- Algorithm Details Points Algorithm for inserting ‘k’ and checking overflow condition Searching in the hash table for ‘k’
- Adoption in language systems
- Adoption in database systems
- References
- External links
- See also
Linear hashing is a dynamic hash table algorithm invented by Witold Litwin (1980),[1] and later popularized by Paul Larson. Linear hashing allows for the expansion of the hash table one slot at a time.
The frequent single slot expansion can very effectively control the length of
the collision chain. The cost of hash table expansion is spread out across each
hash table insertion operation, as opposed to being incurred all at once.[2] Linear hashing is therefore well suited for interactive applications.
Algorithm Details
First the initial hash table is set up with some arbitrary initial number of buckets. The following values need to be kept track of:
-
 : The initial number of buckets.
: The initial number of buckets. -
 : The current level which is an integer that indicates on a logarithmic scale approximately how many buckets the table has grown by. This is initially
: The current level which is an integer that indicates on a logarithmic scale approximately how many buckets the table has grown by. This is initially  .
. -
 : The step pointer which points to a bucket. It initially points to the first bucket in the table.
: The step pointer which points to a bucket. It initially points to the first bucket in the table.
Bucket collisions can be handled in a variety of ways but it is typical to have space for two items in each bucket and to add more buckets whenever a bucket overflows. Addresses are calculated in the following way:
- Apply a hash function to the key and call the result
 .
. - If
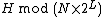 is an address that comes before , the address is
is an address that comes before , the address is 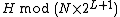 .
. - If
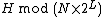 is or an address that comes after , the address is .
is or an address that comes after , the address is .
To add a bucket:
- Allocate a new bucket at the end of the table.
- If points to the
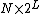 th bucket in the table, reset and increment .
th bucket in the table, reset and increment . - Otherwise increment .
The effect of all of this is that the table is split into three sections; the section before , the section from to , and the section after . The first and last sections are stored using and the middle section is stored using . Each time reaches the table has doubled in size.
Points
- Full buckets are not necessarily split, and an overflow space for temporary overflow buckets is required. In external storage, this could mean a second file.
- Buckets split are not necessarily full.
- Every bucket will be split sooner or later and so all Overflows will be reclaimed and rehashed.
- Split pointer s decides which bucket to split.
- s is independent to overflowing bucket.
- At level i, s is between 0 and 2i.
- s is incremented and if at end, is reset to 0.
- Since a bucket at s is split then s is in incremented, only buckets before s have the second doubled hash space.
- A large good pseudo random number is first obtained, and then is bit-masked with either 2i -1 or 2i+1 -1, but the latter only applies if x, the random number, bit-masked with the former, 2i - 1, is less than S, so the larger range of hash values only apply to buckets that have already been split.
- e.g. To bit-mask a number, use x & 0111, where & is the AND operator, 111 is binary 7, where 7 = 8 - 1 and 8 is 23 and i = 3.
- What if s lands on a bucket which has 1 or more full overflow buckets? The split will only reduce the overflow bucket count by 1, and the remaining overflow buckets will have to be recreated by seeing which of the new 2 buckets, or their overflow buckets, the overflow entries belong.
- hi (k)= h(k) mod(2i n).
- hi+1 doubles the range of hi.
Algorithm for inserting ‘k’ and checking overflow condition
- b = h0(k)
- if b < split-pointer then
- b = h1(k)
Searching in the hash table for ‘k’
- b = h0(k)
- if b < split-pointer then
- b = h1(k)
- read bucket b and search there
Adoption in language systems
Griswold and Townsend [3] discussed the adoption of linear hashing in the Icon language. They discussed the implementation alternatives of dynamic array algorithm used in linear hashing, and presented performance comparisons using a list of Icon benchmark applications.
Adoption in database systems
Linear hashing is used in the Berkeley database system (BDB), which in turn is used by many software systems such as OpenLDAP, using a C implementation derived from the CACM article and first published on the Usenet in 1988 by Esmond Pitt.
References
2. ^{{Citation | first1=Per-Åke | last1=Larson | title=Dynamic Hash Tables | journal=Communications of the ACM | pages=446–457 | date=April 1988 | volume=31 | number=4 | doi=10.1145/42404.42410}}
3. ^{{Citation | title=The Design and Implementation of Dynamic Hashing for Sets and Tables in Icon | first1=William G. | last1=Griswold | author1-link = Bill Griswold | first2=Gregg M. | last2=Townsend | journal=Software - Practice and Experience | volume=23 | issue=4 | date=April 1993 | pages=351–367 | url=http://citeseer.ist.psu.edu/griswold93design.html}}
External links
- TommyDS, C implementation of a Linear Hashtable
- An in Memory Go Implementation with Explanation
- {{DADS|linear hashing|linearHashing}}
- [https://github.com/KevinStern/index-cpp/blob/master/src/linear_hashing_table.h A C++ Implementation of Linear Hashtable which Supports Both Filesystem and In-Memory storage]
See also
- Extendible hashing
- Consistent hashing
- Center for Digital Research in the Humanities
- Center for disease control
- Center for Distributive, Labor and Social Studies
- Center for Documentation and Information of Aceh
- Center for Drug and Alcohol Programs
- Center for Early Education
- Center for Earthquake Studies
- Center for Economic and Social Justice
- Center for Economic and Social Studies
- Center for Economics and Neuroscience
- Center for Education Reform
- Center for Effective Global Action
- Center for Embedded Networked Sensing
- Center for Engaged Democracy
- Center for Entrepreneurial Studies
- Center for Entrepreneurship and Technology
- Center for Environmental Health
- Center for Environmental Philosophy
- Center for Environmental Research and Conservation
- Center for Epidemiologic Studies Depression Scale
- Center for Eurasian, Russian, and East European Studies (CERES)
- Center for European Democracy Studies
- Center for European Economic Research
- Center for European Governance and Economic Development Research
- Center for European, Governance and Economic Development Research