it gives no mechanism whereby one could be constructed. Certain constructive proofs exist, but they tend to require highly complicated (i.e. fractal) functions, and thus are not suitable for modeling approaches. Therefore, the Generalized Additive Model[1] drops the outer sum, and demands instead that the function belong to a simpler class. However the success of the neural networks and their universal approximation properties have shown that more general alternatives exist to GAM.
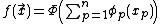
where  is a smooth monotonic function. Writing
is a smooth monotonic function. Writing  for the inverse of , this is traditionally written as
for the inverse of , this is traditionally written as
.
When this function is approximating the expectation of some observed quantity, it could be written as
Which is the standard formulation of a Generalized Additive Model. It was then shown[1] that the backfitting algorithm will always converge for these functions.
Generality
The GAM model class is quite broad, given that smooth function is a rather broad category. For example, a covariate  may be multivariate and the corresponding
may be multivariate and the corresponding  a smooth function of several variables, or might be the function mapping the level of a factor to the value of a random effect. Another example is a varying coefficient (geographic regression) term such as
a smooth function of several variables, or might be the function mapping the level of a factor to the value of a random effect. Another example is a varying coefficient (geographic regression) term such as 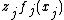 where
where 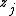 and are both covariates. Or if
and are both covariates. Or if 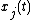 is itself an observation of a function, we might include a term such as
is itself an observation of a function, we might include a term such as 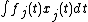 (sometimes known as a signal regression term). could also be a simple parametric function as might be used in any generalized linear model. The model class has been generalized in several directions, notably beyond exponential family response distributions, beyond modelling of only the mean and beyond univariate data[2][3]
(sometimes known as a signal regression term). could also be a simple parametric function as might be used in any generalized linear model. The model class has been generalized in several directions, notably beyond exponential family response distributions, beyond modelling of only the mean and beyond univariate data[2][3]
.[4]
GAM fitting methods
The original GAM fitting method estimated the smooth components of the model using non-parametric smoothers (for example smoothing splines or local linear regression smoothers) via the backfitting algorithm.[1] Backfitting works by iterative smoothing of partial residuals and provides a very general modular estimation method capable of using a wide variety of smoothing methods to estimate the 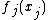 terms. A disadvantage of backfitting is that it is difficult to integrate with the estimation of the degree of smoothness of the model terms, so that in practice the user must set these, or select between a modest set of pre-defined smoothing levels.
terms. A disadvantage of backfitting is that it is difficult to integrate with the estimation of the degree of smoothness of the model terms, so that in practice the user must set these, or select between a modest set of pre-defined smoothing levels.
If the are represented using smoothing splines[5] then the degree of smoothness can be estimated as part of model fitting using generalized cross validation, or by REML (sometimes known as 'GML') which exploits the duality between spline smoothers and Gaussian random effects.[6] This full spline approach carries an  computational cost, where
computational cost, where  is the number of observations for the response variable, rendering it somewhat impractical for moderately large datasets. More recent methods have addressed this computational cost either by up front reduction of the size of the basis used for smoothing (rank reduction)[7][8]
is the number of observations for the response variable, rendering it somewhat impractical for moderately large datasets. More recent methods have addressed this computational cost either by up front reduction of the size of the basis used for smoothing (rank reduction)[7][8]
[10][11] or by finding sparse representations of the smooths using Markov random fields, which are amenable to the use of sparse matrix methods for computation.[12] These more computationally efficient methods use GCV (or AIC or similar) or REML or take a fully Bayesian approach for inference about the degree of smoothness of the model components. Estimating the degree of smoothness via REML can be viewed as an empirical Bayes method.
An alternative approach with particular advantages in high dimensional settings is to use boosting (machine learning), although this typically requires bootstrapping for uncertainty quantification[13]
.[14]
The rank reduced framework
Many modern implementations of GAMs and their extensions are built around the reduced rank smoothing approach, because it allows well founded estimation of the smoothness of the component smooths at comparatively modest computational cost, and also facilitates implementation of a number of model extensions in a way that is more difficult with other methods. At its simplest the idea is to replace the unknown smooth functions in the model with basis expansions

where the 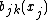 are known basis functions, usually chosen for good approximation theoretic properties (for example B splines or reduced rank thin plate splines), and the
are known basis functions, usually chosen for good approximation theoretic properties (for example B splines or reduced rank thin plate splines), and the 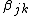 are coefficients to be estimated as part of model fitting. The basis dimension
are coefficients to be estimated as part of model fitting. The basis dimension 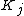 is chosen to be sufficiently large that we expect it to overfit the data to hand (thereby avoiding bias from model over-simplification), but small enough to retain computational efficiency. If
is chosen to be sufficiently large that we expect it to overfit the data to hand (thereby avoiding bias from model over-simplification), but small enough to retain computational efficiency. If 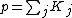 then the computational cost of model estimation this way will be
then the computational cost of model estimation this way will be 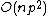 .
.
Notice that the are only identifiable to within an intercept term (we could add any constant to  while subtracting it from
while subtracting it from  without changing the model predictions at all), so identifiability constraints have to be imposed on the smooth terms to remove this ambiguity. Sharpest inference about the is generally obtained by using the sum-to-zero constraints
without changing the model predictions at all), so identifiability constraints have to be imposed on the smooth terms to remove this ambiguity. Sharpest inference about the is generally obtained by using the sum-to-zero constraints
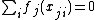
i.e. by insisting that the sum of each the evaluated at its observed covariate values should be zero. Such linear constraints can most easily be imposed by reparametrization at the basis setup stage,[10] so below it is assumed that this has been done.
Having replaced all the in the model with such basis expansions we have turned the GAM into a Generalized linear model (GLM), with a model matrix that simply contains the basis functions evaluated at the observed values. However, because the basis dimensions, , have been chosen to be a somewhat larger than is believed to be necessary for the data, the model is over-parameterized and will overfit the data if estimated as a regular GLM. The solution to this problem is to penalize departure from smoothness in the model fitting process, controlling the weight given to the smoothing penalties using smoothing parameters. For example, consider the situation in which all the smooths are univariate functions. Writing all the parameters in one vector, 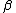 , suppose that
, suppose that  is the deviance (twice the difference between saturated log likelihood and the model log likelihood) for the model. Minimizing the deviance by the usual iteratively re-weighted least squares would result in overfit, so we seek to minimize
is the deviance (twice the difference between saturated log likelihood and the model log likelihood) for the model. Minimizing the deviance by the usual iteratively re-weighted least squares would result in overfit, so we seek to minimize
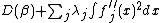
where the integrated square second derivative penalties serve to penalize wiggliness (lack of smoothness) of the during fitting, and the smoothing parameters  control the tradeoff between model goodness of fit and model smoothness. In the example
control the tradeoff between model goodness of fit and model smoothness. In the example 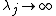 would ensure that the estimate of would be a straight line in .
would ensure that the estimate of would be a straight line in .
Given the basis expansion for each the wiggliness penalties can be expressed as quadratic forms in the model coefficients.[10] That is we can write
,
where 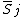 is a matrix of known coefficients computable from the penalty and basis,
is a matrix of known coefficients computable from the penalty and basis,  is the vector of coefficients for , and
is the vector of coefficients for , and  is just padded with zeros so that the second equality holds and we can write the penalty in terms of the full coefficient vector . Many other smoothing penalties can be written in the same way, and given the smoothing parameters the model fitting problem now becomes
is just padded with zeros so that the second equality holds and we can write the penalty in terms of the full coefficient vector . Many other smoothing penalties can be written in the same way, and given the smoothing parameters the model fitting problem now becomes
,
which can be found using a penalized version of the usual iteratively reweighted least squares (IRLS) algorithm for GLMs: the algorithm is unchanged except that the sum of quadratic penalties is added to the working least squared objective at each iteration of the algorithm.
Penalization has several effects on inference, relative to a regular GLM. For one thing the estimates are subject to some smoothing bias, which is the price that must be paid for limiting estimator variance by penalization. However, if smoothing parameters are selected appropriately the (squared) smoothing bias introduced by penalization should be less than the reduction in variance that it produces, so that the net effect is a reduction in mean square estimation error, relative to not penalizing. A related effect of penalization is that the notion of degrees of freedom of a model has to be modified to account for the penalties' action in reducing the coefficients' freedom to vary. For example, if  is the diagonal matrix of IRLS weights at convergence, and
is the diagonal matrix of IRLS weights at convergence, and 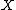 is the GAM model matrix, then the model effective degrees of freedom is given by
is the GAM model matrix, then the model effective degrees of freedom is given by 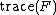 where
where
,
is the effective degrees of freedom matrix.[10] In fact summing just the diagonal elements of  corresponding to the coefficients of gives the effective degrees of freedom for the estimate of .
corresponding to the coefficients of gives the effective degrees of freedom for the estimate of .
Bayesian smoothing priors
Smoothing bias complicates interval estimation for these models, and the simplest approach turns out to involve a Bayesian approach [15][16]
[17].[18] Understanding this Bayesian view of smoothing also helps to understand the REML and full Bayes approaches to smoothing parameter estimation. At some level smoothing penalties are imposed because we believe smooth functions to be more probable than wiggly ones, and if that is true then we might as well formalize this notion by placing a prior on model wiggliness. A very simple prior might be
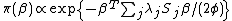
(where  is the GLM scale parameter introduced only for later convenience), but we can immediately recognize this as a multivariate normal prior with mean
is the GLM scale parameter introduced only for later convenience), but we can immediately recognize this as a multivariate normal prior with mean  and precision matrix
and precision matrix 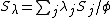 . Since the penalty allows some functions through unpenalized (straight lines, given the example penalties),
. Since the penalty allows some functions through unpenalized (straight lines, given the example penalties), 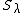 is rank deficient, and the prior is actually improper, with a covariance matrix given by the Moore-Penrose pseudoinverse of (the impropriety corresponds to ascribing infinite variance to the unpenalized components of a smooth).[17]
is rank deficient, and the prior is actually improper, with a covariance matrix given by the Moore-Penrose pseudoinverse of (the impropriety corresponds to ascribing infinite variance to the unpenalized components of a smooth).[17]
Now if this prior is combined with the GLM likelihood, we find that the posterior mode for is exactly the 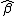 found above by penalized IRLS.[17][10] Furthermore, we have the large sample result that
found above by penalized IRLS.[17][10] Furthermore, we have the large sample result that
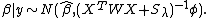
which can be used to produce confidence/credible intervals for the smooth components, .
The Gaussian smoothness priors are also the basis for fully Bayesian inference with GAMs,[8] as well as methods estimating GAMs as mixed models[11][19] that are essentially empirical Bayes methods.
Smoothing parameter estimation
So far we have treated estimation and inference given the smoothing parameters,  , but these also need to be estimated. One approach is to take a fully Bayesian approach, defining priors on the (log) smoothing parameters, and using stochastic simulation or high order approximation methods to obtain information about the posterior of the model coefficients.[8][12] An alternative is to select the smoothing parameters to optimize a prediction error criterion such as Generalized cross validation (GCV) or the
, but these also need to be estimated. One approach is to take a fully Bayesian approach, defining priors on the (log) smoothing parameters, and using stochastic simulation or high order approximation methods to obtain information about the posterior of the model coefficients.[8][12] An alternative is to select the smoothing parameters to optimize a prediction error criterion such as Generalized cross validation (GCV) or the
Akaike information criterion (AIC).[20] Finally we may choose to maximize the Marginal Likelihood (REML) obtained by integrating the model coefficients, out of the joint density of 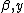 ,
,
.
Since 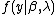 is just the likelihood of , we can view this as choosing to maximize the average likelihood of random draws from the prior. The preceding integral is usually analytically intractable but can be approximated to quite high accuracy using Laplace's method.[19]
is just the likelihood of , we can view this as choosing to maximize the average likelihood of random draws from the prior. The preceding integral is usually analytically intractable but can be approximated to quite high accuracy using Laplace's method.[19]
Smoothing parameter inference is the most computationally taxing part of model estimation/inference. For example, to optimize a GCV or marginal likelihood typically requires numerical optimization via a Newton or Quasi-Newton method, with each trial value for the (log) smoothing parameter vector requiring a penalized IRLS iteration to evaluate the corresponding alongside the other ingredients of the GCV score or Laplace approximate marginal likelihood (LAML). Furthermore, to obtain the derivatives of the GCV or LAML, required for optimization, involves implicit differentiation to obtain the derivatives of w.r.t. the log smoothing parameters, and this requires some care is efficiency and numerical stability are to be maintained.[19]
Software
Backfit GAMs were originally provided by the gam function in S,[21] now ported to the R language as the gam package. The SAS proc GAM also provides backfit GAMs. The recommended package in R for GAMs is mgcv, which stands for mixed GAM computational vehicle,[10] which is based on the reduced rank approach with automatic smoothing parameter selection. The SAS proc GAMPL is an alternative implementation. There are many alternative packages. Examples include the R packages mboost[13], which implements a boosting approach; gss, which provides the full spline smoothing methods;[22] VGAM which provides vector GAMs;[3] and gamlss, which provides Generalized additive model for location, scale and shape. `BayesX' and its R interface provides GAMs and extensions via MCMC and penalized likelihood methods.[23] The `INLA' software implements a fully Bayesian approach based on Markov random field representations exploiting sparse matrix methods.[12]
As an example of how models can be estimated in practice with software, consider R package mgcv. Suppose that our R workspace contains vectors y, x and z and we want to estimate the model
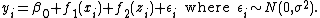
Within R we could issue the commands
library(mgcv) # load the package b = gam(y ~ s(x) + s(z))
In common with most R modelling functions gam expects a model formula to be supplied, specifying the model structure to fit. The response variable is given to the left of the ~ while the specification of the linear predictor is given to the right. gam sets up bases and penalties for the smooth terms, estimates the model including its smoothing parameters and, in standard R fashion, returns a fitted model object, which can then be interrogated using various helper functions, such as summary, plot, predict, and AIC.
This simple example has used several default settings which it is important to be aware of. For example a Gaussian distribution and identity link has been assumed, and the smoothing parameter selection criterion was GCV. Also the smooth terms were represented using `penalized thin plate regression splines', and the basis dimension for each was set to 10 (implying a maximum of 9 degrees of freedom after identifiability constraints have been imposed). A second example illustrates how we can control these things. Suppose that we want to estimate the model
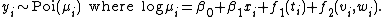
using REML smoothing parameter selection, and we expect to be a relatively complicated function which we would like to model with a penalized cubic regression spline. For we also have to decide whether  and
and  are naturally on the same scale so that an isotropic smoother such as thin plate spline is appropriate (specified via `s(v,w)'), or whether they are really on different scales so that we need separate smoothing penalties and smoothing parameters for and as provided by a tensor product smoother. Suppose we opted for the latter in this case, then the following R code would estimate the model
are naturally on the same scale so that an isotropic smoother such as thin plate spline is appropriate (specified via `s(v,w)'), or whether they are really on different scales so that we need separate smoothing penalties and smoothing parameters for and as provided by a tensor product smoother. Suppose we opted for the latter in this case, then the following R code would estimate the model
which uses a basis size of 100 for the smooth of  . The specification of distribution and link function uses the `family' objects that are standard when fitting GLMs in R or S. Note that Gaussian random effects can also be added to the linear predictor.
. The specification of distribution and link function uses the `family' objects that are standard when fitting GLMs in R or S. Note that Gaussian random effects can also be added to the linear predictor.
These examples are only intended to give a very basic flavour of the way that GAM software is used, for more detail refer to the software documentation for the various packages and the references below.[10][22][3][21][13][23]
Model checking
As with any statistical model it is important to check the model assumptions of a GAM. Residual plots should be examined in the same way as for any GLM. That is deviance residuals (or other standardized residuals) should be examined for patterns that might suggest a substantial violation of the independence or mean-variance assumptions of the model. This will usually involve plotting the standardized residuals against fitted values and covariates to look for mean-variance problems or missing pattern, and may also involve examining Correlograms (ACFs) and/or Variograms of the residuals to check for violation of independence. If the model mean-variance relationship is correct then scaled residuals should have roughly constant variance. Note that since GLMs and GAMs can be estimated using Quasi-likelihood, it follows that details of the distribution of the residuals beyond the mean-variance relationship are of relatively minor importance.
One issue that is more common with GAMs than with other GLMs is a danger of falsely concluding that data are zero inflated. The difficulty arises when data contain many zeroes that can be modelled by a Poisson or binomial with a very low expected value: the flexibility of the GAM structure will often allow representation of a very low mean over some region of covariate space, but the distribution of standardized residuals will fail to look anything like the approximate normality that introductory GLM classes teach us to expect, even if the model is perfectly correct.[24]
The one extra check that GAMs introduce is the need to check that the degrees of freedom chosen are appropriate. This is particularly acute when using methods that do not automatically estimate the smoothness of model components. When using methods with automatic smoothing parameter selection then it is still necessary to check that the choice of basis dimension was not restrictively small, although if the effective degrees of freedom of a term estimate is comfortably below its basis dimension then this is unlikely. In any case, checking is based on examining pattern in the residuals with respect to . This can be done using partial residuals overlaid on the plot of 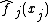 , or using permutation of the residuals to construct tests for residual pattern (as in the `gam.check' function in R package `mgcv').
, or using permutation of the residuals to construct tests for residual pattern (as in the `gam.check' function in R package `mgcv').
Model selection
When smoothing parameters are estimated as part of model fitting then much of what would traditionally count as model selection has been absorbed into the fitting process: the smoothing parameters estimation has already selected between a rich family of models of different functional complexity. However smoothing parameter estimation does not typically remove a smooth term from the model altogether, because of the fact that most penalties leave some functions un-penalized (e.g. straight lines are unpenalized by the spline derivative penalty given above). So the question of whether a term should be in the model at all remains. One simple approach to this issue is to add an extra penalty to each smooth term in the GAM, which penalizes the components of the smooth that would otherwise be unpenalized (and only those). Each extra penalty has its own smoothing parameter and estimation then proceeds as before, but now with the possibility that terms will be completely penalized to zero.[25] In high dimensional settings then it may make more sense to attempt this task using the Lasso (statistics) or Elastic net regularization. Boosting also performs term selection automatically as part of fitting.[13]
An alternative is to use traditional Stepwise regression methods for model selection. This is also the default method when smoothing parameters are not estimated as part of fitting, in which case each smooth term is usually allowed to take one of a small set of pre-defined smoothness levels within the model, and these are selected between in a stepwise fashion. Stepwise methods operate by iteratively comparing models with or without particular model terms (or possibly with different levels of term complexity), and require measures of model fit or term significance in order to decide which model to select at each stage. For example, we might use p-values for testing each term for equality to zero to decide on candidate terms for removal from a model, and we might compare Akaike information criterion (AIC) values for alternative models.
P-value computation for smooths is not straightforward, because of the effects of penalization, but approximations are available,.[1][10] AIC can be computed in two ways for GAMs. The marginal AIC is based on the Mariginal Likelihood (see above) with the model coefficients integrated out. In this case the AIC penalty is based on the number of smoothing parameters (and any variance parameters) in the model. However, because of the well known fact that REML is not comparable between models with different fixed effects structures, we can not usually use such an AIC to compare models with different smooth terms (since their un-penalized components act like fixed effects). Basing AIC on the marginal likelihood in which only the penalized effects are integrated out is possible (the number of un-penalized coefficients now gets added to the parameter count for the AIC penalty), but this version of the marginal likelihood suffers from the tendency to oversmooth that provided the original motivation for developing REML. Given these problems GAMs are often compared using the conditional AIC, in which the model likelihood (not marginal likelihood) is used in the AIC, and the parameter count is taken as the effective degrees of freedom of the model.[1][20]
Naive versions of the conditional AIC have been shown to be much too likely to select larger models in some circumstances, a difficulty attributable to neglect of smoothing parameter uncertainty when computing the effective degrees of freedom,[26] however correcting the effective degrees of freedom for this problem restores reasonable performance.[2]
Caveats
Overfitting can be a problem with GAMs,[20] especially if there is un-modelled residual auto-correlation or un-modelled overdispersion. Cross-validation can be used to detect and/or reduce overfitting problems with GAMs (or other statistical methods),[27] and software often allows the level of penalization to be increased to force smoother fits. Estimating very large numbers of smoothing parameters is also likely to be statistically challenging, and there are known tendencies for prediction error criteria (GCV, AIC etc.) to occasionally undersmooth substantially, particularly at moderate sample sizes, with REML being somewhat less problematic in this regard.[28]Where appropriate, simpler models such as GLMs may be preferable to GAMs unless GAMs improve predictive ability substantially (in validation sets) for the application in question.
See also
- Additive model
- Backfitting algorithm
- Generalized additive model for location, scale, and shape (GAMLSS)
- Residual effective degrees of freedom
- Semiparametric regression
References
2. ^1 {{cite journal |last=Wood |first=S. N.|last2=Pya|first2=N.|last3=Saefken|first3=B. |year=2016 |title=Smoothing parameter and model selection for general smooth models (with discussion) |journal=Journal of the American Statistical Association |volume=111 |issue=516|pages=1548–1575|doi= 10.1080/01621459.2016.1180986}}
3. ^1 2 {{cite book|last=Yee|first=Thomas|year=2015 |title=Vector generalized linear and additive models|publisher=Springer|isbn=978-1-4939-2817-0}}
4. ^{{cite journal|last=Rigby|first=R.A.|last2=Stasinopoulos|first2=D.M.|year=2005|title=Generalized additive models for location, scale and shape (with discussion)|journal=Journal of the Royal Statistical Society, Series C|volume=54|issue=3|pages=507–554|doi=10.1111/j.1467-9876.2005.00510.x}}
5. ^{{cite book|first=Grace|last=Wahba|title=Spline Models for Observational Data|publisher=SIAM}}
6. ^{{cite article|first=C.|last=Gu|first2=G.|last2=Wahba|year=1991|title=Minimizing GCV/GML scores with multiple smoothing parameters via the Newton method|journal=SIAM Journal on Scientific and Statistical Computing|volume=12|pages=383–398}}
7. ^{{cite journal |last1=Wood |first1=S. N. |year=2000 |title=Modelling and smoothing parameter estimation with multiple quadratic penalties |journal=Journal of the Royal Statistical Society |series=Series B |volume=62 |issue=2 |pages=413–428 |doi= 10.1111/1467-9868.00240}}
8. ^1 2 {{cite journal|first=L.|last=Fahrmeier|first2=S.|last2=Lang|year=2001|title=Bayesian Inference for Generalized Additive Mixed Models based on Markov Random Field Priors|journal=Journal of the Royal Statistical Society, Series C|volume=50|issue=2|pages=201–220|doi=10.1111/1467-9876.00229|citeseerx=10.1.1.304.8706}}
9. ^{{cite article|first=Y.J.|last=Kim|first2=C.|last2=Gu|title=Smoothing spline Gaussian regression: more scalable computation via efficient approximation|journal=Journal of the Royal Statistical Society, Series B|year=2004|volume=66|pages=337–356}}
10. ^1 2 3 4 5 6 7 {{cite book|author = Wood, S. N.|title = Generalized Additive Models: An Introduction with R (2nd ed)|publisher = Chapman & Hall/CRC|year = 2017|isbn=978-1-58488-474-3}}
11. ^1 {{cite book|first=D.|last=Ruppert|first2=M.P.|last2=Wand|first3=R.J.|last3=Carroll|title=Semiparametric Regression|publisher=Cambridge University Press|year=2003}}
12. ^1 2 {{cite journal|last=Rue|first= H.|last2=Martino|first2=Sara|last3=Chopin|first3=Nicolas|title=Approximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations (with discussion)|journal=Journal of the Royal Statistical Society, Series B|year=2009|volume=71|issue= 2|pages=319–392|doi=10.1111/j.1467-9868.2008.00700.x}}
13. ^1 2 3 {{cite journal|first=M.|last=Schmid|first2=T.|last2=Hothorn|title=Boosting additive models using component-wise P-splines|journal=Computational Statistics and Data Analysis|volume=53|issue=2|pages=298–311|year=2008|doi=10.1016/j.csda.2008.09.009}}
14. ^{{cite journal|first5=M.|last5=Schmid|first2=N.|last2=Fenske|first=A.|last=Mayr|first3=B.|last3=Hofner|first4=T.|last4=Kneib|title=Generalized additive models for location, scale and shape for high dimensional data - a flexible approach based on boosting|journal=Journal of the Royal Statistical Society, Series C|year=2012|volume=61|issue=3|pages=403–427|doi=10.1111/j.1467-9876.2011.01033.x}}
15. ^{{cite article|first=G.|last=Wahba|year=1983|title=Bayesian Confidence Intervals for the Cross Validated Smoothing Spline|journal=Journal of the Royal Statistical Society, Series B|volume=45|pages=133–150}}
16. ^{{cite article|first=D.|last=Nychka|year=1988|title=Bayesian confidence intervals for smoothing splines|journal=Journal of the American Statistical Association|volume=83|pages=1134–1143}}
17. ^1 2 {{cite article|first=B.W.|last=Silverman|year=1985|title=Some Aspects of the Spline Smoothing Approach to Non-Parametric Regression Curve Fitting (with discussion)|journal=Journal of the Royal Statistical Society, Series B|volume=47|pages=1–53}}
18. ^{{cite journal|first=G.|last=Marra|first2=S.N.|last2=Wood|year=2012|title=Coverage properties of confidence intervals for generalized additive model components|journal=Scandinavian Journal of Statistics|volume=39|pages=53–74|doi=10.1111/j.1467-9469.2011.00760.x}}
19. ^1 2 {{cite journal|first=S.N.|last=Wood|year=2011|title=Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models|journal=Journal of the Royal Statistical Society, Series B|volume=73|pages=3–36|doi=10.1111/j.1467-9868.2010.00749.x}}
20. ^1 2 {{cite journal|last1=Wood|first1=Simon N.|title=Fast stable direct fitting and smoothness selection for generalized additive models|journal=Journal of the Royal Statistical Society, Series B|date=2008|volume=70|issue=3|pages=495–518|doi=10.1111/j.1467-9868.2007.00646.x|arxiv=0709.3906}}
21. ^1 {{cite book|first=J.M.|last=Chambers|first2=T.|last2=Hastie|title=Statistical Models in S|year=1993|publisher=Chapman and Hall}}
22. ^1 {{cite book|first=Chong|last=Gu|year=2013|title=Smoothing Spline ANOVA Models (2nd ed.)|publisher=Springer}}
23. ^1 {{cite journal|first=Nikolaus|last=Umlauf|first2=Daniel|last2= Adler|first3=Thomas|last3= Kneib|first4=Stefan|last4= Lang| first5=Achim|last5= Zeileis|title=Structured Additive Regression Models: An R Interface to BayesX|journal=Journal of Statistical Software|volume=63|number=21|pages=1–46}}
24. ^{{cite journal|last=Augustin|first= N.H.|last2=Sauleau|first2=E-A|last3=Wood|first3=S.N.|title=On quantile quantile plots for generalized linear models|journal=Computational Statistics and Data Analysis|year=2012|volume=56|issue= 8|pages=2404–2409|doi=10.1016/j.csda.2012.01.026}}
25. ^{{cite journal|last=Marra|first=G.|last2=Wood|first2= S.N.|year=2011|title=Practical Variable Selection for Generalized Additive Models|journal=Computational Statistics and Data Analysis|volume=55|issue=7|pages=2372–2387|doi=10.1016/j.csda.2011.02.004}}
26. ^{{cite journal|last=Greven|first=Sonja|last2=Kneib|first2=Thomas|title=On the behaviour of marginal and conditional AIC in linear mixed models|journal=Biometrika|year=2010|volume=97|issue=4|pages=773–789|doi=10.1093/biomet/asq042}}
27. ^{{cite web |url=http://www.stat.cmu.edu/~cshalizi/490/10/xval-and-additive/xval-and-additive2.pdf| title=Additive models and cross-validation | author=Brian Junker | date=March 22, 2010}}
28. ^{{cite journal|first=P.T.|last=Reiss|first2=T.R.|last2=Ogden|year=2009|title=Smoothing parameter selection for a class of semiparametric linear models|journal=Journal of the Royal Statistical Society, Series B|volume=71|issue=2|pages=505–523|doi=10.1111/j.1467-9868.2008.00695.x}}
External links
- [https://cran.r-project.org/web/packages/gam/index.html gam], an R package for GAMs by backfitting.
- [https://cran.r-project.org/web/packages/mgcv/index.html mgcv], an R package for GAMs using penalized regression splines.
- [https://cran.r-project.org/web/packages/mboost/index.html mboost], an R package for boosting including additive models.
- [https://cran.r-project.org/web/packages/gss/index.html gss], an R package for smoothing spline ANOVA.
- INLA software for Bayesian Inference with GAMs and more.
- BayesX software for MCMC and penalized likelihood approaches to GAMs.
- [https://petolau.github.io/Analyzing-double-seasonal-time-series-with-GAM-in-R/ Doing magic and analyzing seasonal time series with GAM in R]
- GAM: The Predictive Modeling Silver Bullet
- One Hundred Ninth United States Congress
- One Hundred-ninth United States Congress
- One hundred one
- One Hundred Poems from the Chinese
- One hundred sacks of rice
- One Hundred-second United States Congress
- One Hundred Second United States Congress
- One hundred seven
- One hundred seventeen
- One Hundred-seventh United States Congress
- One hundred seventy
- One hundred six
- One hundred sixteen
- One Hundred-sixth United States Congress
- One hundred sixty
- One hundred sixty-nine
- One hundred ten
- One Hundred-third United States Congress
- One Hundred Third United States Congress
- One hundred thirteen
- One hundred thirty
- One hundred thirty-seven
- One hundred three
- One Hundredth United States Congress
- One hundred twelve