- History
- Definition
- Algorithms STREAM Other Algorithms
- References
In computer science, data stream clustering is defined as the clustering of data that arrive continuously such as telephone records, multimedia data, financial transactions etc. Data stream clustering is usually studied as a streaming algorithm and the objective is, given a sequence of points, to construct a good clustering of the stream, using a small amount of memory and time.
History
Data stream clustering has recently attracted attention for emerging applications that involve large amounts of streaming data. For clustering, k-means is a widely used heuristic but alternate algorithms have also been developed such as k-medoids, CURE and the popular{{cn|date=July 2017}} BIRCH. For data streams, one of the first results appeared in 1980[1] but the model was formalized in 1998.[2]
Definition
The problem of data stream clustering is defined as:
Input: a sequence of n points in metric space and an integer k.Output: k centers in the set of the n points so as to minimize the sum of distances from data points to their closest cluster centers.
This is the streaming version of the k-median problem.
Algorithms
STREAM
STREAM is an algorithm for clustering data streams described by Guha, Mishra, Motwani and O'Callaghan[3] which achieves a constant factor approximation for the k-Median problem in a single pass and using small space.
{{math theorem | STREAM can solve the k-Median problem on a data stream in a single pass, with time O(n1+e) and space θ(nε) up to a factor 2O(1/e), where n the number of points and {{tmath|e<1/2}}.}}To understand STREAM, the first step is to show that clustering can take place in small space (not caring about the number of passes). Small-Space is a divide-and-conquer algorithm that divides the data, S, into  pieces, clusters each one of them (using k-means) and then clusters the centers obtained.
pieces, clusters each one of them (using k-means) and then clusters the centers obtained.
|1 = Divide S into
disjoint pieces 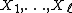 .
.|2 = For each i, find {{tmath|O(k)}} centers in Xi. Assign
each point in Xi to its closest center.
|3 = Let X be the
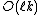 centers obtained in (2),
centers obtained in (2),where each center c is weighted by the number
of points assigned to it.
|4 = Cluster X' to find k centers.
}}
Where, if in Step 2 we run a bicriteria {{tmath|(a,b)}}-approximation algorithm which outputs at most ak medians with cost at most b times the optimum k-Median solution and in Step 4 we run a c-approximation algorithm then the approximation factor of Small-Space() algorithm is {{tmath|2c(1+2b)+2b}}. We can also generalize Small-Space so that it recursively calls itself i times on a successively smaller set of weighted centers and achieves a constant factor approximation to the k-median problem.
The problem with the Small-Space is that the number of subsets that we partition S into is limited, since it has to store in memory the intermediate medians in X. So, if M is the size of memory, we need to partition S into subsets such that each subset fits in memory, (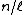 ) and so that the weighted
) and so that the weighted 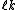 centers also fit in memory,
centers also fit in memory, 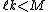 . But such an may not always exist.
. But such an may not always exist.
The STREAM algorithm solves the problem of storing intermediate medians and achieves better running time and space requirements. The algorithm works as follows:[3]
{{ordered list|1 = Input the first m points; using the randomized algorithm presented in[3] reduce these to {{tmath|O(k)}} (say 2k) points.
|2 = Repeat the above till we have seen m2/(2k) of the original data points. We now have m intermediate medians.
|3 = Using a local search algorithm, cluster these m first-level medians into 2k second-level medians and proceed.
|4 = In general, maintain at most m level-i medians, and, on seeing m, generate 2k level-i+ 1 medians, with the weight of a new median as the sum of the weights of the intermediate medians assigned to it.
|5 = When we have seen all the original data points, we cluster all the intermediate medians into k final medians, using the primal dual algorithm.[4]
}}
Other Algorithms
Other well-known algorithms used for data stream clustering are:
- BIRCH:[5] builds a hierarchical data structure to incrementally cluster the incoming points using the available memory and minimizing the amount of I/O required. The complexity of the algorithm is {{tmath|O(N)}} since one pass suffices to get a good clustering (though, results can be improved by allowing several passes).
- COBWEB:[6][7] is an incremental clustering technique that keeps a hierarchical clustering model in the form of a classification tree. For each new point COBWEB descends the tree, updates the nodes along the way and looks for the best node to put the point on (using a category utility function).
- C2ICM:[8] builds a flat partitioning clustering structure by selecting some objects as cluster seeds/initiators and a non-seed is assigned to the seed that provides the highest coverage, addition of new objects can introduce new seeds and falsify some existing old seeds, during incremental clustering new objects and the members of the falsified clusters are assigned to one of the existing new/old seeds.
References
2. ^{{cite journal | first1 = M. | last1 = Henzinger | first2 = P. | last2 = Raghavan | first3 = S. | last3 = Rajagopalan | citeseerx = 10.1.1.19.9554 | title = Computing on Data Streams | journal = Digital Equipment Corporation | volume = TR-1998-011 | date = August 1998 }}
3. ^1 2 {{cite paper | first1 = S. | last1 = Guha | first2 = N. | last2 = Mishra | first3 = R. | last3 = Motwani | first4 = L. | last4 = O'Callaghan | citeseerx = 10.1.1.32.1927 | title = Clustering Data Streams | journal = Proceedings of the Annual Symposium on Foundations of Computer Science | pages = 359–366 | date = 2000 }}
4. ^{{cite book | first1 = K. | last1 = Jain | first2 = V. | last2 = Vazirani | url = http://portal.acm.org/citation.cfm?id=796509 | title = Primal-dual approximation algorithms for metric facility location and k-median problems | journal = Proc. FOCS | pages = 2– | date = 1999 | isbn = 9780769504094 | series = Focs '99 }}
5. ^{{cite journal | first1 = T. | last1 = Zhang | first2 = R. | last2 = Ramakrishnan | first3 = M. | last3 = Linvy |doi=10.1145/235968.233324 | title = BIRCH: An Efficient Data Clustering Method for Very Large Databases | journal = Proceedings of the ACM SIGMOD Conference on Management of Data | date = 1996 | volume=25 | issue = 2 | pages=103–114}}
6. ^{{cite journal | first = D. H. | last = Fisher | title = Knowledge Acquisition Via Incremental Conceptual Clustering | journal = Machine Learning | date = 1987 | doi=10.1023/A:1022852608280 | volume=2 | issue = 2 | pages=139–172}}
7. ^{{cite journal | first = D. H. | last = Fisher | citeseerx = 10.1.1.6.9914 | title = Iterative Optimization and Simplification of Hierarchical Clusterings | journal = Journal of AI Research | volume = 4 | date = 1996 }}
8. ^{{cite journal | first = F. | last = Can | url = http://dl.acm.org/citation.cfm?doid=130226.134466 | title = Incremental Clustering for Dynamic Information Processing | journal = ACM Transactions on Information Systems | volume = 11 | issue = 2 | date = 1993 | pages = 143–164 | doi=10.1145/130226.134466}}
- Livin' on the Fault Line
- Livin' Thing
- Livio Agresti
- Livio Berruti
- Livio Catullo Stecchini
- Livio C. Stecchini
- Livio Dante Porta
- Livio Piomarta (S-515)
- Livio Piomarta (S515)
- Livistona
- Livita
- Liviu Dieter Nisipeanu
- Liviu-Dieter Nisipeanu
- Livius Andronicus
- Livius Andronicus, Lucius
- Livius Drusus
- Liv Kristine
- Liv Kristine Espenaes
- Livland
- Livland war
- Liv Lindeland
- Liv-Marit Bergman
- Livno
- Livonia
- Livonia, Avon and Lakeville Railroad