- Definition Example Upper and lower bounds
- Applications
- Relationship with other edit distance metrics
- Computing Levenshtein distance Recursive Iterative with full matrix Iterative with two matrix rows Word Preparation Adaptive variant Approximation Computational complexity
- See also
- References
- External links
In information theory, linguistics and computer science, the Levenshtein distance is a string metric for measuring the difference between two sequences. Informally, the Levenshtein distance between two words is the minimum number of single-character edits (insertions, deletions or substitutions) required to change one word into the other. It is named after the Soviet mathematician Vladimir Levenshtein, who considered this distance in 1965.[1]
Levenshtein distance may also be referred to as edit distance, although that term may also denote a larger family of distance metrics.[2]{{rp|32}} It is closely related to pairwise string alignments.
Definition
Mathematically, the Levenshtein distance between two strings  (of length
(of length  and
and  respectively) is given by
respectively) is given by  where
where

where  is the indicator function equal to 0 when
is the indicator function equal to 0 when  and equal to 1 otherwise, and
and equal to 1 otherwise, and  is the distance between the first
is the distance between the first 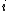 characters of
characters of  and the first
and the first  characters of
characters of  .
.
Note that the first element in the minimum corresponds to deletion (from to ), the second to insertion and the third to match or mismatch, depending on whether the respective symbols are the same.
Example
For example, the Levenshtein distance between "kitten" and "sitting" is 3, since the following three edits change one into the other, and there is no way to do it with fewer than three edits:
- kitten → sitten (substitution of "s" for "k")
- sitten → sittin (substitution of "i" for "e")
- sittin → sitting (insertion of "g" at the end).
Upper and lower bounds
The Levenshtein distance has several simple upper and lower bounds. These include:
- It is at least the difference of the sizes of the two strings.
- It is at most the length of the longer string.
- It is zero if and only if the strings are equal.
- If the strings are the same size, the Hamming distance is an upper bound on the Levenshtein distance.
- The Levenshtein distance between two strings is no greater than the sum of their Levenshtein distances from a third string (triangle inequality).
An example where the Levenshtein distance between two strings of the same length is strictly less than the Hamming distance is given by the pair "flaw" and "lawn". Here the Levenshtein distance equals 2 (delete "f" from the front; insert "n" at the end). The Hamming distance is 4.
Applications
In approximate string matching, the objective is to find matches for short strings in many longer texts, in situations where a small number of differences is to be expected. The short strings could come from a dictionary, for instance. Here, one of the strings is typically short, while the other is arbitrarily long. This has a wide range of applications, for instance, spell checkers, correction systems for optical character recognition, and software to assist natural language translation based on translation memory.
The Levenshtein distance can also be computed between two longer strings, but the cost to compute it, which is roughly proportional to the product of the two string lengths, makes this impractical. Thus, when used to aid in fuzzy string searching in applications such as record linkage, the compared strings are usually short to help improve speed of comparisons.{{citation needed|date=January 2019}}
In linguistics, the Levenshtein distance is used as a metric to quantify the linguistic distance, or how different two languages are from one another.[3] It is related to mutual intelligibility, the higher the linguistic distance, the lower the mutual intelligibility, and the lower the linguistic distance, the higher the mutual intelligibility.
Relationship with other edit distance metrics
{{main|Edit distance}}There are other popular measures of edit distance, which are calculated using a different set of allowable edit operations. For instance,
- the Damerau–Levenshtein distance allows insertion, deletion, substitution, and the transposition of two adjacent characters;
- the longest common subsequence (LCS) distance allows only insertion and deletion, not substitution;
- the Hamming distance allows only substitution, hence, it only applies to strings of the same length.
- the Jaro distance allows only transposition.
Edit distance is usually defined as a parameterizable metric calculated with a specific set of allowed edit operations, and each operation is assigned a cost (possibly infinite). This is further generalized by DNA sequence alignment algorithms such as the Smith–Waterman algorithm, which make an operation's cost depend on where it is applied.
Computing Levenshtein distance
Recursive
This is a straightforward, but inefficient, recursive C implementation of a LevenshteinDistance function that takes two strings, s and t, together with their lengths, and returns the Levenshtein distance between them:
// len_s and len_t are the number of characters in string s and t respectively int LevenshteinDistance(const char *s, int len_s, const char *t, int len_t) } /* base case: empty strings */ if (len_s == 0) return len_t; if (len_t == 0) return len_s;
/* test if last characters of the strings match */ if (s[len_s-1] == t[len_t-1]) cost = 0; else cost = 1;
/* return minimum of delete char from s, delete char from t, and delete char from both */ return minimum(LevenshteinDistance(s, len_s - 1, t, len_t ) + 1, LevenshteinDistance(s, len_s , t, len_t - 1) + 1, LevenshteinDistance(s, len_s - 1, t, len_t - 1) + cost);
This implementation is very inefficient because it recomputes the Levenshtein distance of the same substrings many times.
A more efficient method would never repeat the same distance calculation. For example, the Levenshtein distance of all possible prefixes might be stored in an array {{code|lang=C|code=d[][]}} where {{code|lang=C|code=d[i][j]}} is the distance between the first i characters of string s and the first j characters of string t. The table is easy to construct one row at a time starting with row 0. When the entire table has been built, the desired distance is {{code|lang=C|code=d[len_s][len_t]}}.
Iterative with full matrix
{{main|Wagner–Fischer algorithm}}{{small|Note: This section uses 1-based strings instead of 0-based strings}}
Computing the Levenshtein distance is based on the observation that if we reserve a matrix to hold the Levenshtein distances between all prefixes of the first string and all prefixes of the second, then we can compute the values in the matrix in a dynamic programming fashion, and thus find the distance between the two full strings as the last value computed.
This algorithm, an example of bottom-up dynamic programming, is discussed, with variants, in the 1974 article The String-to-string correction problem by Robert A. Wagner and Michael J. Fischer.[4]
This is a straightforward pseudocode implementation for a function LevenshteinDistance that takes two strings, s of length m, and t of length n, and returns the Levenshtein distance between them:
function LevenshteinDistance(char s[1..m], char t[1..n]): // for all i and j, d[i,j] will hold the Levenshtein distance between // the first i characters of s and the first j characters of t // note that d has (m+1)*(n+1) values declare int d[0..m, 0..n] set each element in d to zero // source prefixes can be transformed into empty string by // dropping all characters for i from 1 to m: d[i, 0] := i // target prefixes can be reached from empty source prefix // by inserting every character for j from 1 to n: d[0, j] := j for j from 1 to n: for i from 1 to m: if s[i] = t[j]: substitutionCost := 0 else: substitutionCost := 1 d[i, j] := minimum(d[i-1, j] + 1, // deletion d[i, j-1] + 1, // insertion d[i-1, j-1] + substitutionCost) // substitution return d[m, n]
Two examples of the resulting matrix (hovering over a tagged number reveals the operation performed to get that number):
| k | i | t | t | e | n | ||
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | |
| s | 1 | substitution of 's' for 'k'|1}} | 2 | 3 | 4 | 5 | 6 |
| i | 2 | 2 | 'i' equals 'i'|1}} | 2 | 3 | 4 | 5 |
| t | 3 | 3 | 2 | 't' equals 't'|1}} | 2 | 3 | 4 |
| t | 4 | 4 | 3 | 2 | 't' equals 't'|1}} | 2 | 3 |
| i | 5 | 5 | 4 | 3 | 2 | substitution of 'i' for 'e'|2}} | 3 |
| n | 6 | 6 | 5 | 4 | 3 | 3 | 'n' equals 'n'|2}} |
| g | 7 | 7 | 6 | 5 | 4 | 4 | insert 'g'|3}} |
| S | a | t | u | r | d | a | y | ||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| S | 1 | 'S' equals 'S'|0}} | delete 'a'|1}} | delete 't'|2}} | 3 | 4 | 5 | 6 | 7 |
| u | 2 | 1 | 1 | 2 | 'u' equals 'u'|2}} | 3 | 4 | 5 | 6 |
| n | 3 | 2 | 2 | 2 | 3 | substitution of 'n' for 'r'|3}} | 4 | 5 | 6 |
| d | 4 | 3 | 3 | 3 | 3 | 4 | 'd' equals 'd'|3}} | 4 | 5 |
| a | 5 | 4 | 3 | 4 | 4 | 4 | 4 | 'a' equals 'a'|3}} | 4 |
| y | 6 | 5 | 4 | 4 | 5 | 5 | 5 | 4 | 'y' equals 'y'|3}} |
The invariant maintained throughout the algorithm is that we can transform the initial segment {{code|lang=C|code=s[1..i]}} into {{code|lang=C|code=t[1..j]}} using a minimum of {{code|lang=C|code=d[i,j]}} operations. At the end, the bottom-right element of the array contains the answer.
Iterative with two matrix rows
It turns out that only two rows of the table are needed for the construction if one does not want to reconstruct the edited input strings (the previous row and the current row being calculated).
The Levenshtein distance may be calculated iteratively using the following algorithm:[5]
function LevenshteinDistance(char s[1..m], char t[1..n]):
// create two work vectors of integer distances declare int v0[n + 1] declare int v1[n + 1]
// initialize v0 (the previous row of distances) // this row is A[0][i]: edit distance for an empty s // the distance is just the number of characters to delete from t for i from 0 to n: v0[i] = i
for i from 0 to m-1: // calculate v1 (current row distances) from the previous row v0
// first element of v1 is A[i+1][0] // edit distance is delete (i+1) chars from s to match empty t v1[0] = i + 1
// use formula to fill in the rest of the row for j from 0 to n-1: // calculating costs for A[i+1][j+1] deletionCost := v0[j + 1] + 1 insertionCost := v1[j] + 1 if s[i] = t[j]: substitutionCost := v0[j] else: substitutionCost := v0[j] + 1
// copy v1 (current row) to v0 (previous row) for next iteration swap v0 with v1 // after the last swap, the results of v1 are now in v0 return v0[n]
(The above is also true for two-columns, as the Levenshtein matrix can be imagined flipped across a diagonal vertex and get the same results.)
This two row variant is suboptimal—the amount of memory required may be reduced to one row and one word of overhead.[6] And similarly if, a Levenshtein distance algorithm exists for one row then the same can be achieved with one column. A one column algorithm would lend itself to SQL and other database languages.
Hirschberg's algorithm combines this method with divide and conquer. It can compute the optimal edit sequence, and not just the edit distance, in the same asymptotic time and space bounds.[7]Word Preparation
It can be shown that the Levenshtein Distance between "Saturday" and "Sunday" is the same as between "atur" and "un" (Saturday and Sunday).
Use of a preparation algorithm that shortens the words to compare by removing similar characters from the beginning of each word and by removing similar characters from the end of each word can reduce the computing time for the Levenshtein distance calculation. If after preparation one of the strings is empty then the Levenshtein distance is the length of the other string. "Kit" and "Kitten" would become "" and "ten", so L = 3. Obviously, this is best used when it's known in advance that strings have a high probabilty of being similar.
Adaptive variant
The dynamic variant is not the ideal implementation. An adaptive approach may reduce the amount of memory required and, in the best case, may reduce the time complexity to linear in the length of the shortest string, and, in the worst case, no more than quadratic in the length of the shortest string. [8]
Approximation
The Levenshtein distance between two strings of length {{mvar|n}} can be approximated to within a factor

where {{math|ε > 0}} is a free parameter to be tuned, in time {{math|O(n1 + ε)}}.[9]
Computational complexity
It has been shown that the Levenshtein distance of two strings of length {{mvar|n}} cannot be computed in time {{math|O(n2 - ε)}} for any ε greater than zero unless the strong exponential time hypothesis is false.[10]
See also
{{div col|colwidth=25em}}- agrep
- Damerau–Levenshtein distance
- diff
- Dynamic time warping
- Euclidean distance
- Homology of sequences in genetics
- Hunt–McIlroy algorithm
- Jaccard index
- Locality-sensitive hashing
- Longest common subsequence problem
- Lucene (an open source search engine that implements edit distance)
- Manhattan distance
- Metric space
- MinHash
- Most frequent k characters
- Optimal matching algorithm
- Numerical taxonomy
- Sørensen similarity index
References
2. ^{{Cite journal |last1=Navarro |first1=Gonzalo |doi=10.1145/375360.375365 |title=A guided tour to approximate string matching |journal=ACM Computing Surveys |volume=33 |issue=1 |pages=31–88 |year=2001 |url=http://repositorio.uchile.cl/bitstream/handle/2250/126168/Navarro_Gonzalo_Guided_tour.pdf|citeseerx=10.1.1.452.6317 }}
3. ^{{Citation | title=Receptive multilingualism: linguistic analyses, language policies, and didactic concepts |author1=Jan D. ten Thije |author2=Ludger Zeevaert | publisher=John Benjamins Publishing Company, 2007 | isbn=978-90-272-1926-8 | url=https://books.google.com/books?id=8gIEN068J3gC&q=Levenshtein#v=snippet&q=Levenshtein&f=false | quote=... Assuming that intelligibility is inversely related to linguistic distance ... the content words the percentage of cognates (related directly or via a synonym) ... lexical relatedness ... grammatical relatedness ...|date=2007-01-01 }}
4. ^{{citation |first=Robert A. |last=Wagner |first2=Michael J. |last2=Fischer |author2-link=Michael J. Fischer |title=The String-to-String Correction Problem |journal=Journal of the ACM |volume=21 |issue=1 |year=1974 |pages=168–173 |doi= 10.1145/321796.321811}}
5. ^{{Citation |title=Fast, memory efficient Levenshtein algorithm |first=Sten |last=Hjelmqvist |date=26 Mar 2012 |url=http://www.codeproject.com/Articles/13525/Fast-memory-efficient-Levenshtein-algorithm}}
6. ^{{cite web | url=https://bitbucket.org/clearer/iosifovich/ | title=Clearer / Iosifovich}}
7. ^{{cite journal|last=Hirschberg|first=D. S.|authorlink=Dan Hirschberg|title=A linear space algorithm for computing maximal common subsequences|journal=Communications of the ACM|volume=18|issue=6|year=1975|pages=341–343|doi=10.1145/360825.360861|mr=0375829|url=http://www.ics.uci.edu/~dan/pubs/p341-hirschberg.pdf|type=Submitted manuscript|bibcode=1985CACM...28...22S|citeseerx=10.1.1.348.4774}}
8. ^{{cite web | url=https://bitbucket.org/clearer/iosifovich/ | title=Clearer / Iosifovich}}
9. ^{{cite conference |last1=Andoni |first1=Alexandr |first2=Robert |last2=Krauthgamer |first3=Krzysztof |last3=Onak |title=Polylogarithmic approximation for edit distance and the asymmetric query complexity |conference=IEEE Symp. Foundations of Computer Science (FOCS) |year=2010 |citeseerx=10.1.1.208.2079 |arxiv=1005.4033|bibcode=2010arXiv1005.4033A }}
10. ^{{cite conference |last1=Backurs |first1=Arturs |first2=Piotr |last2=Indyk |title= Edit Distance Cannot Be Computed in Strongly Subquadratic Time (unless SETH is false) |conference=Forty-Seventh Annual ACM on Symposium on Theory of Computing (STOC) |year=2015 | arxiv=1412.0348|bibcode=2014arXiv1412.0348B }}
External links
{{Wikibooks| Algorithm implementation|Strings/Levenshtein distance|Levenshtein distance}}- {{citation |contribution=Levenshtein distance |title=Dictionary of Algorithms and Data Structures [online] |editor-first=Paul E. |editor-last=Black |publisher=U.S. National Institute of Standards and Technology |date=14 August 2008 |accessdate=2 November 2016 |url=https://xlinux.nist.gov/dads/HTML/Levenshtein.html }}
- Lille Storberg
- Lillestrom, Norway
- Lillestrom SK
- Lillestrom S.K.
- Lillestrom SK season 2008
- Lillestrom Sportsklubb
- Lillestrom stadion
- Lillestrom Station
- Lillestrøm SK 2
- Lillestrøm SK 3
- Lillestrøm S.K. season 2008
- Lillestrøm S.K. season 2009
- Lillestrøm SK season 2009
- Lillestrøm SK season 2010
- Lillestrøm stadion
- Lille Subway
- Lillet Blan
- Lillet Blaw
- Lille Tramway
- Lille tramway
- Lil-lets
- Lille University
- Lille University Northern France
- Lille University, Northern France
- Lilley and Gillie