- Overview
- Length of Codeword and Query Complexity
- Applications Data Transmission and Storage Complexity Theory Private Information Retrieval Schemes
- Examples The Hadamard code The Reed–Muller code
- See also
- References
A locally decodable code (LDC) is an error-correcting code that allows a single bit of the original message to be decoded with high probability by only examining (or querying) a small number of bits of a possibly corrupted codeword.
[1][2][3]This property could be useful, say, in a context where information is being transmitted over a noisy channel, and only a small subset of the data is required at a particular time and there is no need to decode the entire message at once. Note that locally decodable codes are not a subset of locally testable codes, though there is some overlap between the two.[4]
Codewords are generated from the original message using an algorithm that introduces a certain amount of redundancy into the codeword; thus, the codeword is always longer than the original message. This redundancy is distributed across the codeword and allows the original message to be recovered with good probability even in the presence of errors. The more redundant the codeword, the more resilient it is against errors, and the fewer queries required to recover a bit of the original message.
Overview
More formally, a 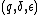 -locally decodable code encodes an
-locally decodable code encodes an  -bit message
-bit message  to an
to an  -bit codeword
-bit codeword  such that any bit
such that any bit  of the message can be recovered with probability
of the message can be recovered with probability  by using a randomized decoding algorithm that queries only
by using a randomized decoding algorithm that queries only  bits of the codeword , even if up to
bits of the codeword , even if up to 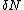 locations of the codeword have been corrupted.
locations of the codeword have been corrupted.
Furthermore, a perfectly smooth local decoder is a decoder such that, in addition to always generating the correct output given access to an uncorrupted codeword, for every 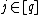 and
and  the
the  query to recover the
query to recover the  bit is uniform over
bit is uniform over 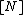 .[5]
.[5]
(The notation 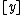 denotes the set
denotes the set 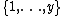 ). Informally, this means that the set of queries required to decode any given bit are uniformly distributed over the codeword.
). Informally, this means that the set of queries required to decode any given bit are uniformly distributed over the codeword.
Local list decoders are another interesting subset of local decoders. List decoding is useful when a codeword is corrupted in more than 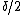 places, where
places, where  is the minimum Hamming distance between two codewords. In this case, it is no longer possible to identify exactly which original message has been encoded, since there could be multiple codewords within distance of the corrupted codeword. However, given a radius
is the minimum Hamming distance between two codewords. In this case, it is no longer possible to identify exactly which original message has been encoded, since there could be multiple codewords within distance of the corrupted codeword. However, given a radius  , it is possible to identify the set of messages that encode to codewords that are within of the corrupted codeword. An upper bound on the size of the set of messages can be determined by and .[6]
, it is possible to identify the set of messages that encode to codewords that are within of the corrupted codeword. An upper bound on the size of the set of messages can be determined by and .[6]
Locally decodable codes can also be concatenated, where a message is encoded first using one scheme, and the resulting codeword is encoded again using a different scheme. (Note that, in this context, concatenation is the term used by scholars to refer to what is usually called composition; see [5]). This might be useful if, for example, the first code has some desirable properties with respect to rate, but it has some undesirable property, such as producing a codeword over a non-binary alphabet. The second code can then transform the result of the first encoding over a non-binary alphabet to a binary alphabet. The final encoding is still locally decodable, and requires additional steps to decode both layers of encoding.[7]
Length of Codeword and Query Complexity
The rate of a code refers to the ratio between its message length and codeword length:  , and the number of queries required to recover 1 bit of the message is called the query complexity of a code.
, and the number of queries required to recover 1 bit of the message is called the query complexity of a code.
The rate of a code is inversely related to the query complexity, but the exact shape of this tradeoff is a major open problem.[8][9] It is known that there are no LDCs that query the codeword in only one position, and that the optimal codeword size for query complexity 2 is exponential in the size of the original message.[8] However, there are no known tight lower bounds for codes with query complexity greater than 2. Approaching the tradeoff from the side of codeword length, the only known codes with codeword length proportional to message length have query complexity 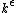 for
for  (THIS LINE IS NOW OUTDATED -- MANY RECENT RESULTS SINCE 2011).[8] There are also codes in between, that have codewords polynomial in the size of the original message and polylogarithmic query complexity.[8]
(THIS LINE IS NOW OUTDATED -- MANY RECENT RESULTS SINCE 2011).[8] There are also codes in between, that have codewords polynomial in the size of the original message and polylogarithmic query complexity.[8]
Applications
Locally decodable codes have applications to data transmission and storage, complexity theory, data structures, derandomization, theory of fault tolerant computation, and private information retrieval schemes.[9]
Data Transmission and Storage
Locally decodable codes are especially useful for data transmission over noisy channels. The Hadamard code (a special case of Reed Muller codes) was used in 1971 by Mariner 9 to transmit pictures of Mars back to Earth. It was chosen over a 5-repeat code (where each bit is repeated 5 times) because, for roughly the same number of bits transmitted per pixel, it had a higher capacity for error correction. (The Hadamard code falls under the general umbrella of forward error correction, and just happens to be locally decodable; the actual algorithm used to decode the transmission from Mars was a generic error-correction scheme.)[10]
LDCs are also useful for data storage, where the medium may become partially corrupted over time, or the reading device is subject to errors. In both cases, an LDC will allow for the recovery of information despite errors, provided that there are relatively few. In addition, LDCs do not require that the entire original message be decoded; a user can decode a specific portion of the original message without needing to decode the entire thing.[11]
Complexity Theory
One of the applications of locally decodable codes in complexity theory is hardness amplification. Using LDCs with polynomial codeword length and polylogarithmic query complexity, one can take a function 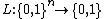 that is hard to solve on worst case inputs and design a function
that is hard to solve on worst case inputs and design a function 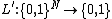 that is hard to compute on average case inputs.
that is hard to compute on average case inputs.
Consider  limited to only length
limited to only length  inputs. Then we can see as a binary string of length
inputs. Then we can see as a binary string of length 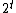 , where each bit is
, where each bit is 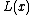 for each
for each 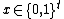 . We can use a polynomial length locally decodable code
. We can use a polynomial length locally decodable code  with polylogarithmic query complexity that tolerates some constant fraction of errors to encode the string that represents to create a new string of length
with polylogarithmic query complexity that tolerates some constant fraction of errors to encode the string that represents to create a new string of length 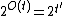 . We think of this new string as defining a new problem
. We think of this new string as defining a new problem  on length
on length  inputs. If is easy to solve on average, that is, we can solve correctly on a large fraction of inputs, then by the properties of the LDC used to encode it, we can use to probabilistically compute on all inputs. Thus, a solution to for most inputs would allow us to solve on all inputs, contradicting our assumption that is hard on worst case inputs.[5][8][12]
inputs. If is easy to solve on average, that is, we can solve correctly on a large fraction of inputs, then by the properties of the LDC used to encode it, we can use to probabilistically compute on all inputs. Thus, a solution to for most inputs would allow us to solve on all inputs, contradicting our assumption that is hard on worst case inputs.[5][8][12]
Private Information Retrieval Schemes
A private information retrieval scheme allows a user to retrieve an item from a server in possession of a database without revealing which item is retrieved. One common way of ensuring privacy is to have  separate, non-communicating servers, each with a copy of the database. Given an appropriate scheme, the user can make queries to each server that individually do not reveal which bit the user is looking for, but which together provide enough information that the user can determine the particular bit of interest in the database.[3][11]
separate, non-communicating servers, each with a copy of the database. Given an appropriate scheme, the user can make queries to each server that individually do not reveal which bit the user is looking for, but which together provide enough information that the user can determine the particular bit of interest in the database.[3][11]
One can easily see that locally decodable codes have applications in this setting. A general procedure to produce a -server private information scheme from a perfectly smooth -query locally decodable code is as follows:
Let be a perfectly smooth LDC that encodes -bit messages to -bit codewords. As a preprocessing step, each of the servers 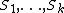 encodes the -bit database with the code , so each server now stores the -bit codeword . A user interested in obtaining the bit of randomly generates a set of queries
encodes the -bit database with the code , so each server now stores the -bit codeword . A user interested in obtaining the bit of randomly generates a set of queries 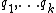 such that can be computed from
such that can be computed from  using the local decoding algorithm
using the local decoding algorithm  for . The user sends each query to a different server, and each server responds with the bit requested. The user then uses to compute from the responses.[8][11]
for . The user sends each query to a different server, and each server responds with the bit requested. The user then uses to compute from the responses.[8][11]
Because the decoding algorithm is perfectly smooth, each query 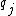 is uniformly distributed over the codeword; thus, no individual server can gain any information about the user's intentions, so the protocol is private as long as the servers do not communicate.[11]
is uniformly distributed over the codeword; thus, no individual server can gain any information about the user's intentions, so the protocol is private as long as the servers do not communicate.[11]
Examples
The Hadamard code
The Hadamard (or Walsh-Hadamard) code is an example of a simple locally decodable code that maps a string of length to a codeword of length  . The codeword for a string
. The codeword for a string 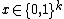 is constructed as follows: for every
is constructed as follows: for every 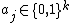 , the bit of the codeword is equal to
, the bit of the codeword is equal to 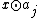 , where
, where 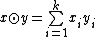 (mod 2). It is easy to see that every codeword has a Hamming distance of
(mod 2). It is easy to see that every codeword has a Hamming distance of  from every other codeword.
from every other codeword.
The local decoding algorithm has query complexity 2, and the entire original message can be decoded with good probability if the codeword is corrupted in less than  of its bits. For
of its bits. For  , if the codeword is corrupted in a
, if the codeword is corrupted in a  fraction of places, a local decoding algorithm can recover the bit of the original message with probability
fraction of places, a local decoding algorithm can recover the bit of the original message with probability 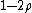 .
.
Proof: Given a codeword  and an index
and an index 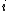 , the algorithm to recover the bit of the original message works as follows:
, the algorithm to recover the bit of the original message works as follows:
Let 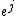 refer to the vector in
refer to the vector in 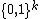 that has 1 in the position and 0s elsewhere. For
that has 1 in the position and 0s elsewhere. For 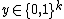 ,
,  denotes the single bit in that corresponds to
denotes the single bit in that corresponds to 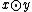 . The algorithm chooses a random vector and the vector
. The algorithm chooses a random vector and the vector 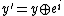 (where
(where  denotes bitwise XOR). The algorithm outputs
denotes bitwise XOR). The algorithm outputs 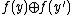 (mod 2).
(mod 2).
Correctness: By linearity,
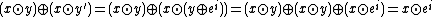
But 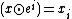 , so we just need to show that
, so we just need to show that  and
and 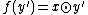 with good probability.
with good probability.
Since  and
and  are uniformly distributed (even though they are dependent), the union bound implies that and with probability at least . Note: to amplify the probability of success, one can repeat the procedure with different random vectors and take the majority answer.
are uniformly distributed (even though they are dependent), the union bound implies that and with probability at least . Note: to amplify the probability of success, one can repeat the procedure with different random vectors and take the majority answer.
The Reed–Muller code
The main idea behind local decoding of Reed-Muller codes is polynomial interpolation. The key concept behind a Reed-Muller code is a multivariate polynomial of degree  on
on  variables. The message is treated as the evaluation of a polynomial at a set of predefined points. To encode these values, a polynomial is extrapolated from them, and the codeword is the evaluation of that polynomial on all possible points. At a high level, to decode a point of this polynomial, the decoding algorithm chooses a set
variables. The message is treated as the evaluation of a polynomial at a set of predefined points. To encode these values, a polynomial is extrapolated from them, and the codeword is the evaluation of that polynomial on all possible points. At a high level, to decode a point of this polynomial, the decoding algorithm chooses a set  of points on a line that passes through the point of interest . It then queries the codeword for the evaluation of the polynomial on points in and interpolates that polynomial. Then it is simple to evaluate the polynomial at the point that will yield . This roundabout way of evaluating is useful because (a) the algorithm can be repeated using different lines through the same point to improve the probability of correctness, and (b) the queries are uniformly distributed over the codeword.
of points on a line that passes through the point of interest . It then queries the codeword for the evaluation of the polynomial on points in and interpolates that polynomial. Then it is simple to evaluate the polynomial at the point that will yield . This roundabout way of evaluating is useful because (a) the algorithm can be repeated using different lines through the same point to improve the probability of correctness, and (b) the queries are uniformly distributed over the codeword.
More formally, let 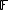 be a finite field, and let
be a finite field, and let 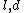 be numbers with
be numbers with  . The Reed-Muller code with parameters
. The Reed-Muller code with parameters 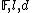 is the function RM :
is the function RM : 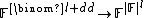 that maps every -variable polynomial
that maps every -variable polynomial  over of total degree to the values of on all the inputs in
over of total degree to the values of on all the inputs in  . That is, the input is a polynomial of the form
. That is, the input is a polynomial of the form
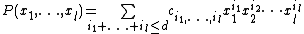
specified by the interpolation of the  values of the predefined points and the output is the sequence
values of the predefined points and the output is the sequence 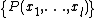 for every
for every 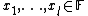 .[14]
.[14]
To recover the value of a degree polynomial at a point 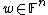 , the local decoder shoots a random affine line through
, the local decoder shoots a random affine line through  . Then it picks
. Then it picks  points on that line, which it uses to interpolate the polynomial and then evaluate it at the point where the result is . To do so, the algorithm picks a vector
points on that line, which it uses to interpolate the polynomial and then evaluate it at the point where the result is . To do so, the algorithm picks a vector 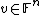 uniformly at random and considers the line
uniformly at random and considers the line 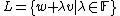 through . The algorithm picks an arbitrary subset of , where
through . The algorithm picks an arbitrary subset of , where 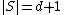 , and queries coordinates of the codeword that correspond to points
, and queries coordinates of the codeword that correspond to points 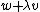 for all
for all 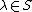 and obtains values
and obtains values 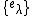 . Then it uses polynomial interpolation to recover the unique univariate polynomial
. Then it uses polynomial interpolation to recover the unique univariate polynomial  with degree less than or equal to such that
with degree less than or equal to such that 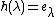 for all . Then, to get the value of , it just evaluates
for all . Then, to get the value of , it just evaluates 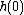 . To recover a single value of the original message, one chooses to be one of the points that defines the polynomial.[8][14]
. To recover a single value of the original message, one chooses to be one of the points that defines the polynomial.[8][14]
Each individual query is distributed uniformly at random over the codeword. Thus, if the codeword is corrupted in at most a fraction of locations, by the union bound, the probability that the algorithm samples only uncorrupted coordinates (and thus correctly recovers the bit) is at least 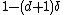 .[8]
.[8]
For other decoding algorithms, see.[8]
See also
- Private information retrieval
- Linear cryptanalysis
References
2. ^{{cite web|url=http://eprint.iacr.org/2007/025.pdf|format=PDF |title=Private Locally Decodable Codes|author1=Rafail Ostrovsky |author2=Omkant Pandey |author3=Amit Sahai }}
3. ^1 Sergey Yekhanin. New locally decodable codes and private information retrieval schemes, Technical Report ECCC TR06-127, 2006.
4. ^{{cite web|url=http://eccc.hpi-web.de/report/2010/130/revision/1/download/ |title=Locally Testable vs. Locally Decodable Codes |author1=Tali Kaufman |author2=Michael Viderman }}
5. ^1 2 {{cite web|url=http://theory.stanford.edu/~trevisan/pubs/codingsurvey.pdf |format=PDF |title=Some Applications of Coding Theory in Computational Complexity |author=Luca Trevisan}}
6. ^{{Cite book |chapter=Section 19.5| last1=Arora | first1=Sanjeev | authorlink1=Sanjeev Arora| last2=Barak | first2=Boaz| title=Computational Complexity: A Modern Approach| url = http://www.cs.princeton.edu/theory/complexity/| publisher=Cambridge| year=2009| isbn=978-0-521-42426-4| postscript=. |ref=harv}}
7. ^{{harvnb|Arora|Barak|2009|loc=Section 19.4.3}}
8. ^1 2 3 4 5 6 7 8 {{cite web|url=http://research.microsoft.com/en-us/um/people/yekhanin/Papers/LDC_now.pdf |format=PDF |title=Locally Decodable Codes |author=Sergey Yekhanin}}
9. ^1 {{cite web|url=https://www.iacr.org/workshops/tcc2012/survey_tcc.pdf |format=PDF |title=Locally Decodable Codes |author=Sergey Yekhanin}}
10. ^{{cite web |title=Combinatorics in Space The Mariner 9 Telemetry System |url=http://www-math.ucdenver.edu/~wcherowi/courses/m7409/mariner9talk.pdf|format=PDF }}
11. ^1 2 3 {{cite web|url=http://research.microsoft.com/pubs/141305/cacm_2010.pdf |title=Private Information retrieval |author=Sergey Yekhanin}}
12. ^{{harvnb|Arora|Barak|2009|loc=Section 19.4}}
13. ^{{harvnb|Arora|Barak|2009|loc=Section 11.5.2}}
14. ^1 {{harvnb|Arora|Barak|2009|loc=Section 19.4.2}}
- Ichthyosis deafness mental retardation skeletal anomaly
- Ichthyosis en confetti
- Ichthyostomum
- Ichthyothereol
- Ichthyotoxic
- Ichthyotoxin
- Ichthyovenator
- Ichthyovenator laosensis
- Ichthys gas field
- Ichthyura argentea
- Ichthyura inclusa
- Ichthyura inversa
- Ichthyura jocosa
- Ichtiar Baru van Hoeve
- ICHTO
- Ichts aus Nichts, für alle Begierigen der Natur
- Ichtyoselmis macrantha
- Ichubulaq
- Ichud
- Ichud Hakehillos
- Ichud HaKehillos
- Ichud Hakehillos Letohar Hamachane
- Ichud HaKehillos LeTohar HaMachane
- Ichun
- Ichunayoc