- Image representation based on the BoW model Feature representation Codebook generation
- Learning and recognition based on the BoW model Generative models Naïve Bayes Hierarchical Bayesian models Discriminative models Pyramid match kernel
- Limitations and recent developments
- See also
- References
- External links
In computer vision, the bag-of-words model (BoW model) can be applied to image classification, by treating image features as words. In document classification, a bag of words is a sparse vector of occurrence counts of words; that is, a sparse histogram over the vocabulary. In computer vision, a bag of visual words is a vector of occurrence counts of a vocabulary of local image features.
Image representation based on the BoW model
To represent an image using the BoW model, an image can be treated as a document. Similarly, "words" in images need to be defined too. To achieve this, it usually includes following three steps: feature detection, feature description, and codebook generation.[1]
A definition of the BoW model can be the "histogram representation based on independent features".[2] Content based image indexing and retrieval (CBIR) appears to be the early adopter of this image representation technique.[3]
Feature representation
After feature detection, each image is abstracted by several local patches. Feature representation methods deal with how to represent the patches as numerical vectors. These vectors are called feature descriptors. A good descriptor should have the ability to handle intensity, rotation, scale and affine variations to some extent. One of the most famous descriptors is Scale-invariant feature transform (SIFT).[4] SIFT converts each patch to 128-dimensional vector. After this step, each image is a collection of vectors of the same dimension (128 for SIFT), where the order of different vectors is of no importance.
Codebook generation
The final step for the BoW model is to convert vector-represented patches to "codewords" (analogous to words in text documents), which also produces a "codebook" (analogy to a word dictionary). A codeword can be considered as a representative of several similar patches. One simple method is performing k-means clustering over all the vectors.[5] Codewords are then defined as the centers of the learned clusters. The number of the clusters is the codebook size (analogous to the size of the word dictionary).
Thus, each patch in an image is mapped to a certain codeword through the clustering process and the image can be represented by the histogram of the codewords.
Learning and recognition based on the BoW model
Computer vision researchers have developed several learning methods to leverage the BoW model for image related tasks, such as object categorization. These methods can roughly be divided into two categories, generative and discriminative models. For multiple label categorization problem, the confusion matrix can be used as an evaluation metric.
Generative models
Here are some notations for this section. Suppose the size of codebook is  .
.
-
 : each patch is a V-dimensional vector that has a single component that equals to one and all other components equal to zero (For k-means clustering setting, the single component equal one indicates the cluster that belongs to). The
: each patch is a V-dimensional vector that has a single component that equals to one and all other components equal to zero (For k-means clustering setting, the single component equal one indicates the cluster that belongs to). The  th codeword in the codebook can be represented as
th codeword in the codebook can be represented as 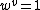 and
and 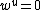 for
for  .
. -
 : each image is represented by
: each image is represented by 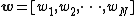 , all the patches in an image
, all the patches in an image -
 : the
: the  th image in an image collection
th image in an image collection -
 : category of the image
: category of the image -
 : theme or topic of the patch
: theme or topic of the patch -
 : mixture proportion
: mixture proportion
Since the BoW model is an analogy to the BoW model in NLP, generative models developed in text domains can also be adapted in computer vision. Simple Naïve Bayes model and hierarchical Bayesian models are discussed.
Naïve Bayes
The simplest one is Naïve Bayes classifier.[6] Using the language of graphical models, the Naïve Bayes classifier is described by the equation below. The basic idea (or assumption) of this model is that each category has its own distribution over the codebooks, and that the distributions of each category are observably different. Take a face category and a car category for an example. The face category may emphasize the codewords which represent "nose", "eye" and "mouth", while the car category may emphasize the codewords which represent "wheel" and "window". Given a collection of training examples, the classifier learns different distributions for different categories. The categorization decision is made by
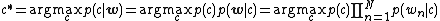
Since the Naïve Bayes classifier is simple yet effective, it is usually used as a baseline method for comparison.
Hierarchical Bayesian models
The basic assumption of Naïve Bayes model does not hold sometimes. For example, a natural scene image may contain several different themes.
Probabilistic latent semantic analysis (pLSA)[7][8] and latent Dirichlet allocation (LDA)[9] are two popular topic models from text domains to tackle the similar multiple "theme" problem. Take LDA for an example. To model natural scene images using LDA, an analogy is made with document analysis:
- the image category is mapped to the document category;
- the mixture proportion of themes maps the mixture proportion of topics;
- the theme index is mapped to topic index;
- the codeword is mapped to the word.
This method shows very promising results in natural scene categorization on 13 Natural Scene Categories.[1]
Discriminative models
Since images are represented based on the BoW model, any discriminative model suitable for text document categorization can be tried, such as support vector machine (SVM)[6] and AdaBoost.[10] Kernel trick is also applicable when kernel based classifier is used, such as SVM. Pyramid match kernel is newly developed one based on the BoW model. The local feature approach of using BoW model representation learnt by machine learning classifiers with different kernels (e.g., EMD-kernel and 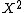 kernel) has been vastly tested in the area of texture and object recognition.[11] Very promising results on a number of datasets have been reported.
kernel) has been vastly tested in the area of texture and object recognition.[11] Very promising results on a number of datasets have been reported.
This approach[11] has achieved very impressive results in the PASCAL Visual Object Classes Challenge.
Pyramid match kernel
Pyramid match kernel[12] is a fast algorithm (linear complexity instead of classic one in quadratic complexity) kernel function (satisfying Mercer's condition) which maps the BoW features, or set of features in high dimension, to multi-dimensional multi-resolution histograms. An advantage of these multi-resolution histograms is their ability to capture co-occurring features. The pyramid match kernel builds multi-resolution histograms by binning data points into discrete regions of increasing size. Thus, points that do not match at high resolutions have the chance to match at low resolutions. The pyramid match kernel performs an approximate similarity match, without explicit search or computation of distance. Instead, it intersects the histograms to approximate the optimal match. Accordingly, the computation time is only linear in the number of features. Compared with other kernel approaches, the pyramid match kernel is much faster, yet provides equivalent accuracy. The pyramid match kernel was applied to [https://web.archive.org/web/20080124115650/http://www.mis.informatik.tu-darmstadt.de/Research/Projects/categorization/eth80-db.html ETH-80 database] and [https://web.archive.org/web/20080121104826/http://vision.cs.princeton.edu/resources_links.html Caltech 101 database] with promising results.[12][13]
Limitations and recent developments
One of the notorious disadvantages of BoW is that it ignores the spatial relationships among the patches, which are very important in image representation. Researchers have proposed several methods to incorporate the spatial information. For feature level improvements, correlogram features can capture spatial co-occurrences of features.[14] For generative models, relative positions[15][16] of codewords are also taken into account. The hierarchical shape and appearance model for human action[17] introduces a new part layer (Constellation model) between the mixture proportion and the BoW features, which captures the spatial relationships among parts in the layer. For discriminative models, spatial pyramid match[18] performs pyramid matching by partitioning the image into increasingly fine sub-regions and compute histograms of local features inside each sub-region. Recently, an augmentation of local image descriptors (i.e. SIFT) by their spatial coordinates normalised by the image width and height have proved to be a robust and simple Spatial Coordinate Coding[19][20] approach which introduces spatial information to the BoW model.
The BoW model has not been extensively tested yet for view point invariance and scale invariance, and the performance is unclear. Also the BoW model for object segmentation and localization is not well understood.[2]
A systematic comparison of classification pipelines found that the encoding of first and second order statistics (Vector of Locally Aggregated Descriptors (VLAD)[21] and Fisher Vector (FV)) considerably increased classification accuracy compared to BoW, while also decreasing the codebook size, thus lowering the computational effort for codebook generation.[22] Moreover, a recent detailed comparison of coding and pooling methods[20] for BoW has showed that second order statistics combined with Sparse Coding and an appropriate pooling such as Power Normalisation can further outperform Fisher Vectors and even approach results of simple models of Convolutional Neural Network on some object recognition datasets such as Oxford Flower Dataset 102.
See also
- Part-based models
- Fisher Vector encoding
- Segmentation-based object categorization
- Vector space model
- Bag-of-words model
- Feature extraction
References
2. ^1 {{cite web |author1=L. Fei-Fei |author2=R. Fergus |author3=A. Torralba |last-author-amp=yes | title = Recognizing and Learning Object Categories, CVPR 2007 short course | url=http://people.csail.mit.edu/torralba/shortCourseRLOC/index.html }}
3. ^{{cite journal|doi=10.1016/S0031-3203(01)00162-5|url=http://www.cs.nott.ac.uk/~qiu/webpages/Papers/ColorPatternRecognition.pdf|pages=1675–1686|title=Indexing chromatic and achromatic patterns for content-based colour image retrieval|year=2002|last1=Qiu|first1=G.|journal=Pattern Recognition|volume=35|issue=8}}
4. ^{{Cite book | chapter-url = http://www.cs.ubc.ca/~lowe/papers/iccv99.pdf | pages = 1150–1157 | year = 1999|doi=10.1109/ICCV.2003.1238356 | chapter = Object recognition with informative features and linear classification | title = Proceedings Ninth IEEE International Conference on Computer Vision | last1 = Vidal-Naquet | last2 = Ullman | isbn = 978-0-7695-1950-0 | citeseerx = 10.1.1.131.1283 }}
5. ^{{cite journal | author = T. Leung |author2=J. Malik |author2-link=Jitendra Malik| title = Representing and recognizing the visual appearance of materials using three-dimensional textons | url = http://www.cs.berkeley.edu/~malik/papers/LM-3dtexton.pdf | journal = International Journal of Computer Vision | volume = 43 | issue = 1 | pages = 29–44 | year = 2001 | doi = 10.1023/A:1011126920638 }}
6. ^1 {{cite conference |author1=G. Csurka |author2=C. Dance |author3=L.X. Fan |author4=J. Willamowski |author5=C. Bray |last-author-amp=yes | title = Visual categorization with bags of keypoints | booktitle = Proc. of ECCV International Workshop on Statistical Learning in Computer Vision | year=2004 | url=http://www.xrce.xerox.com/Research-Development/Publications/2004-010}}
7. ^{{cite conference |author = T. Hoffman |title = Probabilistic Latent Semantic Analysis |url = http://www.cs.brown.edu/~th/papers/Hofmann-UAI99.pdf |booktitle = Proc. of the Fifteenth Conference on Uncertainty in Artificial Intelligence |year = 1999 |conference = |access-date = 2007-12-10 |archive-url = https://web.archive.org/web/20070710083034/http://www.cs.brown.edu/~th/papers/Hofmann-UAI99.pdf |archive-date = 2007-07-10 |dead-url = yes |df = }}
8. ^{{Cite book | doi=10.1109/ICCV.2005.77 | title = Tenth IEEE International Conference on Computer Vision (ICCV'05) Volume 1 | chapter-url = http://www.robots.ox.ac.uk/~vgg/publications/papers/sivic05b.pdf | chapter=Discovering objects and their location in images | year=2005 | last1=Sivic | first1=J. | last2=Russell | first2=B.C. | last3=Efros | first3=A.A. | last4=Zisserman | first4=A. | last5=Freeman | first5=W.T. | isbn=978-0-7695-2334-7 | pages=370| citeseerx = 10.1.1.184.1253 }}
9. ^{{cite journal |author = D. Blei |author2 = A. Ng |author3 = M. Jordan |last-author-amp = yes |title = Latent Dirichlet allocation |url = http://www.cs.princeton.edu/~blei/papers/BleiNgJordan2003.pdf |journal = Journal of Machine Learning Research |volume = 3 |pages = 993–1022 |year = 2003 |doi = 10.1162/jmlr.2003.3.4-5.993 |editor1-last = Lafferty |editor1-first = John |issue = 4–5 |access-date = 2007-12-10 |archive-url = https://web.archive.org/web/20080822212053/http://www.cs.princeton.edu/~blei/papers/BleiNgJordan2003.pdf |archive-date = 2008-08-22 |dead-url = yes |df = }}
10. ^{{Cite book | doi=10.1109/CVPR.2005.254 | chapter-url = http://cbcl.mit.edu/projects/cbcl/publications/ps/serre-PID73457-05.pdf | chapter=Object Recognition with Features Inspired by Visual Cortex | title=2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05) | year=2005 | last1=Serre | first1=T. | last2=Wolf | first2=L. | last3=Poggio | first3=T. | isbn=978-0-7695-2372-9 | volume=2 | pages=994| citeseerx = 10.1.1.71.5276 }}
11. ^1 {{cite journal |author1=Jianguo Zhang |author2=Marcin Marszałek |author3=Svetlana Lazebnik |author4=Cordelia Schmid | title = Local Features and Kernels for Classification of Texture and Object Categories: a Comprehensive Study | journal = International Journal of Computer Vision | year = 2007| volume = 73 | issue = 2 | pages = 213–238 | url = http://lear.inrialpes.fr/pubs/2007/ZMLS07/ZhangMarszalekLazebnikSchmid-IJCV07-ClassificationStudy.pdf | doi = 10.1007/s11263-006-9794-4}}
12. ^1 {{Cite book | doi=10.1109/ICCV.2005.239 | chapter-url = http://www.cs.utexas.edu/~grauman/papers/grauman_darrell_iccv2005.pdf | chapter=The pyramid match kernel: discriminative classification with sets of image features | title=Tenth IEEE International Conference on Computer Vision (ICCV'05) Volume 1 | year=2005 | last1=Grauman | first1=K. | last2=Darrell | first2=T. | isbn=978-0-7695-2334-7 | pages=1458| citeseerx = 10.1.1.644.6159 }}
13. ^{{Cite book|chapter-url=http://www.ifp.illinois.edu/~jyang29/ScSPM.htm|doi=10.1109/CVPR.2009.5206757|chapter=Linear spatial pyramid matching using sparse coding for image classification|title=2009 IEEE Conference on Computer Vision and Pattern Recognition|year=2009|author=Jianchao Yang|last2=Kai Yu|last3=Yihong Gong|last4=Huang|first4=T.|isbn=978-1-4244-3992-8|pages=1794}}
14. ^{{Cite book |doi=10.1109/CVPR.2006.102| chapter-url = http://johnwinn.org/Publications/papers/Savarese_Winn_Criminisi_Correlatons_CVPR2006.pdf | year = 2006 |chapter=Discriminative Object Class Models of Appearance and Shape by Correlatons |title=2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition - Volume 2 (CVPR'06) |last1=Savarese |first1=S. |last2=Winn |first2=J. |last3=Criminisi |first3=A. |isbn=978-0-7695-2597-6 |volume=2 |pages=2033 | citeseerx = 10.1.1.587.8853 }}
15. ^{{Cite book|doi=10.1109/ICCV.2005.137 | chapter-url = http://ssg.mit.edu/~esuddert/papers/iccv05.pdf|chapter=Learning hierarchical models of scenes, objects, and parts|title=Tenth IEEE International Conference on Computer Vision (ICCV'05) Volume 1|year=2005|last1=Sudderth|first1=E.B.|last2=Torralba|first2=A.|last3=Freeman|first3=W.T.|last4=Willsky|first4=A.S.|isbn=978-0-7695-2334-7|pages=1331 | citeseerx = 10.1.1.128.7259}}
16. ^{{cite conference |author1=E. Sudderth |author2=A. Torralba |author3=W. Freeman |author4=A. Willsky |last-author-amp=yes | title = Describing Visual Scenes using Transformed Dirichlet Processes | url = http://ssg.mit.edu/~esuddert/papers/nips05.pdf | booktitle = Proc. of Neural Information Processing Systems | year = 2005 }}
17. ^{{Cite book|doi=10.1109/CVPR.2007.383132|chapter-url=http://vision.stanford.edu/posters/NieblesFeiFei_CVPR07_poster.pdf | year = 2007|chapter=A Hierarchical Model of Shape and Appearance for Human Action Classification|title=2007 IEEE Conference on Computer Vision and Pattern Recognition|last1=Niebles|first1=Juan Carlos|last2=Li Fei-Fei|isbn=978-1-4244-1179-5|pages=1 |citeseerx=10.1.1.173.2667 }}
18. ^{{Cite book|doi=10.1109/CVPR.2006.68 | chapter-url = http://www-cvr.ai.uiuc.edu/ponce_grp/publication/paper/cvpr06b.pdf | year = 2006|chapter=Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories|title=2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition - Volume 2 (CVPR'06)|last1=Lazebnik|first1=S.|last2=Schmid|first2=C.|last3=Ponce|first3=J.|isbn=978-0-7695-2597-6|volume=2|pages=2169 | citeseerx = 10.1.1.651.9183 }}
19. ^{{Cite journal|last=Koniusz|first=Piotr|last2=Yan|first2=Fei|last3=Mikolajczyk|first3=Krystian|date=2013-05-01|title=Comparison of mid-level feature coding approaches and pooling strategies in visual concept detection|journal=Computer Vision and Image Understanding|volume=117|issue=5|pages=479–492|doi=10.1016/j.cviu.2012.10.010|issn=1077-3142}}
20. ^1 {{Cite journal|last=Koniusz|first=Piotr|last2=Yan|first2=Fei|last3=Gosselin|first3=Philippe Henri|last4=Mikolajczyk|first4=Krystian|date=2017-02-24|title=Higher-order occurrence pooling for bags-of-words: Visual concept detection|journal=IEEE Transactions on Pattern Analysis and Machine Intelligence|volume=39|issue=2|pages=313–326|doi=10.1109/TPAMI.2016.2545667|pmid=27019477|issn=0162-8828}}
21. ^{{Cite book|last=Jégou|first=H.|last2=Douze|first2=M.|last3=Schmid|first3=C.|last4=Pérez|first4=P.|date=2010-06-01|title=Aggregating local descriptors into a compact image representation|journal=2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition|pages=3304–3311|doi=10.1109/CVPR.2010.5540039|isbn=978-1-4244-6984-0}}
22. ^{{Cite journal|last=Seeland|first=Marco|last2=Rzanny|first2=Michael|last3=Alaqraa|first3=Nedal|last4=Wäldchen|first4=Jana|last5=Mäder|first5=Patrick|date=2017-02-24|title=Plant species classification using flower images—A comparative study of local feature representations|journal=PLOS ONE|volume=12|issue=2|pages=e0170629|doi=10.1371/journal.pone.0170629|pmid=28234999|pmc=5325198|issn=1932-6203}}
External links
- A demo for two bag-of-words classifiers by L. Fei-Fei, R. Fergus, and A. Torralba.
- [https://web.archive.org/web/20101203074412/http://www.vision.caltech.edu/malaa/software/research/image-search/ Caltech Large Scale Image Search Toolbox]: a Matlab/C++ toolbox implementing Inverted File search for Bag of Words model. It also contains implementations for fast approximate nearest neighbor search using randomized k-d tree, locality-sensitive hashing, and hierarchical k-means.
- [https://github.com/dorian3d/DBoW2 DBoW2 library]: a library that implements a fast bag of words in C++ with support for OpenCV.
- Raja Bhalendra Singh
- Raja Bharmal
- Rajabhatkhawa, Alipurduar
- Rajabhau Ganeshrao Thakre
- Rajabhau Waje
- Rajabheema
- Raja Bheema
- Raja bin Ngah Ali
- Raja Bin Ngah Ali
- Rajabu Hussen
- Raja Chari
- Raja Chatila
- Raja Cheyyi Veste
- Raja Cheyyi Vesthe
- Raja Chor Mantri Sipahi
- Raja, Christopher
- Raja County
- Rajadamri
- Raja Dashrath Medical College
- Rajadeep
- Rajadhi
- Raja Dhi Raja
- Rajadhi Raja(2016)
- Rajadhi Raja (2016 film)
- Rajadhiraja St. Mary's Jacobite Syrian Cathedral, Piravom