- Classification by query computational complexity Simple decision tree Linear decision tree Algebraic decision tree
- Classification by query computational model Deterministic decision tree Randomized decision tree Nondeterministic decision tree Quantum decision tree
- Relationship between different models
- See also
- References Surveys
In computational complexity and communication complexity theories the decision tree model is the model of computation or communication in which an algorithm or communication process is considered to be basically a decision tree, i.e., a sequence of branching operations based on comparisons of some quantities, the comparisons being assigned the unit computational cost.
The branching operations are called "tests" or "queries". In this setting the algorithm in question may be viewed as a computation of a Boolean function  where the input is a series of queries and the output is the final decision. Every query is dependent on previous queries.
where the input is a series of queries and the output is the final decision. Every query is dependent on previous queries.
Several variants of decision tree models have been introduced, depending on the complexity of the operations allowed in the computation of a single comparison and the way of branching.
Decision trees models are instrumental in establishing lower bounds for computational complexity for certain classes of computational problems and algorithms: the lower bound for worst-case computational complexity is proportional to the largest depth among the decision trees for all possible inputs for a given computational problem. The computation complexity of a problem or an algorithm expressed in terms of the decision tree model is called decision tree complexity or query complexity.
Classification by query computational complexity
Simple decision tree
The model in which every decision is based on the comparison of two numbers within constant time is called a decision tree model. It was introduced to establish computational complexity of sorting and searching.[1]
The simplest illustration of this lower bound technique is for the problem of finding the smallest number among n numbers using only comparisons. In this case the decision tree model is a binary tree. Algorithms for this searching problem may result in n different outcomes (since any of the n given numbers may turn out to be the smallest one). It is known that the depth of a binary tree with n leaves is at least  , which gives a lower bound of
, which gives a lower bound of  for the searching problem.
for the searching problem.
However this lower bound is known to be slack, since the following simple argument shows that at least n - 1 comparisons are needed: Before the smallest number can be determined, every number except the smallest must "lose" (compare greater) in at least one comparison.{{cn|date=July 2015}}
Along the same lines the lower bound of  for sorting may be proved. In this case, the existence of numerous comparison-sorting algorithms having this time complexity, such as mergesort and heapsort, demonstrates that the bound is tight.
for sorting may be proved. In this case, the existence of numerous comparison-sorting algorithms having this time complexity, such as mergesort and heapsort, demonstrates that the bound is tight.
Linear decision tree
Linear decision trees, just like the simple decision trees, make a branching decision based on a set of values as input. As opposed to binary decision trees, linear decision trees have three output branches. A linear function  is being tested and branching decisions are made based on the sign of the function (negative, positive, or 0).
is being tested and branching decisions are made based on the sign of the function (negative, positive, or 0).
Geometrically,  defines a hyperplane in Rn. A set of input values reaching any particular nodes represents the intersection of the half-planes defined by the nodes.
defines a hyperplane in Rn. A set of input values reaching any particular nodes represents the intersection of the half-planes defined by the nodes.
Algebraic decision tree
Algebraic decision trees are a generalization of linear decision trees to allow test functions to be polynomials of degree d. Geometrically, the space is divided into semi-algebraic sets (a generalization of hyperplane). The evaluation of the complexity is more difficult.
Classification by query computational model
Deterministic decision tree
If the output of a decision tree is , for all 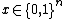 , the decision tree is said to "compute"
, the decision tree is said to "compute"  . The depth of a tree is the maximum number of queries that can happen before a leaf is reached and a result obtained.
. The depth of a tree is the maximum number of queries that can happen before a leaf is reached and a result obtained.  , the deterministic decision tree complexity of is the smallest depth among all deterministic decision trees that compute .
, the deterministic decision tree complexity of is the smallest depth among all deterministic decision trees that compute .
Randomized decision tree
One way to define a randomized decision tree is to add additional nodes to the tree, each controlled by a probability  . Another equivalent definition is to select a whole decision tree at the beginning from a set of decision trees based on a probability distribution. Based on this second definition, the complexity of the randomized tree is defined as the greatest depth among all the trees associated with probabilities greater than 0.
. Another equivalent definition is to select a whole decision tree at the beginning from a set of decision trees based on a probability distribution. Based on this second definition, the complexity of the randomized tree is defined as the greatest depth among all the trees associated with probabilities greater than 0. 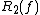 is defined as the complexity of the lowest-depth randomized decision tree whose result is with probability at least
is defined as the complexity of the lowest-depth randomized decision tree whose result is with probability at least  for all (i.e., with bounded 2-sided error).
for all (i.e., with bounded 2-sided error).
is known as the Monte Carlo randomized decision-tree complexity, because the result is allowed to be incorrect with bounded two-sided error. The Las Vegas decision-tree complexity 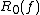 measures the expected depth of a decision tree that must be correct (i.e., has zero-error). There is also a one-sided bounded-error version known as
measures the expected depth of a decision tree that must be correct (i.e., has zero-error). There is also a one-sided bounded-error version known as  .
.
Nondeterministic decision tree
The nondeterministic decision tree complexity of a function is known more commonly as the certificate complexity of that function. It measures the number of input bits that a nondeterministic algorithm would need to look at in order to evaluate the function with certainty.
Quantum decision tree
The quantum decision tree complexity  is the depth of the lowest-depth quantum decision tree that gives the result with probability at least for all . Another quantity,
is the depth of the lowest-depth quantum decision tree that gives the result with probability at least for all . Another quantity,  , is defined as the depth of the lowest-depth quantum decision tree that gives the result with probability 1 in all cases (i.e. computes exactly). and are more commonly known as quantum query complexities, because the direct definition of a quantum decision tree is more complicated than in the classical case. Similar to the randomized case, we define
, is defined as the depth of the lowest-depth quantum decision tree that gives the result with probability 1 in all cases (i.e. computes exactly). and are more commonly known as quantum query complexities, because the direct definition of a quantum decision tree is more complicated than in the classical case. Similar to the randomized case, we define  and
and  .
.
Relationship between different models
{{Expert needed|reason=This article is out of date and needs to be updated to reflect recent results|date=November 2016}}It follows immediately from the definitions that for all  -bit Boolean functions ,
-bit Boolean functions ,
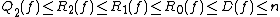 , and
, and  .
.
Blum and Impagliazzo,[2] Hartmanis and Hemachandra,[3] and Tardos[4] independently discovered that  . Noam Nisan found that the Monte Carlo randomized decision tree complexity is also polynomially related to deterministic decision tree complexity:
. Noam Nisan found that the Monte Carlo randomized decision tree complexity is also polynomially related to deterministic decision tree complexity:  .[5] (Nisan also showed that
.[5] (Nisan also showed that 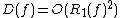 .) A tighter relationship is known between the Monte Carlo and Las Vegas models:
.) A tighter relationship is known between the Monte Carlo and Las Vegas models: 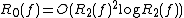 .[6] This relationship is optimal up to polylogarithmic factors.[7]
.[6] This relationship is optimal up to polylogarithmic factors.[7]
The quantum decision tree complexity is also polynomially related to . Midrijanis showed that 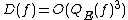 ,[8][9] improving a quartic bound due to Beals et al.[10] Beals et al. also showed that
,[8][9] improving a quartic bound due to Beals et al.[10] Beals et al. also showed that 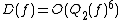 , and this is still the best known bound. However, the largest known gap between deterministic and quantum query complexities is only quadratic. A quadratic gap is achieved for the OR function;
, and this is still the best known bound. However, the largest known gap between deterministic and quantum query complexities is only quadratic. A quadratic gap is achieved for the OR function; 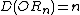 while
while 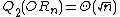 .
.
It is important to note that these polynomial relationships are valid only for total Boolean functions. For partial Boolean functions, that have a domain a subset of 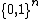 , an exponential separation between and is possible; the first example of such a problem was discovered by Deutsch and Jozsa.
, an exponential separation between and is possible; the first example of such a problem was discovered by Deutsch and Jozsa.
These relationships can be summarized by the following inequalities, which are true up to constant factors:[9]
- [2][3][4]
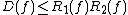 [5]
[5] [5]
[5]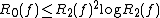 [6]
[6] [10]
[10] [10]
[10]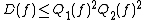 [11]
[11]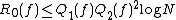 [12]
[12] [9]
[9]
See also
- Minimum spanning tree#Decision trees
References
2. ^1 {{cite conference | last = Blum | first=M. |author2=Impagliazzo, R. | title=Generic oracles and oracle classes | year=1987 | booktitle=Proceedings of 18th IEEE FOCS | pages=118–126}}
3. ^1 {{Citation | last1=Hartmanis | first1=J. | last2 = Hemachandra | first2=L. | year = 1987 | contribution=One-way functions, robustness, and non-isomorphism of NP-complete sets | title=Technical Report DCS TR86-796, Cornell University}}
4. ^1 {{cite journal | last=Tardos | first=G. | title=Query complexity, or why is it difficult to separate NPA ∩ coNPA from PA by random oracles A? | journal=Combinatorica | year=1989 | pages=385–392|volume=9 | doi=10.1007/BF02125350}}
5. ^1 2 {{cite conference | last=Nisan | first=N. | authorlink = Noam Nisan | title=CREW PRAMs and decision trees | year=1989 | booktitle=Proceedings of 21st ACM STOC | pages=327–335}}
6. ^1 Kulkarni, R. and Tal, A. On Fractional Block Sensitivity. Electronic Colloquium on Computational Complexity (ECCC). Vol. 20. 2013.
7. ^Ambainis, A., Balodis, K., Belovs, A., Lee, T., Santha, M., and Smotrovs, J. (2015). Separations in query complexity based on pointer functions. arXiv preprint arXiv:1506.04719.
8. ^{{Citation | last=Midrijanis | first=Gatis | year = 2004 | contribution= Exact quantum query complexity for total Boolean functions | title = arXiv:quant-ph/0403168 | arxiv=quant-ph/0403168| bibcode=2004quant.ph..3168M }}
9. ^1 2 {{Citation | last=Midrijanis | first=Gatis | year = 2005 | contribution= On randomized and quantum query complexities | title = arXiv:quant-ph/0501142 | arxiv=quant-ph/0501142| bibcode=2005quant.ph..1142M }}
10. ^1 2 {{cite journal | last=Beals | first=R. |author2=Buhrman, H. |author3=Cleve, R. |author4=Mosca, M. |author5= de Wolf, R. | year = 2001 | title= Quantum lower bounds by polynomials | journal =Journal of the ACM | volume=48 | pages=778–797 | doi=10.1145/502090.502097|arxiv=quant-ph/9802049 }}
11. ^H. Buhrman, R. Cleve, R. de Wolf, and Ch. Zalka. Bounds for Small-Error and Zero-Error Quantum Algorithms. In 40th IEEE Symposium on Foundations of Computer Science (FOCS'99), pp.358-368. cs.CC/9904019, 1999.
12. ^S. Aaronson. Quantum Certificate Complexity. IEEE Conference on Computational Complexity, pp. 171-178, 2003.
Surveys
- {{Citation
|last1 = Buhrman
|first1=Harry
|last2=de Wolf
|first2=Ronald
|title=Complexity Measures and Decision Tree Complexity: A Survey
|journal=Theoretical Computer Science
|volume=288
|number=1
|pages=21–43
|year=2002
|doi=10.1016/S0304-3975(01)00144-X
|url=http://homepages.cwi.nl/~rdewolf/publ/qc/dectree.pdf}}{{DEFAULTSORT:Decision Tree Model}}
- Bernard master
- Bernard Master
- Bernard Mathieu
- Bernard Maurey
- Bernard Mayeur
- Bernard M. Bass
- Bernard McIntyre
- Bernard McLean
- Bernard McNamee
- Bernard Meli
- Bernard Mendik
- Bernard Menetrel
- Bernard Menez
- Bernard Meyers
- Bernard Meynadier
- Bernard Miall
- Bernard, Michael
- Bernard Michael Gilroy
- Bernard Michael Houseal
- Bernard Michaux
- Bernard Mignot
- Bernard, Mike
- Bernard Miller (songwriter)
- Bernard Mlambo
- Bernard M. L. Ernst