- Overall strategy
- Data structures
- Detailed algorithm
- Analysis
- Special position
- Numerical precision issues
- Faster algorithms
- Notes
- References
- External links
In computational geometry, the Bentley–Ottmann algorithm is a sweep line algorithm for listing all crossings in a set of line segments, i.e. it finds the intersection points (or, simply, intersections) of line segments. It extends the Shamos–Hoey algorithm,{{sfnp|Shamos|Hoey|1976}} a similar previous algorithm for testing whether or not a set of line segments has any crossings. For an input consisting of  line segments with
line segments with  crossings (or intersections), the Bentley–Ottmann algorithm takes time
crossings (or intersections), the Bentley–Ottmann algorithm takes time 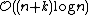 . In cases where
. In cases where 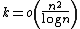 , this is an improvement on a naïve algorithm that tests every pair of segments, which takes
, this is an improvement on a naïve algorithm that tests every pair of segments, which takes  .
.
The algorithm was initially developed by {{harvs|first1=Jon|last1=Bentley|author1-link=Jon Bentley (computer scientist)|first2=Thomas|last2=Ottmann|year=1979|txt}}; it is described in more detail in the textbooks {{harvtxt|Preparata|Shamos|1985}}, {{harvtxt|O'Rourke|1998}}, and {{harvtxt|de Berg|van Kreveld|Overmars|Schwarzkopf|2000}}. Although asymptotically faster algorithms are now known by {{harvtxt|Chazelle|Edelsbrunner|1992}} and {{harvtxt|Balaban|1995}}, the Bentley–Ottmann algorithm remains a practical choice due to its simplicity and low memory requirements{{citation needed|reason=Link to robuts implementatinos, such as CGAL one, required.|date=March 2018}}.
Overall strategy
The main idea of the Bentley–Ottmann algorithm is to use a sweep line approach, in which a vertical line L moves from left to right (or, e.g., from top to bottom) across the plane, intersecting the input line segments in sequence as it moves.[1] The algorithm is described most easily in its general position, meaning:
- No two line segment endpoints or crossings have the same x-coordinate
- No line segment endpoint lies upon another line segment
- No three line segments intersect at a single point.
In such a case, L will always intersect the input line segments in a set of points whose vertical ordering changes only at a finite set of discrete events. Specifically, a discrete event can either be associated with an endpoint (left or right) of a line-segment or intersection point of two line-segments. Thus, the continuous motion of L can be broken down into a finite sequence of steps, and simulated by an algorithm that runs in a finite amount of time.
There are two types of events that may happen during the course of this simulation. When L sweeps across an endpoint of a line segment s, the intersection of L with s is added to or removed from the vertically ordered set of intersection points. These events are easy to predict, as the endpoints are known already from the input to the algorithm. The remaining events occur when L sweeps across a crossing between (or intersection of) two line segments s and t. These events may also be predicted from the fact that, just prior to the event, the points of intersection of L with s and t are adjacent in the vertical ordering of the intersection points{{clarify|reason=It may not be easy to visualize this concept without a simple animation, unless you already know the algorithm.|date=March 2018}}.
The Bentley–Ottmann algorithm itself maintains data structures representing the current vertical ordering of the intersection points of the sweep line with the input line segments, and a collection of potential future events formed by adjacent pairs of intersection points. It processes each event in turn, updating its data structures to represent the new set of intersection points.
Data structures
{{Confusing section|reason=it's not explained what internal and leaf nodes of the binary search tree represent. How are line segments compared to each other, while inserting, deleting or finding the predecessor or successor of a line segment? What makes a line segment the predecessor and successor of another line segment?|small='no'|date=March 2018}}In order to efficiently maintain the intersection points of the sweep line L with the input line segments and the sequence of future events, the Bentley–Ottmann algorithm maintains two data structures:
- A binary search tree (the "sweep line status tree"), containing the set of input line segments that cross L, ordered by the y-coordinates of the points where these segments cross L. The crossing points themselves are not represented explicitly in the binary search tree. The Bentley–Ottmann algorithm will insert a new segment s into this data structure when the sweep line L crosses the left endpoint p of this segment (i.e. the endpoint of the segment with the smallest x-coordinate, provided the sweep line L starts from the left, as explained above in this article). The correct position of segment s in the binary search tree may be determined by a binary search, each step of which tests whether p is above or below some other segment that is crossed by L. Thus, an insertion may be performed in logarithmic time. The Bentley–Ottmann algorithm will also delete segments from the binary search tree, and use the binary search tree to determine the segments that are immediately above or below other segments; these operations may be performed using only the tree structure itself without reference to the underlying geometry of the segments.
- A priority queue (the "event queue"), used to maintain a sequence of potential future events in the Bentley–Ottmann algorithm. Each event is associated with a point p in the plane, either a segment endpoint or a crossing point, and the event happens when line L sweeps over p. Thus, the events may be prioritized by the x-coordinates of the points associated with each event. In the Bentley–Ottmann algorithm, the potential future events consist of line segment endpoints that have not yet been swept over, and the points of intersection of pairs of lines containing pairs of segments that are immediately above or below each other.
The algorithm does not need to maintain explicitly a representation of the sweep line L or its position in the plane. Rather, the position of L is represented indirectly: it is the vertical line through the point associated with the most recently processed event.
The binary search tree may be any balanced binary search tree data structure, such as a red-black tree; all that is required is that insertions, deletions, and searches take logarithmic time. Similarly, the priority queue may be a binary heap or any other logarithmic-time priority queue; more sophisticated priority queues such as a Fibonacci heap are not necessary. Note that the space complexity of the priority queue depends on the data structure used to implement it.
Detailed algorithm
The Bentley–Ottmann algorithm performs the following steps.
- Initialize a priority queue Q of potential future events, each associated with a point in the plane and prioritized by the x-coordinate of the point. So, initially, Q contains an event for each of the endpoints of the input segments.
- Initialize a self-balancing binary search tree T of the line segments that cross the sweep line L, ordered by the y-coordinates of the crossing points. Initially, T is empty. (Even though the line sweep L is not explicitly represented, it may be helpful to imagine it as a vertical line which, initially, is at the left of all input segments.)
- While Q is nonempty, find and remove the event from Q associated with a point p with minimum x-coordinate. Determine what type of event this is and process it according to the following case analysis:
- If p is the left endpoint of a line segment s, insert s into T. Find the line-segments r and t that are respectively immediately above and below s in T (if they exist); if the crossing of r and t (the neighbours of s in the status data structure) forms a potential future event in the event queue, remove this possible future event from the event queue. If s crosses r or t, add those crossing points as potential future events in the event queue.
- If p is the right endpoint of a line segment s, remove s from T. Find the segments r and t that (prior to the removal of s) were respectively immediately above and below it in T (if they exist). If r and t cross, add that crossing point as a potential future event in the event queue.
- If p is the crossing point of two segments s and t (with s below t to the left of the crossing), swap the positions of s and t in T. After the swap, find the segments r and u (if they exist) that are immediately below and above t and s, respectively. Remove any crossing points rs (i.e. a crossing point between r and s) and tu (i.e. a crossing point between t and u) from the event queue, and, if r and t cross or s and u cross, add those crossing points to the event queue.
Analysis
The algorithm processes one event per segment endpoint or crossing point, in the sorted order of the  -coordinates of these points, as may be proven by induction. This follows because, once the
-coordinates of these points, as may be proven by induction. This follows because, once the 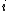 th event has been processed, the next event (if it is a crossing point) must be a crossing of two segments that are adjacent in the ordering of the segments represented by
th event has been processed, the next event (if it is a crossing point) must be a crossing of two segments that are adjacent in the ordering of the segments represented by 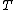 , and because the algorithm maintains all crossings between adjacent segments as potential future events in the event queue; therefore, the correct next event will always be present in the event queue. As a consequence, it correctly finds all crossings of input line segments, the problem it was designed to solve.
, and because the algorithm maintains all crossings between adjacent segments as potential future events in the event queue; therefore, the correct next event will always be present in the event queue. As a consequence, it correctly finds all crossings of input line segments, the problem it was designed to solve.
The Bentley–Ottmann algorithm processes a sequence of 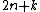 events, where denotes the number of input line segments and denotes the number of crossings. Each event is processed by a constant number of operations in the binary search tree and the event queue, and (because it contains only segment endpoints and crossings between adjacent segments) the event queue never contains more than
events, where denotes the number of input line segments and denotes the number of crossings. Each event is processed by a constant number of operations in the binary search tree and the event queue, and (because it contains only segment endpoints and crossings between adjacent segments) the event queue never contains more than 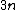 events. All operations take time
events. All operations take time 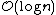 . Hence the total time for the algorithm is .
. Hence the total time for the algorithm is .
If the crossings found by the algorithm do not need to be stored once they have been found, the space used by the algorithm at any point in time is  : each of the input line segments corresponds to at most one node of the binary search tree T, and as stated above the event queue contains at most elements. This space bound is due to {{harvtxt|Brown|1981}}; the original version of the algorithm was slightly different (it did not remove crossing events from
: each of the input line segments corresponds to at most one node of the binary search tree T, and as stated above the event queue contains at most elements. This space bound is due to {{harvtxt|Brown|1981}}; the original version of the algorithm was slightly different (it did not remove crossing events from  when some other event causes the two crossing segments to become non-adjacent) causing it to use more space.[2]
when some other event causes the two crossing segments to become non-adjacent) causing it to use more space.[2]
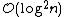 additional memory cells. However, in order to access the encoded information, the algorithm is slowed by a logarithmic factor.
additional memory cells. However, in order to access the encoded information, the algorithm is slowed by a logarithmic factor.Special position
The algorithm description above assumes that line segments are not vertical, that line segment endpoints do not lie on other line segments, that crossings are formed by only two line segments, and that no two event points have the same x-coordinate. In other words, it doesn't take into account corner cases, i.e. it assumes general position of the endpoints of the input segments. However, these general position assumptions are not reasonable for most applications of line segment intersection. {{harvtxt|Bentley|Ottmann|1979}} suggested perturbing the input slightly to avoid these kinds of numerical coincidences, but did not describe in detail how to perform these perturbations. {{harvtxt|de Berg|van Kreveld|Overmars|Schwarzkopf|2000}} describe in more detail the following measures for handling special-position inputs:
- Break ties between event points with the same x-coordinate by using the y-coordinate. Events with different y-coordinates are handled as before. This modification handles both the problem of multiple event points with the same x-coordinate, and the problem of vertical line segments: the left endpoint of a vertical segment is defined to be the one with the lower y-coordinate, and the steps needed to process such a segment are essentially the same as those needed to process a non-vertical segment with a very high slope.
- Define a line segment to be a closed set, containing its endpoints. Therefore, two line segments that share an endpoint, or a line segment that contains an endpoint of another segment, both count as an intersection of two line segments.
- When multiple line segments intersect at the same point, create and process a single event point for that intersection. The updates to the binary search tree caused by this event may involve removing any line segments for which this is the right endpoint, inserting new line segments for which this is the left endpoint, and reversing the order of the remaining line segments containing this event point. The output from the version of the algorithm described by {{harvtxt|de Berg|van Kreveld|Overmars|Schwarzkopf|2000}} consists of the set of intersection points of line segments, labeled by the segments they belong to, rather than the set of pairs of line segments that intersect.
A similar approach to degeneracies was used in the LEDA implementation of the Bentley–Ottmann algorithm.[3]
Numerical precision issues
For the correctness of the algorithm, it is necessary to determine without approximation the above-below relations between a line segment endpoint and other line segments, and to correctly prioritize different event points. For this reason it is standard to use integer coordinates for the endpoints of the input line segments, and to represent the rational number coordinates of the intersection points of two segments exactly, using arbitrary-precision arithmetic. However, it may be possible to speed up the calculations and comparisons of these coordinates by using floating point calculations and testing whether the values calculated in this way are sufficiently far from zero that they may be used without any possibility of error.[3] The exact arithmetic calculations required by a naïve implementation of the Bentley–Ottmann algorithm may require five times as many bits of precision as the input coordinates, but {{harvtxt|Boissonat|Preparata|2000}} describe modifications to the algorithm that reduce the needed amount of precision to twice the number of bits as the input coordinates.
Faster algorithms
The O(n log n) part of the time bound for the Bentley–Ottmann algorithm is necessary, as there are matching lower bounds for the problem of detecting intersecting line segments in algebraic decision tree models of computation.[4] However, the dependence on k, the number of crossings, can be improved. {{harvtxt|Clarkson|1988}} and {{harvtxt|Mulmuley|1988}} both provided randomized algorithms for constructing the planar graph whose vertices are endpoints and crossings of line segments, and whose edges are the portions of the segments connecting these vertices, in expected time O(n log n + k), and this problem of arrangement construction was solved deterministically in the same O(n log n + k) time bound by {{harvtxt|Chazelle|Edelsbrunner|1992}}. However, constructing this arrangement as a whole requires space O(n + k), greater than the O(n) space bound of the Bentley–Ottmann algorithm; {{harvtxt|Balaban|1995}} described a different algorithm that lists all intersections in time O(n log n + k) and space O(n).
If the input line segments and their endpoints form the edges and vertices of a connected graph (possibly with crossings), the O(n log n) part of the time bound for the Bentley–Ottmann algorithm may also be reduced. As {{harvtxt|Clarkson|Cole|Tarjan|1992}} show, in this case there is a randomized algorithm for solving the problem in expected time O(n log* n + k), where {{log-star}} denotes the iterated logarithm, a function much more slowly growing than the logarithm. A closely related randomized algorithm of {{harvtxt|Eppstein|Goodrich|Strash|2009}} solves the same problem in time O(n + k log(i)n) for any constant i, where log(i) denotes the function obtained by iterating the logarithm function i times. The first of these algorithms takes linear time whenever k is larger than n by a log(i)n factor, for any constant i, while the second algorithm takes linear time whenever k is smaller than n by a log(i)n factor. Both of these algorithms involve applying the Bentley–Ottmann algorithm to small random samples of the input.
Notes
2. ^The nonlinear space complexity of the original version of the algorithm was analyzed by {{harvtxt|Pach|Sharir|1991}}.
3. ^1 {{harvtxt|Bartuschka|Mehlhorn|Näher|1997}}.
4. ^{{harvtxt|Preparata|Shamos|1985}}, Theorem 7.6, p. 280.
References
- {{citation|last=Balaban|first=I. J.|contribution=An optimal algorithm for finding segments intersections|title=Proc. 11th ACM Symp. Computational Geometry|year=1995|pages=211–219|doi=10.1145/220279.220302}}.
- {{citation|last1=Bartuschka|first1=U.|last2=Mehlhorn|first2=K.|author2-link=Kurt Mehlhorn|last3=Näher|first3=S.|contribution=A robust and efficient implementation of a sweep line algorithm for the straight line segment intersection problem|url=http://www.dsi.unive.it/~wae97/proceedings/|title=Proc. Worksh. Algorithm Engineering|year=1997|contribution-url=http://www.dsi.unive.it/~wae97/proceedings/ONLY_PAPERS/pap13.ps.gz|editor1-first=G. F.|editor1-last=Italiano|editor1-link=Giuseppe F. Italiano|editor2-first=S.|editor2-last=Orlando}}.
- {{citation|last1=Bentley|first1=J. L.|author1-link=Jon Bentley (computer scientist)|last2=Ottmann|first2=T. A.|title=Algorithms for reporting and counting geometric intersections|journal=IEEE Transactions on Computers|volume=C-28|issue=9|pages=643–647|year=1979|doi=10.1109/TC.1979.1675432}}.
- {{citation|last1=de Berg|first1=Mark|last2=van Kreveld|first2=Marc|last3=Overmars|first3=Mark|author3-link=Mark Overmars|last4=Schwarzkopf|first4=Otfried|title=Computational Geometry|publisher=Springer-Verlag|year=2000|isbn=978-3-540-65620-3|edition=2nd|chapter=Chapter 2: Line segment intersection|pages=19–44}}.
- {{citation|last1=Boissonat|first1=J.-D.|last2=Preparata|first2=F. P.|author2-link=Franco P. Preparata|title=Robust plane sweep for intersecting segments|journal=SIAM Journal on Computing|year=2000|url=http://www.cs.brown.edu/research/pubs/pdfs/2000/Boissonnat-2000-RPS.pdf|doi=10.1137/S0097539797329373|volume=29|issue=5|pages=1401–1421}}.
- {{citation|last=Brown|first=K. Q.|title=Comments on "Algorithms for Reporting and Counting Geometric Intersections"|journal=IEEE Transactions on Computers|year=1981|volume=C-30|issue=2|page=147|doi=10.1109/tc.1981.6312179}}.
- {{citation|last1=Chazelle|first1=Bernard|author1-link=Bernard Chazelle|last2=Edelsbrunner|first2=Herbert|author2-link=Herbert Edelsbrunner|title=An optimal algorithm for intersecting line segments in the plane|journal=Journal of the ACM|volume=39|issue=1|pages=1–54|year=1992|doi=10.1145/147508.147511}}.
- {{citation|last1=Chen|first1=E. Y.|last2=Chan|first2=T. M.|author2-link=Timothy M. Chan|contribution=A space-efficient algorithm for segment intersection|title=Proc. 15th Canadian Conference on Computational Geometry|year=2003|url=http://www.cccg.ca/proceedings/2003/31.pdf}}.
- {{citation|last=Clarkson|first=K. L.|authorlink=Kenneth L. Clarkson|contribution=Applications of random sampling in computational geometry, II|title=Proc. 4th ACM Symp. Computational Geometry|pages=1–11|year=1988|doi=10.1145/73393.73394}}.
- {{citation|last1=Clarkson|first1=K. L.|author1-link=Kenneth L. Clarkson|last2=Cole|first2=R.|last3=Tarjan|first3=R. E.|author3-link=Robert Tarjan|title=Randomized parallel algorithms for trapezoidal diagrams|journal=International Journal of Computational Geometry and Applications|volume=2|issue=2|year=1992|pages=117–133|doi=10.1142/S0218195992000081}}. Corrigendum, 2 (3): 341–343.
- {{citation|last1=Eppstein|first1=D.|author1-link=David Eppstein|last2=Goodrich|first2=M. |author2-link=Michael T. Goodrich|last3=Strash|first3=D.|contribution=Linear-time algorithms for geometric graphs with sublinearly many crossings|title=Proc. 20th ACM-SIAM Symp. Discrete Algorithms (SODA 2009)|year=2009|pages=150–159|arxiv=0812.0893|bibcode=2008arXiv0812.0893E}}.
- {{citation|last=Mulmuley|first=K.|authorlink=Ketan Mulmuley|contribution=A fast planar partition algorithm, I|title=Proc. 29th IEEE Symp. Foundations of Computer Science (FOCS 1988)|year=1988|pages=580–589|doi=10.1109/SFCS.1988.21974}}.
- {{citation|last=O'Rourke|first=J.|authorlink= Joseph O'Rourke (professor)|title=Computational Geometry in C|edition=2nd|publisher=Cambridge University Press|year=1998|isbn=978-0-521-64976-6|chapter=Section 7.7: Intersection of segments|pages=263–265}}.
- {{citation|last1=Preparata|first1=F. P.|author1-link=Franco P. Preparata|last2=Shamos|first2=M. I.|author2-link=Michael Ian Shamos|title=Computational Geometry: An Introduction|publisher=Springer-Verlag|year=1985|chapter=Section 7.2.3: Intersection of line segments|pages=278–287}}.
- {{citation|last1=Pach|first1=J.|author1-link=János Pach|last2=Sharir|first2=M.|author2-link=Micha Sharir|title=On vertical visibility in arrangements of segments and the queue size in the Bentley–Ottmann line sweeping algorithm|journal=SIAM Journal on Computing|volume=20|year=1991|pages=460–470|issue=3|doi=10.1137/0220029|mr=1094525}}.
- {{citation|last1=Shamos|first1=M. I.|author1-link=Michael Ian Shamos|contribution=Geometric intersection problems|title=17th IEEE Conf. Foundations of Computer Science (FOCS 1976)|pages=208–215|year=1976|doi=10.1109/SFCS.1976.16|last2=Hoey|first2=Dan}}.
External links
- {{citation|url=http://www.scs.carleton.ca/~michiel/lecturenotes/ALGGEOM/bentley-ottmann.pdf|title=Computing intersections in a set of line segments: the Bentley–Ottmann algorithm|first=Michiel|last=Smid|year=2003}}.
- 5th Youth In Film Awards
- 5th Youth in Film Awards
- 5th ZAI Awards
- 5th Zaslaw Uhlan Regiment
- 5-Tiles
- 5tion
- 5' to 3' DNA helicase
- 5 to 7
- 5 To 7
- 5 to 7 (film)
- 5-TOM
- 5-ton
- 5-tone
- 5to piso
- 5 Towns Jewish Times
- 5 Tracks
- 5 Training Regiment RLC
- 5-tuple
- 5* (TV channel)
- 5-U
- 5u
- 5-u
- 5U (disambiguation)
- 5-uniform tiling
- 5. Unterseebootsflottille