玉鹰
西周早期。高7.6厘米,厚0.4厘米。1979年山东省滕县庄里西村出土。山东省博物馆藏。由青玉琢成,通体被浸蚀。鹰勾背引颈,头前伸,喙下弯,一爪翘起,羽尾内收,翅似微展。眼、颈、羽、尾均以阴线饰纹,刀工娴熟而整洁。鹰的造型颇为奇特,既有写实性,又进行了适当的艺术夸张,装饰意趣颇浓。颌及颈部各有一圆穿可系绳佩带。

玉鹰
西汉早期。长7厘米,宽5厘米。1966—1976年陕西省咸阳市周陵公社渭陵附近出土。陕西省咸阳市博物馆藏。玉质为白色,局部有玉璞的红皮色,圆雕琢成。玉鹰为蹲伏状,头前伸,双翼展开,似捕获猎物前的瞬间形象。作者在写实的基础上淡化了鹰的凶残,圆润的线条,粗壮的短喙,刻画细腻的羽翼使鹰的形象看起来十分可爱,是一件成功的艺术品。

玉鹰yuying
西汉玉雕。1972年咸阳市周陵公社(今咸阳市渭城区周陵镇)新庄村出土。长5厘米,高7厘米。白玉质。立体圆雕。鹰嘴呈勾状,两翼平展,尾羽散张,似面对猎物作俯冲之势。玉鹰造型浑厚自然,显得可爱而不凶残。现藏咸阳博物馆。
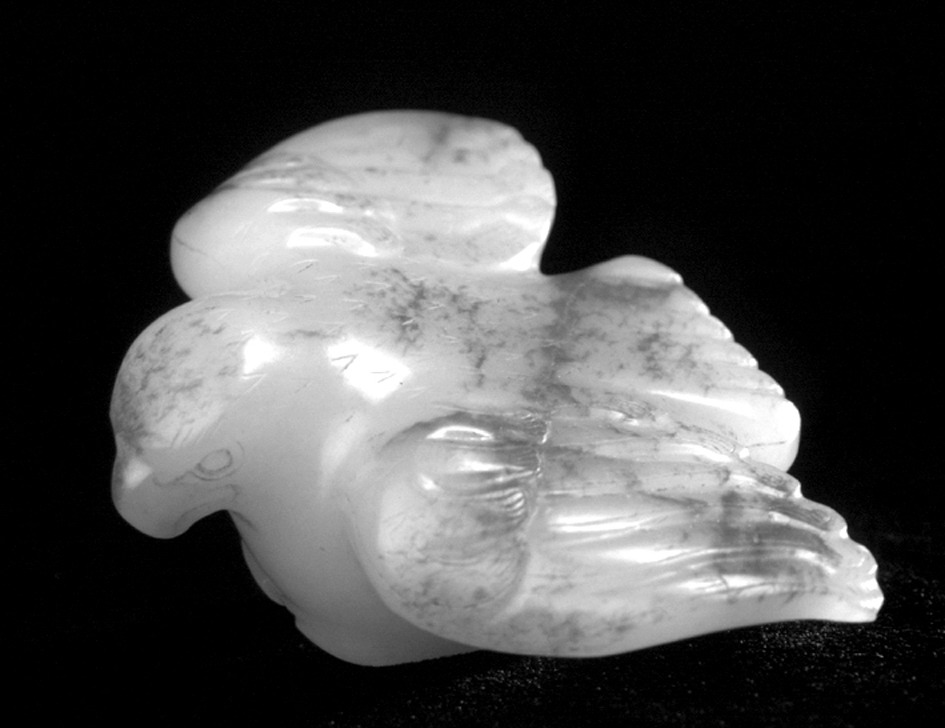
玉鹰
汉代玉器,1966年在陕西咸阳市周陵乡新庄村发现。身长7厘米,横长5厘米。两翼平伸,尾羽散张,作俯冲之势。