- History
- Overview
- Relation to other parsers LR parsers LL parsers
- See also
- Notes
- References
- External links
In computer science, an LALR parser{{efn|"LALR" is pronounced as the initialism "el-ay-el-arr"}} or Look-Ahead LR parser is a simplified version of a canonical LR parser, to parse (separate and analyze) a text according to a set of production rules specified by a formal grammar for a computer language. ("LR" means left-to-right, rightmost derivation.)
The LALR parser was invented by Frank DeRemer in his 1969 PhD dissertation, Practical Translators for LR(k) languages,{{sfn|DeRemer|1969}} in his treatment of the practical difficulties at that time of implementing LR(1) parsers. He showed that the LALR parser has more language recognition power than the LR(0) parser, while requiring the same number of states as the LR(0) parser for a language that can be recognized by both parsers. This makes the LALR parser a memory-efficient alternative to the LR(1) parser for languages that are LALR. It was also proven that there exist LR(1) languages that are not LALR. Despite this weakness, the power of the LALR parser is sufficient for many mainstream computer languages,[1] including Java,[2] though the reference grammars for many languages fail to be LALR due to being ambiguous.[1]
The original dissertation gave no algorithm for constructing such a parser given a formal grammar. The first algorithms for LALR parser generation were published in 1973.[3] In 1982, DeRemer and Tom Pennello published an algorithm that generated highly memory-efficient LALR parsers.[4] LALR parsers can be automatically generated from a grammar by an LALR parser generator such as Yacc or GNU Bison. The automatically generated code may be augmented by hand-written code to augment the power of the resulting parser.
History
In 1965, Donald Knuth invented the LR parser (Left to Right, Rightmost derivation). The LR parser can recognize any deterministic context-free language in linear-bounded time.[5] Rightmost derivation has very large memory requirements and implementing an LR parser was impractical due to the limited memory of computers at that time. To address this shortcoming, in 1969, Frank DeRemer proposed two simplified versions of the LR parser, namely the Look-Ahead LR (LALR){{sfn|DeRemer|1969}} and the Simple LR parser that had much lower memory requirements at the cost of less language-recognition power, with the LALR parser being the most-powerful alternative.{{sfn|DeRemer|1969}} In 1977, memory optimizations for the LR parser were invented[6] but still the LR parser was less memory-efficient than the simplified alternatives.
In 1979, Frank DeRemer and Tom Pennello announced a series of optimizations for the LALR parser that would further improve its memory efficiency.[7] Their work was published in 1982.[4]
Overview
Generally, the LALR parser refers to the LALR(1) parser,{{efn|"LALR(1)" is pronounced as the initialism "el-ay-el-arr-one"}} just as the LR parser generally refers to the LR(1) parser. The "(1)" denotes one-token lookahead, to resolve differences between rule patterns during parsing. Similarly, there is an LALR(2) parser with two-token lookahead, and LALR(k) parsers with k-token lookup, but these are rare in actual use. The LALR parser is based on the LR(0) parser, so it can also be denoted LALR(1) = LA(1)LR(0) (1 token of lookahead, LR(0)) or more generally LALR(k) = LA(k)LR(0) (k tokens of lookahead, LR(0)). There is in fact a two-parameter family of LA(k)LR(j) parsers for all combinations of j and k, which can be derived from the LR(j + k) parser,[8] but these do not see practical use.
As with other types of LR parsers, an LALR parser is quite efficient at finding the single correct bottom-up parse in a single left-to-right scan over the input stream, because it does not need to use backtracking. Being a lookahead parser by definition, it always uses a lookahead, with {{nowrap|LALR(1)}} being the most-common case.
Relation to other parsers
LR parsers
The LALR(1) parser is less powerful than the LR(1) parser, and more powerful than the SLR(1) parser, though they all use the same production rules. The simplification that the LALR parser introduces consists in merging rules that have identical kernel item sets, because during the LR(0) state-construction process the lookaheads are not known. This reduces the power of the parser because not knowing the lookahead symbols can confuse the parser as to which grammar rule to pick next, resulting in reduce/reduce conflicts. All conflicts that arise in applying a LALR(1) parser to an unambiguous LR(1) grammar are reduce/reduce conflicts. The SLR(1) parser performs further merging, which introduces additional conflicts.
The standard example of an LR(1) grammar that cannot be parsed with the LALR(1) parser, exhibiting such a reduce/reduce conflict, is:[9][10]
S → a E c → a F d → b F c → b E d E → e F → e
In the LALR table construction, two states will be merged into one state and later the lookaheads will be found to be ambiguous. The one state with lookaheads is:
E → e. {c,d} F → e. {c,d}An LR(1) parser will create two different states (with non-conflicting lookaheads), neither of which is ambiguous. In an LALR parser this one state has conflicting actions (given lookahead c or d, reduce to E or F), a "reduce/reduce conflict"; the above grammar will be declared ambiguous by a LALR parser generator and conflicts will be reported.
To recover, this ambiguity is resolved by choosing E, because it occurs before F in the grammar. However, the resultant parser will not be able to recognize the valid input sequence b e c, since the ambiguous sequence e c is reduced to (E → e) c, rather than the correct (F → e) c, but b E c is not in the grammar.
LL parsers
The LALR(j) parsers are incomparable with LL(k) parsers: for any j and k both greater than 0, there are LALR(j) grammars that are not LL(k) grammars and conversely. In fact, it is undecidable whether a given LL(1) grammar is LALR(k) for any 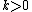 .[1]
.[1]
Depending on the presence of empty derivations, a LL(1) grammar can be equal to a SLR(1) or a LALR(1) grammar. If the LL(1) grammar has no empty derivations it is SLR(1) and if all symbols with empty derivations have non-empty derivations it is LALR(1). If symbols having only an empty derivation exist, the grammar may or may not be LALR(1).[11]
See also
- Comparison of parser generators
- Context-free grammar
- Lookahead
- Parser generator
- Token scanner
Notes
{{notelist}}References
2. ^{{cite web|title=Generate the Parser|url=http://www.eclipse.org/jdt/core/howto/generate%20parser/generateParser.html|publisher=Eclipse JDT Project|accessdate=29 June 2012}}
3. ^{{cite journal| first1=T.| last1=Anderson| first2=J.| last2=Eve| first3=J.| last3=Horning| title=Efficient LR(1) parsers| journal=Acta Informatica| issue=2| year=1973| pages= 2–39}}
4. ^1 {{cite journal |first1=Frank |last1=DeRemer |first2=Thomas |last2=Pennello |date=October 1982 |title=Efficient Computation of LALR(1) Look-Ahead Sets |url=http://3e8.org/pub/scheme/doc/parsing/Efficient%20Computation%20of%20LALR%281%29%20Look-Ahead%20Sets.pdf |journal=ACM Transactions on Programming Languages and Systems |volume=4 |issue=4 |pages=615–649 |accessdate=25 July 2014 |doi=10.1145/69622.357187}}
5. ^{{Cite journal | last1 = Knuth | first1 = D. E. | authorlink = Donald Knuth | title = On the translation of languages from left to right | doi = 10.1016/S0019-9958(65)90426-2 | journal = Information and Control | volume = 8 | issue = 6 | pages = 607–639 | date=July 1965 | url = http://www.cs.dartmouth.edu/~mckeeman/cs48/mxcom/doc/knuth65.pdf | accessdate=29 May 2011 | ref = harv }}
6. ^{{citation|title=A Practical General Method for Constructing LR(k) Parsers|author=Pager, D.|work=Acta Informatica 7|pages=249–268|year=1977}}
7. ^{{citation|title=Efficient Computation of LALR(1) Look-Ahead Sets|author=Frank DeRemer, Thomas Pennello|work=Sigplan Notices - SIGPLAN, vol. 14, no. 8|pages=176–187|year=1979}}
8. ^Parsing Techniques: A Practical Guide, by Dick Grune and Ceriel J. H. Jacobs, "9.7 LALR(1)", [https://books.google.com/books?id=05xA_d5dSwAC&pg=PA302 p. 302]
9. ^"7.9 LR(1) but not LALR(1) {{webarchive|url=https://web.archive.org/web/20100804231352/http://www.cse.ohio-state.edu/~gurari/course/cse756/cse756su56.xht |date=4 August 2010 }}", CSE 756: Compiler Design and Implementation {{webarchive|url=https://web.archive.org/web/20100723153301/http://www.cse.ohio-state.edu/~gurari/course/cse756/cse756.xht |date=23 July 2010 }}, Eitan Gurari, Spring 2008
10. ^"[https://stackoverflow.com/questions/8496065/why-is-this-lr1-grammar-not-lalr1 Why is this LR(1) grammar not LALR(1)?]"
11. ^{{harv|Beatty|1982}}
- {{cite thesis
|type=Ph.D.
|title=Practical Translators for LR(k) languages
|url=http://publications.csail.mit.edu/lcs/pubs/pdf/MIT-LCS-TR-065.pdf
|first=Franklin L. |last=DeRemer
|publisher=MIT
|year=1969
|ref=harv}}
- {{Cite journal | last1 = Beatty | first1 = J. C. | title = On the relationship between LL(1) and LR(1) grammars | url = https://cs.uwaterloo.ca/research/tr/1979/CS-79-36.pdf | doi = 10.1145/322344.322350 | journal = Journal of the ACM | volume = 29 | issue = 4 (Oct) | pages = 1007–1022 | year = 1982 | ref = harv }}
External links
- Parsing Simulator This simulator is used to generate parsing tables LALR and resolve the exercises of the book.
- JS/CC JavaScript based implementation of a LALR(1) parser generator, which can be run in a web-browser or from the command-line.
- LALR(1) tutorial, a flash card-like tutorial on LALR(1) parsing.