- Applications
- Methods Exact methods Linear search Space partitioning Approximation methods Greedy search in proximity neighborhood graphs Locality sensitive hashing Nearest neighbor search in spaces with small intrinsic dimension Projected radial search Vector approximation files Compression/clustering based search
- Variants k-nearest neighbors Approximate nearest neighbor Nearest neighbor distance ratio Fixed-radius near neighbors All nearest neighbors
- See also
- Open source implementations
- References Citations Sources
- Further reading
- External links
Nearest neighbor search (NNS), as a form of proximity search, is the optimization problem of finding the point in a given set that is closest (or most similar) to a given point. Closeness is typically expressed in terms of a dissimilarity function: the less similar the objects, the larger the function values. Formally, the nearest-neighbor (NN) search problem is defined as follows: given a set S of points in a space M and a query point q ∈ M, find the closest point in S to q. Donald Knuth in vol. 3 of The Art of Computer Programming (1973) called it the post-office problem, referring to an application of assigning to a residence the nearest post office. A direct generalization of this problem is a k-NN search, where we need to find the k closest points.
Most commonly M is a metric space and dissimilarity is expressed as a distance metric, which is symmetric and satisfies the triangle inequality. Even more common, M is taken to be the d-dimensional vector space where dissimilarity is measured using the Euclidean distance, Manhattan distance or other distance metric. However, the dissimilarity function can be arbitrary. One example are asymmetric Bregman divergences, for which the triangle inequality does not hold.[1]
Applications
The nearest neighbor search problem arises in numerous fields of application, including:
- Pattern recognition – in particular for optical character recognition
- Statistical classification – see k-nearest neighbor algorithm
- Computer vision
- Computational geometry – see Closest pair of points problem
- Databases – e.g. content-based image retrieval
- Coding theory – see maximum likelihood decoding
- Data compression – see MPEG-2 standard
- Robotic sensing[2]
- Recommendation systems, e.g. see Collaborative filtering
- Internet marketing – see contextual advertising and behavioral targeting
- DNA sequencing
- Spell checking – suggesting correct spelling
- Plagiarism detection
- Contact searching algorithms in FEA
- Similarity scores for predicting career paths of professional athletes.
- Cluster analysis – assignment of a set of observations into subsets (called clusters) so that observations in the same cluster are similar in some sense, usually based on Euclidean distance
- Chemical similarity
- Sampling-based motion planning
- Intermodal freight transport[3]
Methods
Various solutions to the NNS problem have been proposed. The quality and usefulness of the algorithms are determined by the time complexity of queries as well as the space complexity of any search data structures that must be maintained. The informal observation usually referred to as the curse of dimensionality states that there is no general-purpose exact solution for NNS in high-dimensional Euclidean space using polynomial preprocessing and polylogarithmic search time.
Exact methods
Linear search
The simplest solution to the NNS problem is to compute the distance from the query point to every other point in the database, keeping track of the "best so far". This algorithm, sometimes referred to as the naive approach, has a running time of O(dN) where N is the cardinality of S and d is the dimensionality of M. There are no search data structures to maintain, so linear search has no space complexity beyond the storage of the database. Naive search can, on average, outperform space partitioning approaches on higher dimensional spaces.[4]
Space partitioning
Since the 1970s, branch and bound methodology has been applied to the problem. In the case of Euclidean space this approach is known as spatial index or spatial access methods. Several space-partitioning methods have been developed for solving the NNS problem. Perhaps the simplest is the k-d tree, which iteratively bisects the search space into two regions containing half of the points of the parent region. Queries are performed via traversal of the tree from the root to a leaf by evaluating the query point at each split. Depending on the distance specified in the query, neighboring branches that might contain hits may also need to be evaluated. For constant dimension query time, average complexity is O(log N) [5] in the case of randomly distributed points, worst case complexity is O(kN^(1-1/k))[6]
Alternatively the R-tree data structure was designed to support nearest neighbor search in dynamic context, as it has efficient algorithms for insertions and deletions such as the R* tree.[7] R-trees can yield nearest neighbors not only for Euclidean distance, but can also be used with other distances.
In case of general metric space branch and bound approach is known under the name of metric trees. Particular examples include vp-tree and BK-tree.
Using a set of points taken from a 3-dimensional space and put into a BSP tree, and given a query point taken from the same space, a possible solution to the problem of finding the nearest point-cloud point to the query point is given in the following description of an algorithm. (Strictly speaking, no such point may exist, because it may not be unique. But in practice, usually we only care about finding any one of the subset of all point-cloud points that exist at the shortest distance to a given query point.) The idea is, for each branching of the tree, guess that the closest point in the cloud resides in the half-space containing the query point. This may not be the case, but it is a good heuristic. After having recursively gone through all the trouble of solving the problem for the guessed half-space, now compare the distance returned by this result with the shortest distance from the query point to the partitioning plane. This latter distance is that between the query point and the closest possible point that could exist in the half-space not searched. If this distance is greater than that returned in the earlier result, then clearly there is no need to search the other half-space. If there is such a need, then you must go through the trouble of solving the problem for the other half space, and then compare its result to the former result, and then return the proper result. The performance of this algorithm is nearer to logarithmic time than linear time when the query point is near the cloud, because as the distance between the query point and the closest point-cloud point nears zero, the algorithm needs only perform a look-up using the query point as a key to get the correct result.
Approximation methods
An approximate nearest neighbor search algorithm is allowed to return points, whose distance from the query is at most  times the distance from the query to its nearest points. The appeal of this approach is that, in many cases, an approximate nearest neighbor is almost as good as the exact one. In particular, if the distance measure accurately captures the notion of user quality, then small differences in the distance should not matter.[8]
times the distance from the query to its nearest points. The appeal of this approach is that, in many cases, an approximate nearest neighbor is almost as good as the exact one. In particular, if the distance measure accurately captures the notion of user quality, then small differences in the distance should not matter.[8]
Greedy search in proximity neighborhood graphs
Proximity graph methods (such as HNSW[9]) are considered the current state-of-the-art for the approximate nearest neighbors search.[9][10][11]
The methods are based on greedy traversing in proximity neighborhood graphs 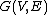 in which every point
in which every point 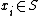 is uniquely associated with vertex
is uniquely associated with vertex  . The search for the nearest neighbors to a query q in the set S takes the form of searching for the vertex in the graph .
. The search for the nearest neighbors to a query q in the set S takes the form of searching for the vertex in the graph .
The basic algorithm - greedy search, works as follows: search starts from an enter-point vertex by computing the distances from the query q to each vertex of its the neighborhood 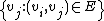 , and then finds a vertex with the minimal distance value. If the distance value between the query and the selected vertex is smaller than the one between the query and the current element, then the algorithm moves to the selected vertex, and it becomes new enter-point. The algorithm stops when it reaches a local minimum: a vertex whose neighborhood does not contain a vertex that is closer to the query than the vertex itself.
, and then finds a vertex with the minimal distance value. If the distance value between the query and the selected vertex is smaller than the one between the query and the current element, then the algorithm moves to the selected vertex, and it becomes new enter-point. The algorithm stops when it reaches a local minimum: a vertex whose neighborhood does not contain a vertex that is closer to the query than the vertex itself.
The idea of proximity neighborhood graphs was exploited in multiple publications, including the seminal paper by Arya and Mount,[12] in the VoroNet system for the plane,[13] in the RayNet system for the 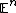 ,[14] in the Metrized Small World[15] and HNSW[9] algorithms for the general case of spaces with a distance function. These works were preceded by a pioneering paper by Toussaint, where he introduced a concept of a relative neighborhood graph.[16]
,[14] in the Metrized Small World[15] and HNSW[9] algorithms for the general case of spaces with a distance function. These works were preceded by a pioneering paper by Toussaint, where he introduced a concept of a relative neighborhood graph.[16]
Locality sensitive hashing
Locality sensitive hashing (LSH) is a technique for grouping points in space into 'buckets' based on some distance metric operating on the points. Points that are close to each other under the chosen metric are mapped to the same bucket with high probability.[17]Nearest neighbor search in spaces with small intrinsic dimension
The cover tree has a theoretical bound that is based on the dataset's doubling constant. The bound on search time is O(c12 log n) where c is the expansion constant of the dataset.
Projected radial search
In the special case where the data is a dense 3D map of geometric points, the projection geometry of the sensing technique can be used to dramatically simplify the search problem.
This approach requires that the 3D data is organized by a projection to a two dimensional grid and assumes that the data is spatially smooth across neighboring grid cells with the exception of object boundaries.
These assumptions are valid when dealing with 3D sensor data in applications such as surveying, robotics and stereo vision but may not hold for unorganized data in general.
In practice this technique has an average search time of O(1) or O(K) for the k-nearest neighbor problem when applied to real world stereo vision data.
[2]Vector approximation files
In high dimensional spaces, tree indexing structures become useless because an increasing percentage of the nodes need to be examined anyway. To speed up linear search, a compressed version of the feature vectors stored in RAM is used to prefilter the datasets in a first run. The final candidates are determined in a second stage using the uncompressed data from the disk for distance calculation.[18]
Compression/clustering based search
The VA-file approach is a special case of a compression based search, where each feature component is compressed uniformly and independently. The optimal compression technique in multidimensional spaces is Vector Quantization (VQ), implemented through clustering. The database is clustered and the most "promising" clusters are retrieved. Huge gains over VA-File, tree-based indexes and sequential scan have been observed.[19][20] Also note the parallels between clustering and LSH.
Variants
There are numerous variants of the NNS problem and the two most well-known are the k-nearest neighbor search and the ε-approximate nearest neighbor search.
k-nearest neighbors
k-nearest neighbor search identifies the top k nearest neighbors to the query. This technique is commonly used in predictive analytics to estimate or classify a point based on the consensus of its neighbors. k-nearest neighbor graphs are graphs in which every point is connected to its k nearest neighbors.
Approximate nearest neighbor
In some applications it may be acceptable to retrieve a "good guess" of the nearest neighbor. In those cases, we can use an algorithm which doesn't guarantee to return the actual nearest neighbor in every case, in return for improved speed or memory savings. Often such an algorithm will find the nearest neighbor in a majority of cases, but this depends strongly on the dataset being queried.
Algorithms that support the approximate nearest neighbor search include locality-sensitive hashing, best bin first and balanced box-decomposition tree based search.[21]
Nearest neighbor distance ratio
Nearest neighbor distance ratio does not apply the threshold on the direct distance from the original point to the challenger neighbor but on a ratio of it depending on the distance to the previous neighbor. It is used in CBIR to retrieve pictures through a "query by example" using the similarity between local features. More generally it is involved in several matching problems.
Fixed-radius near neighbors
Fixed-radius near neighbors is the problem where one wants to efficiently find all points given in Euclidean space within a given fixed distance from a specified point. The data structure should work on a distance which is fixed however the query point is arbitrary.
All nearest neighbors
For some applications (e.g. entropy estimation), we may have N data-points and wish to know which is the nearest neighbor for every one of those N points. This could of course be achieved by running a nearest-neighbor search once for every point, but an improved strategy would be an algorithm that exploits the information redundancy between these N queries to produce a more efficient search. As a simple example: when we find the distance from point X to point Y, that also tells us the distance from point Y to point X, so the same calculation can be reused in two different queries.
Given a fixed dimension, a semi-definite positive norm (thereby including every Lp norm), and n points in this space, the nearest neighbour of every point can be found in O(n log n) time and the m nearest neighbours of every point can be found in O(mn log n) time.[22][23]
See also
{{div col|colwidth=20em}}- Ball tree
- Closest pair of points problem
- Cluster analysis
- Content-based image retrieval
- Curse of dimensionality
- Digital signal processing
- Dimension reduction
- Fixed-radius near neighbors
- Fourier analysis
- Instance-based learning
- k-nearest neighbor algorithm
- Linear least squares
- Locality sensitive hashing
- MinHash
- Multidimensional analysis
- Nearest-neighbor interpolation
- Neighbor joining
- Principal component analysis
- Range search
- Set cover problem
- Similarity learning
- Singular value decomposition
- Sparse distributed memory
- Statistical distance
- Time series
- Voronoi diagram
- Wavelet
Open source implementations
- Accord.NET has C# implementation of KNN classifier
- ALGLIB has C# and C++ implementations of nearest neighbor and approximate nearest neighbor algorithms
- [https://www.cs.umd.edu/~mount/ANN/ ANN] library (LGPL license) implements exact and approximate NN search in C++
- [https://github.com/spotify/annoy Annoy] (Apache license) is an implementation in C++ with Python binding from Spotify
- [https://falconn-lib.org/ FALCONN] (MIT license) is an LSH-based implementation in C++ with a Python wrapper
- [https://www.cs.ubc.ca/research/flann/ FLANN] library (BSD license) implements special fast approximate NN algorithms for high-dimensional problems
- dD Spatial Searching in CGAL – the Computational Geometry Algorithms Library
- [https://github.com/searchivarius/NonMetricSpaceLib Non-Metric Space Library] – An open source similarity search library containing realisations of various Nearest neighbor search methods.
References
Citations
2. ^1 {{cite conference|last1=Bewley|first1=A.|last2=Upcroft|first2=B.|date=2013|title=Advantages of Exploiting Projection Structure for Segmenting Dense 3D Point Clouds|conference=Australian Conference on Robotics and Automation |url=http://www.araa.asn.au/acra/acra2013/papers/pap148s1-file1.pdf}}
3. ^{{cite journal|last1=Munim|first1=Ziaul Haque|last2=Haralambides|first2= Hercules |title= Competition and cooperation for intermodal container transhipment: A network optimization approach|journal=Research in Transportation Business & Management|date=2018|pages=87–99|doi= 10.1016/j.rtbm.2018.03.004|url= https://www.sciencedirect.com/science/article/pii/S2210539517301001|volume=26}}
4. ^{{cite journal|title=A quantitative analysis and performance study for similarity search methods in high dimensional spaces|last1=Weber|first1=Roger|last2=Schek|first2=Hans-J.|last3=Blott|first3=Stephen | journal=VLDB '98 Proceedings of the 24rd International Conference on Very Large Data Bases | pages=194-205 | year=1998 | url=http://www.vldb.org/conf/1998/p194.pdf}}
5. ^{{cite web|title=An introductory tutorial on KD trees|author=Andrew Moore | url=http://www.autonlab.com/autonweb/14665/version/2/part/5/data/moore-tutorial.pdf?branch=main&language=en}}
6. ^{{Cite journal | last1 = Lee | first1 = D. T. | author1-link = Der-Tsai Lee | last2 = Wong | first2 = C. K. | year = 1977 | title = Worst-case analysis for region and partial region searches in multidimensional binary search trees and balanced quad trees | journal = Acta Informatica | volume = 9 | issue = 1 | pages = 23–29 | doi = 10.1007/BF00263763 | postscript = .}}
7. ^{{Cite conference | doi = 10.1145/223784.223794| chapter = Nearest neighbor queries| title = Proceedings of the 1995 ACM SIGMOD international conference on Management of data – SIGMOD '95| pages = 71| year = 1995| last1 = Roussopoulos | first1 = N. | last2 = Kelley | first2 = S. | last3 = Vincent | first3 = F. D. R. | isbn = 0897917316}}
8. ^{{Cite book|last=Andoni|first=A.|last2=Indyk|first2=P.|date=2006-10-01|title=Near-Optimal Hashing Algorithms for Approximate Nearest Neighbor in High Dimensions|url=http://ieeexplore.ieee.org/document/4031381/|journal=2006 47th Annual IEEE Symposium on Foundations of Computer Science (FOCS'06)|pages=459–468|doi=10.1109/FOCS.2006.49|isbn=978-0-7695-2720-8|citeseerx=10.1.1.142.3471}}
9. ^1 2 {{cite arxiv|last=Malkov|first=Yury|last2=Yashunin|first2=Dmitry|date=2016|title=Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs|eprint=1603.09320|class=cs.DS}}
10. ^{{Cite web|url=https://erikbern.com/2018/06/17/new-approximate-nearest-neighbor-benchmarks.html|title=New approximate nearest neighbor benchmarks|last=|first=|date=|website=|archive-url=|archive-date=|dead-url=|access-date=}}
11. ^{{Cite web|url=https://www.benfrederickson.com/approximate-nearest-neighbours-for-recommender-systems/|title=Approximate Nearest Neighbours for Recommender Systems|last=|first=|date=|website=|archive-url=|archive-date=|dead-url=|access-date=}}
12. ^{{cite journal|last1=Arya|first1=Sunil|last2=Mount|first2=David|date=1993|title=Approximate Nearest Neighbor Queries in Fixed Dimensions|journal=Proceedings of the Fourth Annual {ACM/SIGACT-SIAM} Symposium on Discrete Algorithms, 25–27 January 1993, Austin, Texas.|pages=271–280}}
13. ^{{Cite journal|last1=Olivier|first1=Beaumont|last2=Kermarrec|first2=Anne-Marie|last3=Marchal|first3=Loris|last4=Rivière|first4=Etienne|year=2006|title=VoroNet: A scalable object network based on Voronoi tessellations|journal=INRIA|volume=RR-5833|issue=1|pages=23–29|doi=10.1109/IPDPS.2007.370210|url=https://hal.inria.fr/inria-00071210/PDF/RR-5833.pdf|postscript=.}}
14. ^{{Cite book|last1=Olivier|first1=Beaumont|last2=Kermarrec|first2=Anne-Marie|last3=Rivière|first3=Etienne|year=2007|title=Peer to Peer Multidimensional Overlays: Approximating Complex Structures|journal=Principles of Distributed Systems|volume=4878|issue=|pages=315–328|doi=10.1007/978-3-540-77096-1_23|isbn=978-3-540-77095-4|postscript=.|citeseerx=10.1.1.626.2980}}
15. ^{{Cite journal|last1=Malkov|first1=Yury|last2=Ponomarenko|first2=Alexander|last3=Krylov|first3=Vladimir|last4=Logvinov|first4=Andrey|year=2014|title=Approximate nearest neighbor algorithm based on navigable small world graphs|journal=Information Systems|volume=45|pages=61–68|doi=10.1016/j.is.2013.10.006|postscript=.}}
16. ^{{cite journal|last1=Toussaint|first1=Godfried|date=1980|title=The relative neighbourhood graph of a finite planar set|journal=Pattern Recognition|volume=12|issue=4|pages=261–268|doi=10.1016/0031-3203(80)90066-7}}
17. ^{{cite web|author1=A. Rajaraman |author2=J. Ullman |lastauthoramp=yes | url=http://infolab.stanford.edu/~ullman/mmds.html |title=Mining of Massive Datasets, Ch. 3 |year=2010}}
18. ^{{cite journal|title=An Approximation-Based Data Structure for Similarity Search|last1=Weber|first1=Roger|last2=Blott|first2=Stephen|url=https://pdfs.semanticscholar.org/83e4/e3281411ffef40654a4b5d29dae48130aefb.pdf}}
19. ^{{cite journal|title=Adaptive cluster-distance bounding for similarity search in image databases|last1=Ramaswamy|first1=Sharadh|last2=Rose|first2=Kenneth|journal=ICIP|date=2007}}
20. ^{{cite journal|title=Adaptive cluster-distance bounding for high-dimensional indexing|last1=Ramaswamy|first1=Sharadh|last2=Rose|first2=Kenneth|journal=TKDE|date=2010}}
21. ^{{cite journal|first1=S.|last1=Arya|author2-link=David Mount|first2=D. M.|last2=Mount|author3-link=Nathan Netanyahu|first3=N. S.|last3=Netanyahu|first4=R.|last4=Silverman|first5=A.|last5=Wu|title=An optimal algorithm for approximate nearest neighbor searching|journal= Journal of the ACM|volume=45|number=6|pages=891–923|date=1998|url=http://www.cse.ust.hk/faculty/arya/pub/JACM.pdf|doi=10.1145/293347.293348|citeseerx=10.1.1.15.3125}}
22. ^{{citation | last = Clarkson | first = Kenneth L. | author-link = Kenneth L. Clarkson | contribution = Fast algorithms for the all nearest neighbors problem | doi = 10.1109/SFCS.1983.16 | pages = 226–232 | title = 24th IEEE Symp. Foundations of Computer Science, (FOCS '83) | year = 1983| isbn = 978-0-8186-0508-6 }}.
23. ^{{Cite journal | doi = 10.1007/BF02187718 | last1 = Vaidya | first1 = P. M. | year = 1989 | title = An O(n log n) Algorithm for the All-Nearest-Neighbors Problem | journal = Discrete and Computational Geometry | volume = 4 | issue = 1 | pages = 101–115 | url = http://www.springerlink.com/content/p4mk2608787r7281/?p=09da9252d36e4a1b8396833710ef08cc&pi=8 | postscript = .}}
Sources
- {{cite journal |last= Andrews |first=L. |title= A template for the nearest neighbor problem |journal = C/C++ Users Journal |volume=19 |number=11 |date= November 2001 |pages=40–49 |issn = 1075-2838 |url = http://www.ddj.com/architect/184401449}}
- {{cite journal |last1=Arya|first1=S. |first2=D.M. |last2=Mount|author2-link=David Mount |first3=N. S. |last3=Netanyahu|author3-link=Nathan Netanyahu |first4=R. |last4=Silverman|author4-link=Ruth Silverman |first5=A. Y. |last5=Wu|author5-link=Angela Y. Wu |title = An Optimal Algorithm for Approximate Nearest Neighbor Searching in Fixed Dimensions |journal= Journal of the ACM |volume = 45 |number=6 |pages= 891–923 |doi=10.1145/293347.293348|year=1998 |citeseerx=10.1.1.15.3125 }}
- {{cite journal |last1=Beyer |first1=K. |last2= Goldstein |first2=J. |last3= Ramakrishnan |first3=R. |last4=Shaft |first4=U. |year = 1999 |title=When is nearest neighbor meaningful? |journal=Proceedings of the 7th ICDT }}
- {{cite journal |first1=Chung-Min |last1= Chen |first2=Yibei |last2=Ling|title=A Sampling-Based Estimator for Top-k Query |journal=ICDE |date=2002 |pages = 617–627 }}
- {{cite book |last=Samet |first=H.|authorlink=Hanan Samet |year = 2006 |title= Foundations of Multidimensional and Metric Data Structures |publisher= Morgan Kaufmann |isbn = 978-0-12-369446-1 }}
- {{cite book |last1=Zezula |first1=P. |last2= Amato |first2=G. |last3=Dohnal |first3=V. |last4=Batko |first4=M. |title= Similarity Search – The Metric Space Approach|publisher=Springer |year=2006 |isbn = 978-0-387-29146-8 }}
Further reading
- {{cite book | last = Shasha | first = Dennis | title = High Performance Discovery in Time Series | publisher = Springer | location = Berlin | year = 2004 | isbn = 978-0-387-00857-8 }}
External links
{{commons category|Nearest neighbours search}}- Nearest Neighbors and Similarity Search – a website dedicated to educational materials, software, literature, researchers, open problems and events related to NN searching. Maintained by Yury Lifshits
- Similarity Search Wiki – a collection of links, people, ideas, keywords, papers, slides, code and data sets on nearest neighbours
- K'inich Janaab' Pakal's sarcophagus lid
- Kiniebakoura
- Kinie Ger
- Kinieran
- Kiniero
- Kini et Adams
- Kinigama
- Kinik
- Kiniki
- Kinikinik (disambiguation)
- Kinikinik Lake
- Kinikinik lake
- Kinikinik Lake, Alberta
- Kinilaw
- Kininmonth
- Kinin precursor
- Kininvie distillery
- Kinira River
- Kinira River (disambiguation)
- Kin'iro no Corda
- Kiniro no Corda
- Kin'iro no Corda media information
- Kin'iro no Corda: The After School Etude
- Kinish
- Kinisis tape