- Definition Parameters
- The meaning of the word AIXI
- Optimality
- Computational aspects
- See also
- References
AIXI {{IPA-all|'ai̯k͡siː|}} is a theoretical mathematical formalism for artificial general intelligence.
It combines Solomonoff induction with sequential decision theory.
AIXI was first proposed by Marcus Hutter in 2000[1] and several results regarding AIXI are proved in Hutter's 2005 book Universal Artificial Intelligence.[2]
AIXI is a reinforcement learning agent. It maximizes the expected total rewards received from the environment. Intuitively, it simultaneously considers every computable hypothesis (or environment). In each time step, it looks at every possible program and evaluates how many rewards that program generates depending on the next action taken. The promised rewards are then weighted by the subjective belief that this program constitutes the true environment. This belief is computed from the length of the program: longer programs are considered less likely, in line with Occam's razor. AIXI then selects the action that has the highest expected total reward in the weighted sum of all these programs.
Definition
AIXI is a reinforcement learning agent that interacts with some stochastic and unknown but computable environment  . The interaction proceeds in time steps, from
. The interaction proceeds in time steps, from  to
to 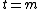 , where
, where  is the lifespan of the AIXI agent. At time step t, the agent chooses an action
is the lifespan of the AIXI agent. At time step t, the agent chooses an action 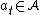 (e.g. a limb movement) and executes it in the environment, and the environment responds with a "percept"
(e.g. a limb movement) and executes it in the environment, and the environment responds with a "percept" 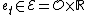 , which consists of an "observation"
, which consists of an "observation" 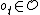 (e.g., a camera image) and a reward
(e.g., a camera image) and a reward 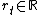 , distributed according to the conditional probability
, distributed according to the conditional probability 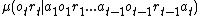 , where
, where 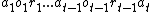 is the "history" of actions, observations and rewards. The environment is thus mathematically represented as a probability distribution over "percepts" (observations and rewards) which depend on the full history, so there is no Markov assumption (as opposed to other RL algorithms). Note again that this probability distribution is unknown to the AIXI agent. Furthermore, note again that is computable, that is, the observations and rewards received by the agent from the environment can be computed by some program (which runs on a Turing machine), given the past actions of the AIXI agent [3].
is the "history" of actions, observations and rewards. The environment is thus mathematically represented as a probability distribution over "percepts" (observations and rewards) which depend on the full history, so there is no Markov assumption (as opposed to other RL algorithms). Note again that this probability distribution is unknown to the AIXI agent. Furthermore, note again that is computable, that is, the observations and rewards received by the agent from the environment can be computed by some program (which runs on a Turing machine), given the past actions of the AIXI agent [3].
The only goal of the AIXI agent is to maximise 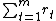 , that is, the sum of rewards from time step 1 to m.
, that is, the sum of rewards from time step 1 to m.
The AIXI agent is associated with a stochastic policy 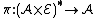 , which is the function it uses to choose actions at every time step, where
, which is the function it uses to choose actions at every time step, where 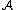 is the space of all possible actions that AIXI can take and
is the space of all possible actions that AIXI can take and  is the space of all possible "percepts" that can be produced by the environment. The environment (or probability distribution) can also be thought of as a stochastic policy (which is a function):
is the space of all possible "percepts" that can be produced by the environment. The environment (or probability distribution) can also be thought of as a stochastic policy (which is a function): 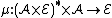 , where the
, where the  is the Kleene star operation.
is the Kleene star operation.
In general, at time step  (which ranges from 1 to m), AIXI, having previously executed actions
(which ranges from 1 to m), AIXI, having previously executed actions 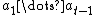 (which is often abbreviated in the literature as
(which is often abbreviated in the literature as 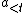 ) and having observed the history of percepts
) and having observed the history of percepts 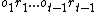 (which can be abbreviated as
(which can be abbreviated as 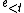 ), chooses and executes in the environment the action,
), chooses and executes in the environment the action,  , defined as follows [4]
, defined as follows [4]
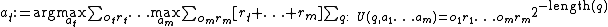
or, using parentheses, to disambiguate the precedences
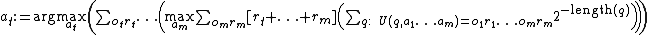
Intuitively, in the definition above, AIXI considers the sum of the total reward over all possible "futures" up to 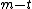 time steps ahead (that is, from to
time steps ahead (that is, from to  ), weighs each of them by the complexity of programs
), weighs each of them by the complexity of programs  (that is, by
(that is, by 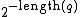 ) consistent with the agent's past (that is, the previously executed actions, , and received percepts, ) that can generate that future, and then picks the action that maximises expected future rewards [3].
) consistent with the agent's past (that is, the previously executed actions, , and received percepts, ) that can generate that future, and then picks the action that maximises expected future rewards [3].
Let us break this definition down in order to attempt to fully understand it.
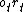 is the "percept" (which consists of the observation
is the "percept" (which consists of the observation 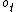 and reward
and reward 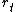 ) received by the AIXI agent at time step from the environment (which is unknown and stochastic). Similarly,
) received by the AIXI agent at time step from the environment (which is unknown and stochastic). Similarly, 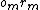 is the percept received by AIXI at time step (the last time step where AIXI is active).
is the percept received by AIXI at time step (the last time step where AIXI is active).
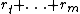 is the sum of rewards from time step to time step , so AIXI needs to look into the future to choose its action at time step .
is the sum of rewards from time step to time step , so AIXI needs to look into the future to choose its action at time step .
 denotes a monotone universal Turing machine, and ranges over all (deterministic) programs on the universal machine , which receives as input the program and the sequence of actions
denotes a monotone universal Turing machine, and ranges over all (deterministic) programs on the universal machine , which receives as input the program and the sequence of actions 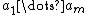 (that is, all actions), and produces the sequence of percepts
(that is, all actions), and produces the sequence of percepts 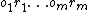 . The universal Turing machine is thus used to "simulate" or compute the environment responses or percepts, given the program (which "models" the environment) and all actions of the AIXI agent: in this sense, the environment is "computable" (as stated above). Note that, in general, the program which "models" the current and actual environment (where AIXI needs to act) is unknown because the current environment is also unknown.
. The universal Turing machine is thus used to "simulate" or compute the environment responses or percepts, given the program (which "models" the environment) and all actions of the AIXI agent: in this sense, the environment is "computable" (as stated above). Note that, in general, the program which "models" the current and actual environment (where AIXI needs to act) is unknown because the current environment is also unknown.
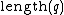 is the length of the program (which is encoded as a string of bits). Note that
is the length of the program (which is encoded as a string of bits). Note that 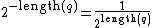 . Hence, in the definition above,
. Hence, in the definition above, 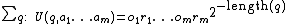 should be interpreted as a mixture (in this case, a sum) over all computable environments (which are consistent with the agent's past), each weighted by its complexity . Note that
should be interpreted as a mixture (in this case, a sum) over all computable environments (which are consistent with the agent's past), each weighted by its complexity . Note that 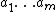 can also be written as
can also be written as 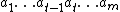 , and
, and 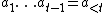 is the sequence of actions already executed in the environment by the AIXI agent. Similarly,
is the sequence of actions already executed in the environment by the AIXI agent. Similarly, 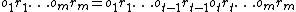 , and
, and 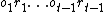 is the sequence of percepts produced by the environment so far.
is the sequence of percepts produced by the environment so far.
Let us now put all these components together in order to understand this equation or definition.
At time step t, AIXI chooses the action where the function 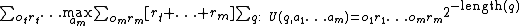 attains its maximum.
attains its maximum.
Parameters
The parameters to AIXI are the universal Turing machine U and the agent's lifetime m, which need to be chosen. The latter parameter can be removed by the use of discounting.
The meaning of the word AIXI
According to Hutter, the word "AIXI" can have several interpretations. AIXI can stand for AI based on Solomonoff's distribution, denoted by  (which is the Greek letter xi), or e.g. it can stand for AI "crossed" (X) with induction (I). There are other interpretations.
(which is the Greek letter xi), or e.g. it can stand for AI "crossed" (X) with induction (I). There are other interpretations.
Optimality
AIXI's performance is measured by the expected total number of rewards it receives.
AIXI has been proven to be optimal in the following ways.[2]
- Pareto optimality: there is no other agent that performs at least as well as AIXI in all environments while performing strictly better in at least one environment.{{citation needed|date=June 2014}}
- Balanced Pareto optimality: Like Pareto optimality, but considering a weighted sum of environments.
- Self-optimizing: a policy p is called self-optimizing for an environment if the performance of p approaches the theoretical maximum for when the length of the agent's lifetime (not time) goes to infinity. For environment classes where self-optimizing policies exist, AIXI is self-optimizing.
It was later shown by Hutter and Jan Leike that balanced Pareto optimality is subjective and that any policy can be considered Pareto optimal, which they describe as undermining all previous optimality claims for AIXI.[5]
However, AIXI does have limitations. It is restricted to maximizing rewards based on percepts as opposed to external states. It also assumes it interacts with the environment solely through action and percept channels, preventing it from considering the possibility of being damaged or modified. Colloquially, this means that it doesn't consider itself to be contained by the environment it interacts with. It also assumes the environment is computable.[6] Since AIXI is incomputable (see below), it assigns zero probability to its own existence{{citation needed|date=October 2017}}.
Computational aspects
Like Solomonoff induction, AIXI is incomputable. However, there are computable approximations of it. One such approximation is AIXItl, which performs at least as well as the provably best time t and space l limited agent.[2] Another approximation to AIXI with a restricted environment class is MC-AIXI (FAC-CTW) (which stands for Monte Carlo AIXI FAC-Context-Tree Weighting), which has had some success playing simple games such as partially observable Pac-Man.[7][8]
See also
- Gödel machine
References
2. ^1 2 {{cite book |author=Marcus Hutter |title=Universal Artificial Intelligence: Sequential Decisions Based on Algorithmic Probability |url=https://books.google.com/books?id=NP53iZGt4KUC |year=2004 |publisher=Springer |isbn=978-3-540-22139-5 |doi=10.1007/b138233 |ref=harv |authormask=1}}
3. ^1 {{cite arXiv |last1=Veness |first1=Joel |author2=Kee Siong Ng |last3=Hutter |first3=Marcus |last4=Uther |first4=William |last5=Silver |first5=David |eprint=0909.0801 |title=A Monte Carlo AIXI Approximation |year=2009 |class=cs.AI}}
4. ^Universal Artificial Intelligence
5. ^{{cite conference|conference=Proceedings of the 28th Conference on Learning Theory|last1=Leike|first1=Jan|last2=Hutter|first2=Marcus|title=Bad Universal Priors and Notions of Optimality|date=2015|url=http://proceedings.mlr.press/v40/Leike15.pdf}}
6. ^{{cite web|last1=Soares|first1=Nate|title=Formalizing Two Problems of Realistic World-Models|url=https://intelligence.org/files/RealisticWorldModels.pdf|website=Intelligence.org|accessdate=2015-07-19|ref=MIRI}}
7. ^{{cite arXiv |last1=Veness |first1=Joel |author2=Kee Siong Ng |last3=Hutter |first3=Marcus |last4=Uther |first4=William |last5=Silver |first5=David |eprint=0909.0801 |title=A Monte Carlo AIXI Approximation |year=2009 |class=cs.AI}}
8. ^[https://www.youtube.com/watch?v=yfsMHtmGDKE Playing Pacman using AIXI Approximation - YouTube]
- "Universal Algorithmic Intelligence: A mathematical top->down approach", Marcus Hutter, {{arXiv|cs/0701125}}; also in Artificial General Intelligence, eds. B. Goertzel and C. Pennachin, Springer, 2007, {{ISBN|9783540237334}}, pp. 227–290, {{doi|10.1007/978-3-540-68677-4_8}}.
- William Raimond Baird
- William Rainach
- William Rainach, Sr.
- William Rainborough
- William Raine Marshall
- William Rainsborough
- William Rainsborowe
- William Raleigh
- William Raleigh Hull Jr.
- William R. Alford
- William Ralls Morrison
- William Ralph Emerson
- William Ralph Shockley
- William Ramallo
- William Ramsay (disambiguation)
- William Ramsay (manufacturer)
- William Ramsay McNab
- William Ramsay Smith
- William Ramsden
- William Ramsden (British Army officer)
- William Ramsey
- William Ramsey Clark
- William Ramsey (disambiguation)
- William Ramseyer
- William Ramsey Laird