- Setup Target neighbors Impostors
- Algorithm
- Extensions and efficient solvers
- See also
- References
- External links
Large margin nearest neighbor (LMNN)[1] classification is a statistical machine learning algorithm for metric learning. It learns a pseudometric designed for k-nearest neighbor classification. The algorithm is based on semidefinite programming, a sub-class of convex optimization.
The goal of supervised learning (more specifically classification) is to learn a decision rule that can categorize data instances into pre-defined classes. The k-nearest neighbor rule assumes a training data set of labeled instances (i.e. the classes are known). It classifies a new data instance with the class obtained from the majority vote of the k closest (labeled) training instances. Closeness is measured with a pre-defined metric. Large margin nearest neighbors is an algorithm that learns this global (pseudo-)metric in a supervised fashion to improve the classification accuracy of the k-nearest neighbor rule.
Setup
The main intuition behind LMNN is to learn a pseudometric under which all data instances in the training set are surrounded by at least k instances that share the same class label. If this is achieved, the leave-one-out error (a special case of cross validation) is minimized. Let the training data consist of a data set 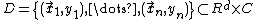 , where the set of possible class categories is
, where the set of possible class categories is  .
.
The algorithm learns a pseudometric of the type
.
For  to be well defined, the matrix
to be well defined, the matrix  needs to be positive semi-definite. The Euclidean metric is a special case, where is the identity matrix. This generalization is often (falsely) referred to as Mahalanobis metric.
needs to be positive semi-definite. The Euclidean metric is a special case, where is the identity matrix. This generalization is often (falsely) referred to as Mahalanobis metric.
Figure 1 illustrates the effect of the metric under varying . The two circles show the set of points with equal distance to the center  . In the Euclidean case this set is a circle, whereas under the modified (Mahalanobis) metric it becomes an ellipsoid.
. In the Euclidean case this set is a circle, whereas under the modified (Mahalanobis) metric it becomes an ellipsoid.
The algorithm distinguishes between two types of special data points: target neighbors and impostors.
Target neighbors
Target neighbors are selected before learning. Each instance has exactly  different target neighbors within
different target neighbors within  , which all share the same class label
, which all share the same class label  . The target neighbors are the data points that should become nearest neighbors under the learned metric. Let us denote the set of target neighbors for a data point as
. The target neighbors are the data points that should become nearest neighbors under the learned metric. Let us denote the set of target neighbors for a data point as 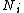 .
.
Impostors
An impostor of a data point is another data point  with a different class label (i.e.
with a different class label (i.e.  ) which is one of the nearest neighbors of . During learning the algorithm tries to minimize the number of impostors for all data instances in the training set.
) which is one of the nearest neighbors of . During learning the algorithm tries to minimize the number of impostors for all data instances in the training set.
Algorithm
Large margin nearest neighbors optimizes the matrix with the help of semidefinite programming. The objective is twofold: For every data point , the target neighbors should be close and the impostors should be far away. Figure 1 shows the effect of such an optimization on an illustrative example. The learned metric causes the input vector to be surrounded by training instances of the same class. If it was a test point, it would be classified correctly under the 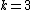 nearest neighbor rule.
nearest neighbor rule.
The first optimization goal is achieved by minimizing the average distance between instances and their target neighbors
.
The second goal is achieved by penalizing distances to impostors  that are less than one unit further away than target neighbors (and therefore pushing them out of the local neighborhood of ). The resulting value to be minimized can be stated as:
that are less than one unit further away than target neighbors (and therefore pushing them out of the local neighborhood of ). The resulting value to be minimized can be stated as:

With a hinge loss function  , which ensures that impostor proximity is not penalized when outside the margin. The margin of exactly one unit fixes the scale of the matrix
, which ensures that impostor proximity is not penalized when outside the margin. The margin of exactly one unit fixes the scale of the matrix 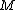 . Any alternative choice
. Any alternative choice  would result in a rescaling of by a factor of
would result in a rescaling of by a factor of  .
.
The final optimization problem becomes:



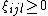
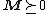
The hyperparameter 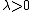 is some positive constant (typically set through cross-validation). Here the variables
is some positive constant (typically set through cross-validation). Here the variables  (together with two types of constraints) replace the term in the cost function. They play a role similar to slack variables to absorb the extent of violations of the impostor constraints. The last constraint ensures that is positive semi-definite. The optimization problem is an instance of semidefinite programming (SDP). Although SDPs tend to suffer from high computational complexity, this particular SDP instance can be solved very efficiently due to the underlying geometric properties of the problem. In particular, most impostor constraints are naturally satisfied and do not need to be enforced during runtime (i.e. the set of variables is sparse). A particularly well suited solver technique is the working set method, which keeps a small set of constraints that are actively enforced and monitors the remaining (likely satisfied) constraints only occasionally to ensure correctness.
(together with two types of constraints) replace the term in the cost function. They play a role similar to slack variables to absorb the extent of violations of the impostor constraints. The last constraint ensures that is positive semi-definite. The optimization problem is an instance of semidefinite programming (SDP). Although SDPs tend to suffer from high computational complexity, this particular SDP instance can be solved very efficiently due to the underlying geometric properties of the problem. In particular, most impostor constraints are naturally satisfied and do not need to be enforced during runtime (i.e. the set of variables is sparse). A particularly well suited solver technique is the working set method, which keeps a small set of constraints that are actively enforced and monitors the remaining (likely satisfied) constraints only occasionally to ensure correctness.
Extensions and efficient solvers
LMNN was extended to multiple local metrics in the 2008 paper.[2]
This extension significantly improves the classification error, but involves a more expensive optimization problem. In their 2009 publication in the Journal of Machine Learning Research,[3] Weinberger and Saul derive an efficient solver for the semi-definite program. It can learn a metric for the MNIST handwritten digit data set in several hours, involving billions of pairwise constraints. An open source Matlab implementation is freely available at the authors web page.
Kumal et al.[4] extended the algorithm to incorporate local invariances to multivariate polynomial transformations and improved regularization.
See also
{{div col}}- Similarity learning
- Linear discriminant analysis
- Learning vector quantization
- Pseudometric space
- Nearest neighbor search
- Cluster analysis
- Data classification
- Data mining
- Machine learning
- Pattern recognition
- Predictive analytics
- Dimension reduction
- Neighbourhood components analysis
References
2. ^{{cite journal | last = Weinberger | first = K. Q. |author2=Saul L. K. | title = Fast solvers and efficient implementations for distance metric learning | journal = Proceedings of International Conference on Machine Learning | year=2008 | pages = 1160–1167 | url=http://research.yahoo.net/files/icml2008a.pdf}}
3. ^{{cite journal | last = Weinberger | first = K. Q. |author2=Saul L. K. | title = Distance Metric Learning for Large Margin Classification | journal = Journal of Machine Learning Research | year=2009 | volume = 10 | pages = 207–244 | url=http://www.jmlr.org/papers/volume10/weinberger09a/weinberger09a.pdf}}
4. ^{{cite journal | last = Kumar | first= M.P. |author2=Torr P.H.S. |author3=Zisserman A. | title =An invariant large margin nearest neighbour classifier | journal= IEEE 11th International Conference on Computer Vision (ICCV), 2007 | year=2007 | pages= 1–8 | url=http://ieeexplore.ieee.org/xpl/freeabs_all.jsp?arnumber=4409041}}
External links
- Matlab Implementation
- [https://compscicenter.ru/media/slides/machine_learning_1_2012_spring/2012_05_03_machine_learning_1_2012_spring.pdf ICML 2010 Tutorial on Metric Learning]
- Negro Mountain Tunnel
- Negromuelle
- Negro National Hymn
- Negro National League (1920-1931)
- Negro National League (1933-1948)
- Negro National League (disambiguation)
- Negrondes
- Negro Necro Nekros
- Negroni (surname)
- Negro of banyoles
- Negro Pepper
- Negrophilia
- Negrophilia (album)
- Negrophilia (Lenny Kravitz album)
- Negro Piñera
- Negro Plot of 1741
- Negroponte (disambiguation)
- Negro Project
- Negro Project conspiracy theory
- Negro Repertory Company
- Negro Republican Party
- Negro river
- Negro River, Chaco
- Negro River (Guatemala)
- Negro River (Jamaica)