- Background
- Applications
- Research
- Criticism and Limitations
- References
- External links
The Z curve (or Z-curve) method is a bioinformatics algorithm for genome analysis. The Z-curve is a three-dimensional curve that constitutes a unique representation of a DNA sequence, i.e., for the Z-curve and the given DNA sequence each can be uniquely reconstructed from the other.[1]
The resulting curve has a zigzag shape, hence the name Z-curve.
Background
The Z Curve method was first created in 1994 as a way to visually map a DNA or RNA sequence. Different properties of the Z curve, such as its symmetry and periodicity can give unique information on the DNA sequence.[2] The Z curve is generated from a series of nodes, P0, P1,…PN, with the coordinates xn, yn, and zn (n=0,1,2…N, with N being the length of the DNA sequence). The Z curve is created by connecting each of the nodes sequentially.[3]
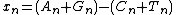
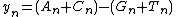
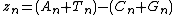
Applications
Information on the distribution of nucleotides in a DNA sequence can be determined from the Z curve. The four nucleotides are combined into six different categories. The nucleotides are placed into each category by some defining characteristic and each category is designated a letter.[4]
| Purine | R = A, G | Amino | M = A, C | Weak Hydrogen Bonds | W = A, T |
| Pyrimidine | Y = C, T | Keto | K = G, T | Strong Hydrogen Bonds | S = G, C |
The x, y, and z components of the Z curve display the distribution of each of these categories of bases for the DNA sequence being studied. The x-component represents the distribution of purines and pyrimidine bases (R/Y). The y-component shows the distribution of amino and keto bases (M/K) and the z-component shows the distribution of strong-H bond and weak-H bond bases (S/W) in the DNA sequence.[5]
The Z-curve method has been used in many different areas of genome research, such as replication origin identification,[6][7][8][9], ab initio gene prediction,[10]
isochore identification,[11]genomic island identification[12]and comparative genomics.[13] Analysis of the Z curve has also been shown to be able to predict if a gene contains introns,[14]
Research
Experiments have shown that the Z curve can be used to identify the replication origin in various organisms. One study analyzed the Z curve for multiple species of Archaea and found that the oriC is located at a sharp peak on the curve followed by a broad base. This region was rich in AT bases and had multiple repeats, which is expected for replication origin sites.[15] This and other similar studies were used to generate a program that could predict the origins of replication using the Z curve.
The Z curve has also been experimentally used to determine phylogenetic relationships. In one study, a novel coronavirus in China was analyzed using sequence analysis and the Z curve method to determine its phylogenetic relationship to other coronaviruses. It was determined that similarities and differences in related species can quickly by determined by visually examining their Z curves. An algorithm was created to identify the geometric center and other trends in the Z curve of 24 species of coronaviruses. The data was used to create a phylogenetic tree. The results matched the tree that was generated using sequence analysis. The Z curve method proved superior because while sequence analysis creates a phylogenetic tree based solely on coding sequences in the genome, the Z curve method analyzed the entire genome.[16]
Criticism and Limitations
The Z curve method has been criticized for over analyzing the genomic sequence and including parameters that are not significant. One study analyzed 235 genomes of bacteria and determined that the z coordinate of the Z curve accounted for 99.9% of the genetic variance and the x and y coordinates were not meaningful in studying nucleotide composition.[17] The original authors of the Z curve method have since published a rebuttal indicating that the criticisms confuse numeral smallness with biological insignificance, because variations of purine/pyrimidine and amino/keto bases (x and y components), although less than that of GC content, contain rich information that is important and useful, such as in locating replication origins of bacterial and archaeal genomes.[18]
Similar methods of visually representing genomic sequences have since been created that are better equipped to identify a broad range of genomic structures. The DNA Hilbert–Peano curve is a 2D color image of a genomic sequence that can highlight all structures of interest in a sequence at once.[19]
References
2. ^{{cite journal |last1=Zhang |first1=Ren |last2=Zhang |first2=Chun-Ting |title=Z Curves, An {{sic|nolink=y|Intutive}} Tool for Visualizing and Analyzing the DNA Sequences |journal=Journal of Biomolecular Structure and Dynamics |date=February 1994 |volume=11 |issue=4 |pages=767–782 |doi=10.1080/07391102.1994.10508031 |pmid=8204213}}
3. ^{{Cite journal|title = DFA7, a New Method to Distinguish between Intron-Containing and Intronless Genes|journal = PLoS ONE|date = 2014-07-18|pmc = 4103774|pmid = 25036549|pages = e101363|volume = 9|issue = 7|doi = 10.1371/journal.pone.0101363|first = Chenglong|last = Yu|first2 = Mo|last2 = Deng|first3 = Lu|last3 = Zheng|first4 = Rong Lucy|last4 = He|first5 = Jie|last5 = Yang|first6 = Stephen S.-T.|last6 = Yau}}
4. ^{{Cite journal|title = A Brief Review: The Z-curve Theory and its Application in Genome Analysis|journal = Current Genomics|date = 2014-04-01|issn = 1389-2029|pmc = 4009844|pmid = 24822026|pages = 78–94|volume = 15|issue = 2|doi = 10.2174/1389202915999140328162433|first = Ren|last = Zhang|first2 = Chun-Ting|last2 = Zhang}}
5. ^{{Cite journal|title = A symmetrical theory of DNA sequences and its applications|journal = Journal of Theoretical Biology|date = 1997-08-07|issn = 0022-5193|pmid = 9245572|pages = 297–306|volume = 187|issue = 3|doi = 10.1006/jtbi.1997.0401|first = C. T.|last = Zhang}}
6. ^{{cite journal |vauthors=Zhang R, Zhang CT | year = 2005 | title = Identification of replication origins in archaeal genomes based on the Z-curve method | journal = Archaea | volume = 1 | issue = 5 | pages = 335–46 | pmid=15876567 | doi = 10.1155/2005/509646 | pmc = 2685548 }}
7. ^{{cite journal|vauthors=Worning P, Jensen LJ, Hallin PF, Staerfeldt HH, Ussery DW | title = Origin of replication in circular prokaryotic chromosomes| journal = Environ. Microbiol.| volume = 8| issue = 2| pages = 353–61|date=February 2006| pmid = 16423021| doi = 10.1111/j.1462-2920.2005.00917.x| url =}}
8. ^{{Cite journal|last=Zhang|first=Ren|last2=Zhang|first2=Chun-Ting|date=2002-09-20|title=Single replication origin of the archaeon Methanosarcina mazei revealed by the Z curve method|journal=Biochemical and Biophysical Research Communications|volume=297|issue=2|pages=396–400|issn=0006-291X|pmid=12237132|doi=10.1016/s0006-291x(02)02214-3}}
9. ^{{Cite journal|last=Worning|first=Peder|last2=Jensen|first2=Lars J.|last3=Hallin|first3=Peter F.|last4=Staerfeldt|first4=Hans-Henrik|last5=Ussery|first5=David W.|date=2006-02-01|title=Origin of replication in circular prokaryotic chromosomes|journal=Environmental Microbiology|volume=8|issue=2|pages=353–361|doi=10.1111/j.1462-2920.2005.00917.x|issn=1462-2912|pmid=16423021}}
10. ^{{cite journal |vauthors=Guo FB, Ou HY, Zhang CT | year = 2003 | title = ZCURVE: a new system for recognizing protein-coding genes in bacterial and archaeal genomes | journal = Nucleic Acids Research | volume = 31 | issue = 6 | pages = 1780–89 | pmid=12626720 | doi = 10.1093/nar/gkg254 | pmc = 152858}}
11. ^{{cite journal |vauthors=Zhang CT, Zhang R | year = 2004 | title = Isochore structures in the mouse genome | journal = Genomics | volume = 83 | issue = 3 | pages = 384–94 | pmid=14962664 | doi = 10.1016/j.ygeno.2003.09.011}}
12. ^{{cite journal |vauthors=Zhang R, Zhang CT | year = 2004 | title = A systematic method to identify genomic islands and its applications in analyzing the genomes of Corynebacterium glutamicum and Vibrio vulnificus CMCP6 chromosome I | journal = Bioinformatics | volume = 20 | issue = 5 | pages = 612–22 | pmid=15033867 | doi = 10.1093/bioinformatics/btg453}}
13. ^{{cite journal |vauthors=Zhang R, Zhang CT | year = 2003 | title = Identification of genomic islands in the genome of Bacillus cereus by comparative analysis with Bacillus anthracis | journal = Physiological Genomics | volume = 16 | issue = 1 | pages = 19–23 | pmid=14600214 | doi = 10.1152/physiolgenomics.00170.2003}}
14. ^{{Cite journal|last=Zhang|first=C. T.|last2=Lin|first2=Z. S.|last3=Yan|first3=M.|last4=Zhang|first4=R.|date=1998-06-21|title=A novel approach to distinguish between intron-containing and intronless genes based on the format of Z curves|journal=Journal of Theoretical Biology|volume=192|issue=4|pages=467–473|doi=10.1006/jtbi.1998.0671|issn=0022-5193|pmid=9680720}}
15. ^{{Cite journal|last=Zhang|first=Ren|last2=Zhang|first2=Chun-Ting|date=2002-09-20|title=Single replication origin of the archaeon Methanosarcina mazei revealed by the Z curve method|journal=Biochemical and Biophysical Research Communications|volume=297|issue=2|pages=396–400|issn=0006-291X|pmid=12237132|doi=10.1016/s0006-291x(02)02214-3}}
16. ^{{Cite journal|last=Zheng|first=Wen-Xin|last2=Chen|first2=Ling-Ling|last3=Ou|first3=Hong-Yu|last4=Gao|first4=Feng|last5=Zhang|first5=Chun-Ting|date=2005-08-01|title=Coronavirus phylogeny based on a geometric approach|journal=Molecular Phylogenetics and Evolution|volume=36|issue=2|pages=224–232|doi=10.1016/j.ympev.2005.03.030|issn=1055-7903|pmid=15890535}}
17. ^{{Cite journal|last=Elhaik|first=Eran|last2=Graur|first2=Dan|last3=Josić|first3=Kresimir|date=2010-01-01|title='Genome order index' should not be used for defining compositional constraints in nucleotide sequences--a case study of the Z-curve|journal=Biology Direct|volume=5|pages=10|doi=10.1186/1745-6150-5-10|issn=1745-6150|pmc=2841071|pmid=20158921}}
18. ^{{Cite journal|last=Zhang|first=Ren|date=2011-02-16|title=A rebuttal to the comments on the genome order index and the Z-curve|journal=Biology Direct|language=En|volume=6|issue=1|doi=10.1186/1745-6150-6-10|pmc=3046898|pmid=21324187|page=10}}
19. ^{{Cite journal|last=Deng|first=Xuegong|last2=Deng|first2=Xuemei|last3=Rayner|first3=Simon|last4=Liu|first4=Xiangdong|last5=Zhang|first5=Qingling|last6=Yang|first6=Yupu|last7=Li|first7=Ning|date=2008-05-01|title=DHPC: A new tool to express genome structural features|journal=Genomics|volume=91|issue=5|pages=476–483|doi=10.1016/j.ygeno.2008.01.003|pmid=18343093}}
External links
- The Z curve database
- {{cite web |title=Ori-Finder |publisher=Centre of Bioinformatics, Tianjin University (TUBIC) |url=http://tubic.tju.edu.cn/Ori-Finder/}} — a free, web-based program for predicting "origins of replication" using Z-curves.
- ENCODE threads explorer Three-dimensional connections across the genome. Nature (journal)
- ZCurve
- Introduction to Z curves. http://tubic.tju.edu.cn/zcurve/introduce.php
- Identify Gene Start Sites Using Z curves. http://tubic.tju.edu.cn/GS-Finder/
- King Zahir of Afghanistan
- King Zhao of Zhou
- King Zhending of Zhou
- King Zheng
- King Zheng of Ch'in
- King Zheng of Chin
- King Zheng of Qin
- King Zhou of Shang
- King Zhuang of Chu
- King Zhuang of Zhou
- King Zhuangxiang of Qin
- King Zhèng of Qín
- King Zimri
- King Zog
- King Zog of Albania
- King Zogu
- King Zora
- King Zygmunt's Column
- King Ælfred
- King Æthelbald
- King Æthelbald of Mercia
- King–Byng affair
- King–Crane Commission
- King’s College, Cambridge
- King’s Singers