- Overview
- Ensemble theory
- Ensemble size
- Common types of ensembles Bayes optimal classifier Bootstrap aggregating (bagging) Boosting Bayesian parameter averaging Bayesian model combination Bucket of models Stacking
- Implementations in statistics packages
- Ensemble learning applications Remote sensing Land cover mapping Change detection Computer security Distributed denial of service Malware Detection Intrusion detection Face recognition Emotion recognition Fraud detection Financial decision-making Medicine
- See also
- References
- Further reading
- External links
In statistics and machine learning, ensemble methods use multiple learning algorithms to obtain better predictive performance than could be obtained from any of the constituent learning algorithms alone.[1][2][3]
Unlike a statistical ensemble in statistical mechanics, which is usually infinite, a machine learning ensemble consists of only a concrete finite set of alternative models, but typically allows for much more flexible structure to exist among those alternatives.
Overview
Supervised learning algorithms are most commonly described{{by whom|date=December 2017}} as performing the task of searching through a hypothesis space to find a suitable hypothesis that will make good predictions with a particular problem.{{Citation needed|date=December 2017}} Even if the hypothesis space contains hypotheses that are very well-suited for a particular problem, it may be very difficult to find a good one. Ensembles combine multiple hypotheses to form a (hopefully) better hypothesis. The term ensemble is usually reserved for methods that generate multiple hypotheses using the same base learner.{{according to whom|date=December 2017}}
The broader term of multiple classifier systems also covers hybridization of hypotheses that are not induced by the same base learner.{{citation needed|date=December 2017}}
Evaluating the prediction of an ensemble typically requires more computation than evaluating the prediction of a single model, so ensembles may be thought of as a way to compensate for poor learning algorithms by performing a lot of extra computation. Fast algorithms such as decision trees are commonly used in ensemble methods (for example, random forests), although slower algorithms can benefit from ensemble techniques as well.
By analogy, ensemble techniques have been used also in unsupervised learning scenarios, for example in consensus clustering or in anomaly detection.
Ensemble theory
An ensemble is itself a supervised learning algorithm, because it can be trained and then used to make predictions. The trained ensemble, therefore, represents a single hypothesis. This hypothesis, however, is not necessarily contained within the hypothesis space of the models from which it is built. Thus, ensembles can be shown to have more flexibility in the functions they can represent. This flexibility can, in theory, enable them to over-fit the training data more than a single model would, but in practice, some ensemble techniques (especially bagging) tend to reduce problems related to over-fitting of the training data.{{citation needed|date=December 2017}}
Empirically, ensembles tend to yield better results when there is a significant diversity among the models.[4][5] Many ensemble methods, therefore, seek to promote diversity among the models they combine.[6][7] Although perhaps non-intuitive, more random algorithms (like random decision trees) can be used to produce a stronger ensemble than very deliberate algorithms (like entropy-reducing decision trees).[8] Using a variety of strong learning algorithms, however, has been shown to be more effective than using techniques that attempt to dumb-down the models in order to promote diversity.[9]
Ensemble size
While the number of component classifiers of an ensemble has a great impact on the accuracy of prediction, there is a limited number of studies addressing this problem. A priori determining of ensemble size and the volume and velocity of big data streams make this even more crucial for online ensemble classifiers. Mostly statistical tests were used for determining the proper number of components. More recently, a theoretical framework suggested that there is an ideal number of component classifiers for an ensemble such that having more or less than this number of classifiers would deteriorate the accuracy. It is called "the law of diminishing returns in ensemble construction." Their theoretical framework shows that using the same number of independent component classifiers as class labels gives the highest accuracy.[10][11]
Common types of ensembles
Bayes optimal classifier
The Bayes optimal classifier is a classification technique. It is an ensemble of all the hypotheses in the hypothesis space. On average, no other ensemble can outperform it.[12] The naive Bayes optimal classifier is a version of this that assumes that the data is conditionally independent on the class and makes the computation more feasible. Each hypothesis is given a vote proportional to the likelihood that the training dataset would be sampled from a system if that hypothesis were true. To facilitate training data of finite size, the vote of each hypothesis is also multiplied by the prior probability of that hypothesis. The Bayes optimal classifier can be expressed with the following equation:

where  is the predicted class,
is the predicted class,  is the set of all possible classes,
is the set of all possible classes,  is the hypothesis space,
is the hypothesis space,  refers to a probability, and
refers to a probability, and 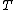 is the training data. As an ensemble, the Bayes optimal classifier represents a hypothesis that is not necessarily in . The hypothesis represented by the Bayes optimal classifier, however, is the optimal hypothesis in ensemble space (the space of all possible ensembles consisting only of hypotheses in ).
is the training data. As an ensemble, the Bayes optimal classifier represents a hypothesis that is not necessarily in . The hypothesis represented by the Bayes optimal classifier, however, is the optimal hypothesis in ensemble space (the space of all possible ensembles consisting only of hypotheses in ).
This formula can be restated using Bayes' theorem, which says that the posterior is proportional to the likelihood times the prior:

hence,

Bootstrap aggregating (bagging)
{{main|Bootstrap aggregating}}Bootstrap aggregating, often abbreviated as bagging, involves having each model in the ensemble vote with equal weight. In order to promote model variance, bagging trains each model in the ensemble using a randomly drawn subset of the training set. As an example, the random forest algorithm combines random decision trees with bagging to achieve very high classification accuracy.[13]
Boosting
{{main|Boosting (meta-algorithm)}}Boosting involves incrementally building an ensemble by training each new model instance to emphasize the training instances that previous models mis-classified. In some cases, boosting has been shown to yield better accuracy than bagging, but it also tends to be more likely to over-fit the training data. By far, the most common implementation of boosting is Adaboost, although some newer algorithms are reported to achieve better results.{{Citation needed|date=January 2012}}
Bayesian parameter averaging
Bayesian parameter averaging (BPA) is an ensemble technique that seeks to approximate the Bayes optimal classifier by sampling hypotheses from the hypothesis space, and combining them using Bayes' law.[14] Unlike the Bayes optimal classifier, Bayesian model averaging (BMA) can be practically implemented. Hypotheses are typically sampled using a Monte Carlo sampling technique such as MCMC. For example, Gibbs sampling may be used to draw hypotheses that are representative of the distribution  . It has been shown that under certain circumstances, when hypotheses are drawn in this manner and averaged according to Bayes' law, this technique has an expected error that is bounded to be at most twice the expected error of the Bayes optimal classifier.[15] Despite the theoretical correctness of this technique, early work showed experimental results suggesting that the method promoted over-fitting and performed worse compared to simpler ensemble techniques such as bagging;[16] however, these conclusions appear to be based on a misunderstanding of the purpose of Bayesian model averaging vs. model combination.[17] Additionally, there have been considerable advances in theory and practice of BMA. Recent rigorous proofs demonstrate the accuracy of BMA in variable selection and estimation in high-dimensional settings,[18] and provide empirical evidence highlighting the role of sparsity-enforcing priors within the BMA in alleviating overfitting.[19]
. It has been shown that under certain circumstances, when hypotheses are drawn in this manner and averaged according to Bayes' law, this technique has an expected error that is bounded to be at most twice the expected error of the Bayes optimal classifier.[15] Despite the theoretical correctness of this technique, early work showed experimental results suggesting that the method promoted over-fitting and performed worse compared to simpler ensemble techniques such as bagging;[16] however, these conclusions appear to be based on a misunderstanding of the purpose of Bayesian model averaging vs. model combination.[17] Additionally, there have been considerable advances in theory and practice of BMA. Recent rigorous proofs demonstrate the accuracy of BMA in variable selection and estimation in high-dimensional settings,[18] and provide empirical evidence highlighting the role of sparsity-enforcing priors within the BMA in alleviating overfitting.[19]
Bayesian model combination
Bayesian model combination (BMC) is an algorithmic correction to Bayesian model averaging (BMA). Instead of sampling each model in the ensemble individually, it samples from the space of possible ensembles (with model weightings drawn randomly from a Dirichlet distribution having uniform parameters). This modification overcomes the tendency of BMA to converge toward giving all of the weight to a single model. Although BMC is somewhat more computationally expensive than BMA, it tends to yield dramatically better results. The results from BMC have been shown to be better on average (with statistical significance) than BMA, and bagging.[20]
The use of Bayes' law to compute model weights necessitates computing the probability of the data given each model. Typically, none of the models in the ensemble are exactly the distribution from which the training data were generated, so all of them correctly receive a value close to zero for this term. This would work well if the ensemble were big enough to sample the entire model-space, but such is rarely possible. Consequently, each pattern in the training data will cause the ensemble weight to shift toward the model in the ensemble that is closest to the distribution of the training data. It essentially reduces to an unnecessarily complex method for doing model selection.
The possible weightings for an ensemble can be visualized as lying on a simplex. At each vertex of the simplex, all of the weight is given to a single model in the ensemble. BMA converges toward the vertex that is closest to the distribution of the training data. By contrast, BMC converges toward the point where this distribution projects onto the simplex. In other words, instead of selecting the one model that is closest to the generating distribution, it seeks the combination of models that is closest to the generating distribution.
The results from BMA can often be approximated by using cross-validation to select the best model from a bucket of models. Likewise, the results from BMC may be approximated by using cross-validation to select the best ensemble combination from a random sampling of possible weightings.
Bucket of models
A "bucket of models" is an ensemble technique in which a model selection algorithm is used to choose the best model for each problem. When tested with only one problem, a bucket of models can produce no better results than the best model in the set, but when evaluated across many problems, it will typically produce much better results, on average, than any model in the set.
The most common approach used for model-selection is cross-validation selection (sometimes called a "bake-off contest"). It is described with the following pseudo-code:
For each model m in the bucket: Do c times: (where 'c' is some constant) Randomly divide the training dataset into two datasets: A, and B. Train m with A Test m with B Select the model that obtains the highest average score
Cross-Validation Selection can be summed up as: "try them all with the training set, and pick the one that works best".[21]
Gating is a generalization of Cross-Validation Selection. It involves training another learning model to decide which of the models in the bucket is best-suited to solve the problem. Often, a perceptron is used for the gating model. It can be used to pick the "best" model, or it can be used to give a linear weight to the predictions from each model in the bucket.
When a bucket of models is used with a large set of problems, it may be desirable to avoid training some of the models that take a long time to train. Landmark learning is a meta-learning approach that seeks to solve this problem. It involves training only the fast (but imprecise) algorithms in the bucket, and then using the performance of these algorithms to help determine which slow (but accurate) algorithm is most likely to do best.[22]
Stacking
Stacking (sometimes called stacked generalization) involves training a learning algorithm to combine the predictions of several other learning algorithms. First, all of the other algorithms are trained using the available data, then a combiner algorithm is trained to make a final prediction using all the predictions of the other algorithms as additional inputs. If an arbitrary combiner algorithm is used, then stacking can theoretically represent any of the ensemble techniques described in this article, although, in practice, a logistic regression model is often used as the combiner.
Stacking typically yields performance better than any single one of the trained models.[23]
It has been successfully used on both supervised learning tasks
(regression,[24] classification and distance learning [25])
and unsupervised learning (density estimation).[26] It has also been used to
estimate bagging's error rate.[3][27] It has been reported to out-perform Bayesian model-averaging.[28]
The two top-performers in the Netflix competition utilized blending, which may be considered to be a form of stacking.[29]
Implementations in statistics packages
- R: at least three packages offer Bayesian model averaging tools,[30] including the BMS (an acronym for Bayesian Model Selection) package,[31] the BAS (an acronym for Bayesian Adaptive Sampling) package,[32] and the BMA package.[33] The [https://www.h2o.ai/download/ H2O-package] offers a lot of machine learning models including an ensembling model, which can also be trained using Spark.
- Python: Scikit-learn, a package for machine learning in Python offers packages for ensemble learning including packages for bagging and averaging methods.
- MATLAB: classification ensembles are implemented in Statistics and Machine Learning Toolbox.[34]
Ensemble learning applications
In the recent years, due to the growing computational power which allows training large ensemble learning in a reasonable time frame, the number of its applications has grown increasingly.[35] Some of the applications of ensemble classifiers include:
Remote sensing
{{main|Remote sensing}}Land cover mapping
Land cover mapping is one of the major applications of Earth observation satellite sensors, using remote sensing and geospatial data, to identify the materials and objects which are located on the surface of target areas. Generally, the classes of target materials include roads, buildings, rivers, lakes, and vegetation.[36] Some different ensemble learning approaches based on artificial neural networks,[37] kernel principal component analysis (KPCA),[38] decision trees with boosting,[39] random forest[36] and automatic design of multiple classifier systems,[40] are proposed to efficiently identify land cover objects.
Change detection
Change detection is an image analysis problem, consisting of the identification of places where the land cover has changed over time. Change detection is widely used in fields such as urban growth, forest and vegetation dynamics, land use and disaster monitoring.[41]The earliest applications of ensemble classifiers in change detection are designed with the majority voting, Bayesian average and the maximum posterior probability.[42]
Computer security
Distributed denial of service
Distributed denial of service is one of the most threatening cyber-attacks that may happen to an internet service provider.[35] By combining the output of single classifiers, ensemble classifiers reduce the total error of detecting and discriminating such attacks from legitimate flash crowds.[43]Malware Detection
Classification of malware codes such as computer viruses, computer worms, trojans, ransomware and spywares with the usage of machine learning techniques, is inspired by the document categorization problem.[44] Ensemble learning systems have shown a proper efficacy in this area.[45][46]
Intrusion detection
An intrusion detection system monitors computer network or computer systems to identify intruder codes like an anomaly detection process. Ensemble learning successfully aids such monitoring systems to reduce their total error.[47][48]
Face recognition
{{main|Face recognition}}Face recognition, which recently has become one of the most popular research areas of pattern recognition, copes with identification or verification of a person by his/her digital images.[49]Hierarchical ensembles based on Gabor Fisher classifier and independent component analysis preprocessing techniques are some of the earliest ensembles employed in this field.[50][51][52]
Emotion recognition
{{main|Emotion recognition}}While speech recognition is mainly based on deep learning because most of the industry players in this field like Google, Microsoft and IBM reveal that the core technology of their speech recognition is based on this approach, speech-based emotion recognition can also have a satisfactory performance with ensemble learning.[53][54]
It is also being successfully used in facial emotion recognition.[55][56][57]
Fraud detection
{{main|Fraud detection}}Fraud detection deals with the identification of bank fraud, such as money laundering, credit card fraud and telecommunication fraud, which have vast domains of research and applications of machine learning. Because ensemble learning improves the robustness of the normal behavior modelling, it has been proposed as an efficient technique to detect such fraudulent cases and activities in banking and credit card systems.[58][59]Financial decision-making
The accuracy of prediction of business failure is a very crucial issue in financial decision-making. Therefore, different ensemble classifiers are proposed to predict financial crises and financial distress.[60] Also, in the trade-based manipulation problem, where traders attempt to manipulate stock prices by buying and selling activities, ensemble classifiers are required to analyze the changes in the stock market data and detect suspicious symptom of stock price manipulation.[61]
Medicine
Ensemble classifiers have been successfully applied in neuroscience, proteomics and medical diagnosis like in neuro-cognitive disorder (i.e. Alzheimer or myotonic dystrophy) detection based on MRI datasets.[62][63][64]
See also
- Ensemble averaging (machine learning)
- Bayesian structural time series (BSTS)
References
2. ^{{cite journal |last1=Polikar |first1=R. |title=Ensemble based systems in decision making |journal=IEEE Circuits and Systems Magazine |volume=6 |issue=3 |pages=21–45 |year=2006 |doi=10.1109/MCAS.2006.1688199}}
3. ^1 {{cite journal |last1=Rokach |first1=L. |title=Ensemble-based classifiers |journal=Artificial Intelligence Review |volume=33 |issue=1–2 |pages=1–39 |year=2010 |doi=10.1007/s10462-009-9124-7}}
4. ^Kuncheva, L. and Whitaker, C., Measures of diversity in classifier ensembles, Machine Learning, 51, pp. 181-207, 2003
5. ^Sollich, P. and Krogh, A., Learning with ensembles: How overfitting can be useful, Advances in Neural Information Processing Systems, volume 8, pp. 190-196, 1996.
6. ^Brown, G. and Wyatt, J. and Harris, R. and Yao, X., Diversity creation methods: a survey and categorisation., Information Fusion, 6(1), pp.5-20, 2005.
7. ^Accuracy and Diversity in Ensembles of Text Categorisers. J. J. García Adeva, Ulises Cerviño, and R. Calvo, CLEI Journal, Vol. 8, No. 2, pp. 1 - 12, December 2005.
8. ^Ho, T., Random Decision Forests, Proceedings of the Third International Conference on Document Analysis and Recognition, pp. 278-282, 1995.
9. ^Gashler, M. and Giraud-Carrier, C. and Martinez, T., Decision Tree Ensemble: Small Heterogeneous Is Better Than Large Homogeneous, The Seventh International Conference on Machine Learning and Applications, 2008, pp. 900-905., DOI 10.1109/ICMLA.2008.154
10. ^{{cite conference |url=http://dl.acm.org/citation.cfm?id=2983907 |title=A Theoretical Framework on the Ideal Number of Classifiers for Online Ensembles in Data Streams |last1=R. Bonab |first1=Hamed |last2=Can |first2=Fazli |date=2016 |publisher=ACM |pages=2053 |location=USA |conference=CIKM}}
11. ^{{cite conference |title=Less Is More: A Comprehensive Framework for the Number of Components of Ensemble Classifiers |last1=R. Bonab |first1=Hamed |last2=Can |first2=Fazli |date=2017 |publisher=IEEE |location=USA |conference=TNNLS|arxiv = 1709.02925}}
12. ^Tom M. Mitchell, Machine Learning, 1997, pp. 175
13. ^Breiman, L., Bagging Predictors, Machine Learning, 24(2), pp.123-140, 1996.
14. ^{{Cite journal | last1 = Hoeting | first1 = J. A.|author1-link= Jennifer A. Hoeting | last2 = Madigan | first2 = D. | last3 = Raftery | first3 = A. E. | last4 = Volinsky | first4 = C. T. | title = Bayesian Model Averaging: A Tutorial | jstor = 2676803 | journal = Statistical Science | volume = 14 | issue = 4 | pages = 382–401 | year = 1999 | pmid = | pmc = }}
15. ^David Haussler, Michael Kearns, and Robert E. Schapire. Bounds on the sample complexity of Bayesian learning using information theory and the VC dimension. Machine Learning, 14:83–113, 1994
16. ^{{cite conference |first=Pedro |last=Domingos |title=Bayesian averaging of classifiers and the overfitting problem |conference=Proceedings of the 17th International Conference on Machine Learning (ICML) |pages=223––230 |year=2000 |url=http://www.cs.washington.edu/homes/pedrod/papers/mlc00b.pdf}}
17. ^{{citation |first=Thomas |last=Minka |title=Bayesian model averaging is not model combination |year=2002 |url=http://research.microsoft.com/en-us/um/people/minka/papers/minka-bma-isnt-mc.pdf}}
18. ^{{cite journal |last=Castillo |first=I. |last2=Schmidt-Hieber |first2=J. |last3=van der Vaart |first3=A. |title=Bayesian linear regression with sparse priors |journal=Annals of Statistics |volume=43 |issue=5 |pages=1986–2018 |year=2015 |doi=10.1214/15-AOS1334 |arxiv=1403.0735 }}
19. ^{{cite journal |last=Hernández-Lobato |first=D. |last2=Hernández-Lobato |first2=J. M. |last3=Dupont |first3=P. |title=Generalized Spike-and-Slab Priors for Bayesian Group Feature Selection Using Expectation Propagation |journal=Journal of Machine Learning Research |volume=14 |issue= |pages=1891–1945 |year=2013 |doi= |url=http://www.jmlr.org/papers/volume14/hernandez-lobato13a/hernandez-lobato13a.pdf }}
20. ^{{cite conference|author=Monteith, Kristine|author2=Carroll, James |author3=Seppi, Kevin |author4= Martinez, Tony. |url=http://axon.cs.byu.edu/papers/Kristine.ijcnn2011.pdf|title=Turning Bayesian Model Averaging into Bayesian Model Combination|conference=Proceedings of the International Joint Conference on Neural Networks IJCNN'11|year=2011|pages=2657–2663}}
21. ^Saso Dzeroski, Bernard Zenko, Is Combining Classifiers Better than Selecting the Best One, Machine Learning, 2004, pp. 255--273
22. ^Bensusan, Hilan and Giraud-Carrier, Christophe G., Discovering Task Neighbourhoods Through Landmark Learning Performances, PKDD '00: Proceedings of the 4th European Conference on Principles of Data Mining and Knowledge Discovery, Springer-Verlag, 2000, pages 325--330
23. ^Wolpert, D., Stacked Generalization., Neural Networks, 5(2), pp. 241-259., 1992
24. ^Breiman, L., Stacked Regression, Machine Learning, 24, 1996 {{doi|10.1007/BF00117832}}
25. ^{{cite journal |first=M. |last=Ozay |first2=F. T. |last2=Yarman Vural |title=A New Fuzzy Stacked Generalization Technique and Analysis of its Performance |year=2013 |arxiv=1204.0171 |bibcode=2012arXiv1204.0171O }}
26. ^Smyth, P. and Wolpert, D. H., Linearly Combining Density Estimators via Stacking, MachineLearning Journal, 36, 59-83, 1999
27. ^Wolpert, D.H., and Macready, W.G., An Efficient Method to Estimate Bagging’s Generalization Error, Machine Learning Journal, 35, 41-55, 1999
28. ^Clarke, B., Bayes model averaging and stacking when model approximation error cannot be ignored, Journal of Machine Learning Research, pp 683-712, 2003
29. ^{{cite journal |last=Sill |first=J. |last2=Takacs |first2=G. |last3=Mackey |first3=L. |last4=Lin |first4=D. |title=Feature-Weighted Linear Stacking |year=2009 |arxiv=0911.0460 |bibcode=2009arXiv0911.0460S }}
30. ^{{cite journal |first=Shahram M. |last=Amini |first2=Christopher F. |last2=Parmeter |title=Bayesian model averaging in R |journal=Journal of Economic and Social Measurement |volume=36 |issue=4 |pages=253–287 |year=2011 |doi= 10.3233/JEM-2011-0350|url=https://core.ac.uk/download/pdf/6494889.pdf }}
31. ^{{cite web |title=BMS: Bayesian Model Averaging Library |work=The Comprehensive R Archive Network |url=https://cran.r-project.org/web/packages/BMS/index.html |accessdate=September 9, 2016 |date=2015-11-24 }}
32. ^{{cite web |title=BAS: Bayesian Model Averaging using Bayesian Adaptive Sampling |work=The Comprehensive R Archive Network |url=https://cran.r-project.org/web/packages/BAS/index.html |accessdate=September 9, 2016 }}
33. ^{{cite web |title=BMA: Bayesian Model Averaging |work=The Comprehensive R Archive Network |url=https://cran.r-project.org/web/packages/BMA/index.html |accessdate=September 9, 2016 }}
34. ^{{cite web |title=Classification Ensembles |url=https://uk.mathworks.com/help/stats/classification-ensembles.html |work=MATLAB & Simulink |accessdate=June 8, 2017 }}
35. ^1 {{cite journal |last1=Woźniak |first1=Michał |last2=Graña |first2=Manuel |last3=Corchado |first3=Emilio |title=A survey of multiple classifier systems as hybrid systems |journal=Information Fusion |date=March 2014 |volume=16 |pages=3–17 |doi=10.1016/j.inffus.2013.04.006}}
36. ^1 {{cite journal |last1=Rodriguez-Galiano |first1=V.F. |last2=Ghimire |first2=B. |last3=Rogan |first3=J. |last4=Chica-Olmo |first4=M. |last5=Rigol-Sanchez |first5=J.P. |title=An assessment of the effectiveness of a random forest classifier for land-cover classification |journal=ISPRS Journal of Photogrammetry and Remote Sensing |date=January 2012 |volume=67 |pages=93–104 |doi=10.1016/j.isprsjprs.2011.11.002|bibcode=2012JPRS...67...93R }}
37. ^{{cite journal |last1=Giacinto |first1=Giorgio |last2=Roli |first2=Fabio |title=Design of effective neural network ensembles for image classification purposes |journal=Image and Vision Computing |date=August 2001 |volume=19 |issue=9–10 |pages=699–707 |doi=10.1016/S0262-8856(01)00045-2|citeseerx=10.1.1.11.5820 }}
38. ^{{cite book |last1=Xia |first1=Junshi |last2=Yokoya |first2=Naoto |last3=Iwasaki |first3=Yakira |title=A novel ensemble classifier of hyperspectral and LiDAR data using morphological features |journal=2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) |date=March 2017 |pages=6185–6189 |doi=10.1109/ICASSP.2017.7953345|isbn=978-1-5090-4117-6 }}
39. ^{{cite journal |last1=Mochizuki |first1=S. |last2=Murakami |first2=T. |title=Accuracy comparison of land cover mapping using the object-oriented image classification with machine learning algorithms |journal=33rd Asian Conference on Remote Sensing 2012, ACRS 2012 |date=November 2012 |volume=1 |pages=126–133}}
40. ^{{cite book |last1=Giacinto |first1=G. |last2=Roli |first2=F. |last3=Fumera |first3=G. |title=Design of effective multiple classifier systems by clustering of classifiers |journal=Proceedings 15th International Conference on Pattern Recognition. ICPR-2000 |volume=2 |date=September 2000 |pages=160–163 |doi=10.1109/ICPR.2000.906039|isbn=978-0-7695-0750-7 |citeseerx=10.1.1.11.5328 }}
41. ^{{cite journal |last1=Du |first1=Peijun |last2=Liu |first2=Sicong |last3=Xia |first3=Junshi |last4=Zhao |first4=Yindi |title=Information fusion techniques for change detection from multi-temporal remote sensing images |journal=Information Fusion |date=January 2013 |volume=14 |issue=1 |pages=19–27 |doi=10.1016/j.inffus.2012.05.003}}
42. ^{{cite journal |last1=Bruzzone |first1=Lorenzo |last2=Cossu |first2=Roberto |last3=Vernazza |first3=Gianni |title=Combining parametric and non-parametric algorithms for a partially unsupervised classification of multitemporal remote-sensing images |journal=Information Fusion |date=December 2002 |volume=3 |issue=4 |pages=289–297 |doi=10.1016/S1566-2535(02)00091-X}}
43. ^{{cite journal |last1=Raj Kumar |first1=P. Arun |last2=Selvakumar |first2=S. |title=Distributed denial of service attack detection using an ensemble of neural classifier |journal=Computer Communications |date=July 2011 |volume=34 |issue=11 |pages=1328–1341 |doi=10.1016/j.comcom.2011.01.012}}
44. ^{{cite journal |last1=Shabtai |first1=Asaf |last2=Moskovitch |first2=Robert |last3=Elovici |first3=Yuval |last4=Glezer |first4=Chanan |title=Detection of malicious code by applying machine learning classifiers on static features: A state-of-the-art survey |journal=Information Security Technical Report |date=February 2009 |volume=14 |issue=1 |pages=16–29 |doi=10.1016/j.istr.2009.03.003}}
45. ^{{cite book |first1=Boyun| last1=Zhang|first2=Jianping |last2=Yin |first3=Jingbo |last3=Hao |first4=Dingxing |last4=Zhang |first5=Shulin |last5=Wang |title=Malicious Codes Detection Based on Ensemble Learning |journal=Autonomic and Trusted Computing | volume=4610|date=2007 |pages=468–477 |doi=10.1007/978-3-540-73547-2_48| series=Lecture Notes in Computer Science| isbn=978-3-540-73546-5}}
46. ^{{cite journal |last1=Menahem |first1=Eitan |last2=Shabtai |first2=Asaf |last3=Rokach |first3=Lior |last4=Elovici |first4=Yuval |title=Improving malware detection by applying multi-inducer ensemble |journal=Computational Statistics & Data Analysis |date=February 2009 |volume=53 |issue=4 |pages=1483–1494 |doi=10.1016/j.csda.2008.10.015|citeseerx=10.1.1.150.2722 }}
47. ^{{cite book |last1=Locasto |first1=Michael E. |last2=Wang |first2=Ke |last3=Keromytis |first3=Angeles D. |last4=Salvatore |first4=J. Stolfo |title=FLIPS: Hybrid Adaptive Intrusion Prevention |journal=Recent Advances in Intrusion Detection |volume=3858 |date=2005 |pages=82–101 |doi=10.1007/11663812_5|series=Lecture Notes in Computer Science |isbn=978-3-540-31778-4 |citeseerx=10.1.1.60.3798 }}
48. ^{{cite journal |last1=Giacinto |first1=Giorgio |last2=Perdisci |first2=Roberto |last3=Del Rio |first3=Mauro |last4=Roli |first4=Fabio |title=Intrusion detection in computer networks by a modular ensemble of one-class classifiers |journal=Information Fusion |date=January 2008 |volume=9 |issue=1 |pages=69–82 |doi=10.1016/j.inffus.2006.10.002|citeseerx=10.1.1.69.9132 }}
49. ^{{cite book |last1=Mu |first1=Xiaoyan |last2=Lu |first2=Jiangfeng |last3=Watta |first3=Paul |last4=Hassoun |first4=Mohamad H. |title=Weighted voting-based ensemble classifiers with application to human face recognition and voice recognition |journal=2009 International Joint Conference on Neural Networks |pages=2168–2171 |date=July 2009 |doi=10.1109/IJCNN.2009.5178708|isbn=978-1-4244-3548-7 }}
50. ^{{cite book |last1=Yu |first1=Su |last2=Shan |first2=Shiguang |last3=Chen |first3=Xilin |last4=Gao |first4=Wen |title=Hierarchical ensemble of Gabor Fisher classifier for face recognition |journal=Automatic Face and Gesture Recognition, 2006. FGR 2006. 7th International Conference on Automatic Face and Gesture Recognition (FGR06) |pages=91–96 |date=April 2006 |doi=10.1109/FGR.2006.64|isbn=978-0-7695-2503-7 }}
51. ^{{cite book |last1=Su |first1=Y. |last2=Shan |first2=S. |last3=Chen |first3=X. |last4=Gao |first4=W. |title=Patch-based gabor fisher classifier for face recognition |journal=Proceedings - International Conference on Pattern Recognition |date=September 2006 |volume=2 |pages=528–531 |doi=10.1109/ICPR.2006.917|isbn=978-0-7695-2521-1 }}
52. ^{{cite book |last1=Liu |first1=Yang |last2=Lin |first2=Yongzheng |last3=Chen |first3=Yuehui |title=Ensemble Classification Based on ICA for Face Recognition |journal=Proceedings - 1st International Congress on Image and Signal Processing, IEEE Conference, CISP 2008 |date=July 2008 |pages=144–148 |doi=10.1109/CISP.2008.581 |isbn=978-0-7695-3119-9 }}
53. ^{{cite book |last1=Rieger |first1=Steven A. |last2=Muraleedharan |first2=Rajani |last3=Ramachandran |first3=Ravi P. |title=Speech based emotion recognition using spectral feature extraction and an ensemble of kNN classifiers |journal=Proceedings of the 9th International Symposium on Chinese Spoken Language Processing, ISCSLP 2014 |date=2014 |pages=589–593 |doi=10.1109/ISCSLP.2014.6936711|isbn=978-1-4799-4219-0 }}
54. ^{{cite book |last1=Krajewski |first1=Jarek |last2=Batliner |first2=Anton |last3=Kessel |first3=Silke |title=Comparing Multiple Classifiers for Speech-Based Detection of Self-Confidence - A Pilot Study |journal=2010 20th International Conference on Pattern Recognition |date=October 2010 |pages=3716–3719 |doi=10.1109/ICPR.2010.905|isbn=978-1-4244-7542-1 }}
55. ^{{cite journal |last1=Rani |first1=P. Ithaya |last2=Muneeswaran |first2=K. |title=Recognize the facial emotion in video sequences using eye and mouth temporal Gabor features |journal=Multimedia Tools and Applications |date=25 May 2016 |volume=76 |issue=7 |pages=10017–10040 |doi=10.1007/s11042-016-3592-y}}
56. ^{{cite journal |last1=Rani |first1=P. Ithaya |last2=Muneeswaran |first2=K. |title=Facial Emotion Recognition Based on Eye and Mouth Regions |journal=International Journal of Pattern Recognition and Artificial Intelligence |date=August 2016 |volume=30 |issue=7 |pages=1655020 |doi=10.1142/S021800141655020X}}
57. ^{{cite journal |last1=Rani |first1=P. Ithaya |last2=Muneeswaran |first2=K |title=Emotion recognition based on facial components |journal=Sādhanā |date=28 March 2018 |volume=43 |issue=3 |doi=10.1007/s12046-018-0801-6}}
58. ^{{cite journal |last1=Louzada |first1=Francisco |last2=Ara |first2=Anderson |title=Bagging k-dependence probabilistic networks: An alternative powerful fraud detection tool |journal=Expert Systems with Applications |date=October 2012 |volume=39 |issue=14 |pages=11583–11592 |doi=10.1016/j.eswa.2012.04.024}}
59. ^{{cite journal |last1=Sundarkumar |first1=G. Ganesh |last2=Ravi |first2=Vadlamani |title=A novel hybrid undersampling method for mining unbalanced datasets in banking and insurance |journal=Engineering Applications of Artificial Intelligence |date=January 2015 |volume=37 |pages=368–377 |doi=10.1016/j.engappai.2014.09.019}}
60. ^{{cite journal |last1=Kim |first1=Yoonseong |last2=Sohn |first2=So Young |title=Stock fraud detection using peer group analysis |journal=Expert Systems with Applications |date=August 2012 |volume=39 |issue=10 |pages=8986–8992 |doi=10.1016/j.eswa.2012.02.025}}
61. ^{{cite journal |last1=Kim |first1=Yoonseong |last2=Sohn |first2=So Young |title=Stock fraud detection using peer group analysis |journal=Expert Systems with Applications |date=August 2012 |volume=39 |issue=10 |pages=8986–8992 |doi=10.1016/j.eswa.2012.02.025}}
62. ^{{cite journal |last1=Savio |first1=A. |last2=García-Sebastián |first2=M.T. |last3=Chyzyk |first3=D. |last4=Hernandez |first4=C. |last5=Graña |first5=M. |last6=Sistiaga |first6=A. |last7=López de Munain |first7=A. |last8=Villanúa |first8=J. |title=Neurocognitive disorder detection based on feature vectors extracted from VBM analysis of structural MRI |journal=Computers in Biology and Medicine |date=August 2011 |volume=41 |issue=8 |pages=600–610 |doi=10.1016/j.compbiomed.2011.05.010}}
63. ^{{cite book |last1=Ayerdi |first1=B. |last2=Savio |first2=A. |last3=Graña |first3=M. |title=Meta-ensembles of classifiers for Alzheimer's disease detection using independent ROI features |journal=Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) |volume=7931 |date=June 2013 |issue=Part 2 |pages=122–130 |doi=10.1007/978-3-642-38622-0_13|series=Lecture Notes in Computer Science |isbn=978-3-642-38621-3 }}
64. ^{{cite journal |last1=Gu |first1=Quan |last2=Ding |first2=Yong-Sheng |last3=Zhang |first3=Tong-Liang |title=An ensemble classifier based prediction of G-protein-coupled receptor classes in low homology |journal=Neurocomputing |date=April 2015 |volume=154 |pages=110–118 |doi=10.1016/j.neucom.2014.12.013}}
Further reading
- {{cite book |last=Zhou Zhihua |date=2012 |title=Ensemble Methods: Foundations and Algorithms |url= |location= |publisher= Chapman and Hall/CRC |isbn=978-1-439-83003-1 }}
- {{cite book |last1=Robert Schapire |last2=Yoav Freund |date=2012 |title=Boosting: Foundations and Algorithms |url= |location= |publisher=MIT |isbn=978-0-262-01718-3 }}
External links
- {{scholarpedia|title=Ensemble learning|urlname=Ensemble_learning|curator=Robi Polikar}}
- The Waffles (machine learning) toolkit contains implementations of Bagging, Boosting, Bayesian Model Averaging, Bayesian Model Combination, Bucket-of-models, and other ensemble techniques
- The Perfect Luv Tape
- The Perfect LUV Tape
- The Perfect Man (1939 film)
- The Perfect Match
- The Perfect Match (1988 film)
- The Perfect Match (2016 film)
- The Perfect Match (TV series)
- The Perfect Mother
- The Perfect Murder (2019 film)
- The Perfect Murder (TV series)
- The Perfect Nanny (novel)
- The Perfect Ones
- The Perfect Pear
- The Perfect Red Velvet
- The Perfect Sap
- The Perfect Snob
- The Perfect Thirty-Six
- The Perfect Tuck
- The Perfect Wave
- The Perfect Weapon
- The Perfect Weapon (2016 film)
- The Perfect Weapon (film)
- The Perfect Weapon (short story)
- The Perfect Wife (TV series)
- The Perfect World Foundation