- Definition Discrete probability distribution Continuous probability distribution In general
- Example 1
- Interpretations under different foundations Frequentist interpretation Bayesian interpretation Likelihoodist interpretation AIC-based interpretation
- Likelihood ratio Purposes
- Products of likelihoods
- Log-likelihood Exponential families Example: the gamma distribution
- Likelihood function of a parameterized model Likelihoods for continuous distributions Likelihoods for mixed continuous–discrete distributions
- Example 2
- Relative likelihood Relative likelihood function Likelihood region Relative likelihood of models
- Likelihoods that eliminate nuisance parameters Conditional likelihood Marginal likelihood Profile likelihood Partial likelihood
- Historical remarks
- See also
- Notes
- References
- Further reading
- External links
In statistics, a likelihood function (often simply a likelihood) is a particular function of the parameter of a statistical model given data. Likelihood functions play a key role in statistical inference.
In informal contexts, "likelihood" is often used as a synonym for "probability". In statistics, the two terms have different meanings. Probability is used to describe the plausibility of some data, given a value for the parameter. Likelihood is used to describe the plausibility of a value for the parameter, given some data.
Likelihood is used with each of the main proposed foundations of statistics: frequentism, Bayesianism, likelihoodism, and AIC-based.[1] The case for using likelihood in the foundation of statistics was first made by the founder of modern statistics, R. A. Fisher; a relevant quotation is below.
{{quote|text=What has now appeared is that the mathematical concept of probability is ... inadequate to express our mental confidence or [lack of confidence] in making ... inferences, and that the mathematical quantity which usually appears to be appropriate for measuring our order of preference among different possible populations does not in fact obey the laws of probability. To distinguish it from probability, I have used the term "likelihood" to designate this quantity....|source= R. A. Fisher, Statistical Methods for Research Workers{{resize|33%| }}[2]}}Definition
The likelihood function is usually defined differently for discrete and continuous probability distributions. A general definition is also possible, as discussed below.
Discrete probability distribution
Let 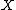 be a discrete random variable with probability mass function
be a discrete random variable with probability mass function  depending on a parameter
depending on a parameter  . Then the function
. Then the function

considered as a function of , is the likelihood function (of ), given the outcome  of the random variable . Sometimes the probability of "the value of for the parameter value {{resize|20%| }}" is written as {{math|P(X {{=}} x {{!}} θ)}} or {{math|P(X {{=}} x; θ)}}.
of the random variable . Sometimes the probability of "the value of for the parameter value {{resize|20%| }}" is written as {{math|P(X {{=}} x {{!}} θ)}} or {{math|P(X {{=}} x; θ)}}.
Continuous probability distribution
Let be a random variable following an absolutely continuous probability distribution with density function  depending on a parameter . Then the function
depending on a parameter . Then the function

considered as a function of , is the likelihood function (of , given the outcome of ). Sometimes the density function for "the value of for the parameter value {{resize|20%| }}" is written as  ; this should not be confused with
; this should not be confused with  , which should not be considered a conditional probability density.
, which should not be considered a conditional probability density.
In general
In measure-theoretic probability theory, the density function is defined as the Radon–Nikodym derivative of the probability distribution relative to a common dominating measure.[3] The likelihood function is that density interpreted as a function of the parameter (possibly a vector), rather than the possible outcomes.[4] This provides a likelihood function for any probability model with all distributions, whether discrete, absolutely continuous, a mixture or something else. (Likelihoods will be comparable, e.g. for parameter estimation, only if they are Radon–Nikodym derivatives with respect to the same dominating measure.)
The discussion above of likelihood with discrete probabilities is a special case of this using the counting measure, which makes the probability of any single outcome equal to the probability density for that outcome.
Note that given no event (no data), the probability and thus likelihood is 1;{{cn|date=March 2019}} any non-trivial event will have lower likelihood.
Example 1
Consider a simple statistical model of a coin flip: a single parameter  that expresses the "fairness" of the coin. The parameter is the probability that a coin lands heads up ("H") when tossed. can take on any value within the range 0.0 to 1.0. For a perfectly fair coin, = 0.5.
that expresses the "fairness" of the coin. The parameter is the probability that a coin lands heads up ("H") when tossed. can take on any value within the range 0.0 to 1.0. For a perfectly fair coin, = 0.5.
Imagine flipping a fair coin twice, and observing the following data: two heads in two tosses ("HH"). Assuming that each successive coin flip is i.i.d., then the probability of observing HH is
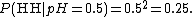
Hence, given the observed data HH, the likelihood that the model parameter equals 0.5 is 0.25. Mathematically, this is written as

This is not the same as saying that the probability that 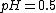 , given the observation HH, is 0.25. (For that, we could apply Bayes' theorem, which implies that the posterior probability is proportional to the likelihood times the prior probability.)
, given the observation HH, is 0.25. (For that, we could apply Bayes' theorem, which implies that the posterior probability is proportional to the likelihood times the prior probability.)
Suppose that the coin is not a fair coin, but instead it has  . Then the probability of getting two heads is
. Then the probability of getting two heads is

Hence
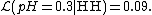
More generally, for each value of , we can calculate the corresponding likelihood. The result of such calculations is displayed in Figure 1.
In Figure 1, the integral of the likelihood over the interval [0, 1] is 1/3. That illustrates an important aspect of likelihoods: likelihoods do not have to integrate (or sum) to 1, unlike probabilities.
Interpretations under different foundations
Among statisticians, there is no consensus about what the foundation of statistics should be. There are four main paradigms that have been proposed for the foundation: frequentism, Bayesianism, likelihoodism, and AIC-based.[1] For each of the proposed foundations, the interpretation of likelihood is different. The four interpretations are described in the subsections below.
Frequentist interpretation
{{empty section|date=March 2019}}Bayesian interpretation
In Bayesian inference, although one can speak about the likelihood of any proposition or random variable given another random variable: for example the likelihood of a parameter value or of a statistical model (see marginal likelihood), given specified data or other evidence,[5][6][7][8] the likelihood function remains the same entity, with the additional interpretations of (i) a conditional density of the data given the parameter (since the parameter is then a random variable) and (ii) a measure or amount of information brought by the data about the parameter value or even the model.[5][6][7][8][9] Due to the introduction of a probability structure on the parameter space or on the collection of models, it is a possible that a parameter value or a statistical model have a large likelihood value for given data, and yet have a low probability, or vice versa.[7][9] This is often the case in medical contexts.[10] Following Bayes' Rule, the likelihood when seen as a conditional density can be multiplied by the prior probability density of the parameter and then normalized, to give a posterior probability density.[5][6][7][8][9]. More generally, the likelihood of an unknown quantity given another unknown quantity  is the probability of given [5][6][7][8][9].
is the probability of given [5][6][7][8][9].
Likelihoodist interpretation
{{empty section|date=March 2019}}AIC-based interpretation
{{expand section|date=March 2019}}Under the AIC paradigm, likelihood is interpreted within the context of information theory.[11][12][13]
Likelihood ratio
A likelihood ratio is the ratio of any two specified likelihoods: {{tmath|\\mathcal{L}(\\theta_1 \\mid x)/\\mathcal{L}(\\theta_2 \\mid x)}}. Likelihood ratios are frequently written as {{tmath|\\Lambda}}, as follows.

The likelihood ratio of two models, given the same event, may be contrasted with the odds of two events, given the same model. In terms of a parametrized probability mass function {{tmath|p_\\theta(x)}}, the likelihood ratio of two values of the parameter {{tmath|\\theta_1}} and {{tmath|\\theta_2}}, given an outcome {{tmath|x}} is:

while the odds of two outcomes, {{tmath|x_1}} and {{tmath|x_2}}, given a value of the parameter {{tmath|\\theta}}, is:
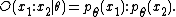
This highlights the difference between likelihood and odds: in likelihood, one compares models (parameters), holding data fixed; while in odds, one compares events (outcomes, data), holding the model fixed.
The odds ratio is a ratio of two conditional odds (of an event, given another event being present or absent). However, the odds ratio can also be interpreted as a ratio of two likelihoods ratios, if one considers one of the events to be more easily observable than the other. See diagnostic odds ratio, where the result of a diagnostic test is more easily observable than the presence or absence of an underlying medical condition.
Given no event (no data), the likelihoods are both 1, and thus the likelihood ratio is also 1: in the absence of data, there is no evidence to distinguish two models.
Purposes
The likelihood ratio is central to likelihoodist statistics: the law of likelihood states that degree to which data (considered as evidence) supports one parameter value versus another is measured by the likelihood ratio.
The likelihood ratio is also of central importance in Bayesian inference, where it is known as the Bayes factor, and is used in Bayes' rule. Stated in terms of odds, Bayes' rule is that the posterior odds of two alternatives, {{tmath|A_1}} and {{tmath|A_2}}, given an event {{tmath|B}}, is the prior odds, times the likelihood ratio. As an equation:

The likelihood ratio is also used in frequentist inference as a test statistic in the likelihood-ratio test. By the Neyman–Pearson lemma, this is the most powerful test for comparing two simple hypotheses at a given significance level. The likelihood ratio is thus of great interest in frequentist inference, but is not as central as in Bayesian statistics. Numerous other tests can be viewed as likelihood-ratio tests or approximations thereof. The asymptotic distribution of the log-likelihood ratio, considered as a test statistic, is given by Wilks' theorem.
The likelihood ratio is not directly used in AIC-based statistics. Instead, what is used is the relative likelihood of models (see below).
Products of likelihoods
The likelihood, given two or more independent events, is the product of the likelihoods of each of the individual events:
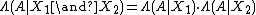
This follows from the definition of independence in probability: the probabilities of two independent events happening, given a model, is the product of the probabilities.
This is particularly important when the events are from independent and identically distributed random variables, such as independent observations or sampling with replacement. In such a situation, the likelihood function factors into a product of individual likelihood functions.
The empty product has value 1, which corresponds to the likelihood, given no event, being 1: before any data, the likelihood is always 1. This is similar to a uniform prior in Bayesian statistics, but in likelihoodist statistics this is not an improper prior because likelihoods are not integrated.
Log-likelihood
{{also|Log-probability}}Because one is primarily interested in ratios and products of likelihoods, the logarithm of the likelihood function is often easier to work with, since logarithms convert multiplication to addition: ratios become differences, and products become sums. This is called the log-likelihood, the {{visible anchor|loglihood}}[14] or the {{visible anchor|support}}.{{sfn|Edwards|1972|p=12}} Often the log-likelihood is denoted by a lowercase {{math|l}} or {{tmath|\\ell}}, to contrast with the uppercase {{math|L}} or  for the likelihood.
for the likelihood.
In addition to the mathematical convenience, the log-likelihood has an intuitive interpretation, as suggested by the term "support". Given independent events, the overall log-likelihood is the sum of the log-likelihoods of the individual events, just as the overall log-probability is the sum of the log-probability of the individual events. Viewing data as evidence, this is interpreted as "support from independent evidence adds", and the log-likelihood is the "weight of evidence". Interpreting negative log-probability as information content or surprisal, the support (log-likelihood) of a model, given an event, is the negative of the surprisal of the event, given the model: a model is supported by an event to the extent that the event is unsurprising, given the model.
The choice of base {{math|b}} for the logarithm corresponds to a choice of scale;{{efn|The scale factor is {{tmath|\\log_a b}}; see {{slink|Logarithm|Change of base}}}} generally the natural logarithm is used and the base is fixed, but sometimes the base is varied, in which case, writing the base as 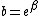 , the factor {{mvar|β}} can be interpreted as the coldness.{{efn|"Coldness" is also known as thermodynamic beta or inverse temperature; See Watanabe–Akaike information criterion and {{slink|Softmax function|Statistical mechanics}} for examples of varying the coldness.}}
, the factor {{mvar|β}} can be interpreted as the coldness.{{efn|"Coldness" is also known as thermodynamic beta or inverse temperature; See Watanabe–Akaike information criterion and {{slink|Softmax function|Statistical mechanics}} for examples of varying the coldness.}}
A logarithm of a likelihood ratio is equal to the difference of the log-likelihoods:
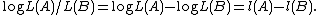
The log-likelihood is particularly convenient for maximum likelihood estimation. Because logarithms are strictly increasing functions, maximizing the likelihood is equivalent to maximizing the log-likelihood. The basic way to maximize a differentiable function is to find the stationary points (the points where the derivative is zero); since the derivative of a sum is just the sum of the derivatives, but the derivative of a product requires the product rule, it is easier to compute the stationary points of the log-likelihood of independent events than for the likelihood of independent events.
Just as the likelihood, given no event, being 1, the log-likelihood, given no event, is 0, which corresponds to the value of the empty sum: without any data, there is no support for any models.
Exponential families
{{details|Exponential family}}The log-likelihood is also particularly useful for exponential families of distributions, which include many of the common parametric probability distributions. The probability distribution function (and thus likelihood function) for exponential families contain products of factors involving exponentiation. The logarithm of such a function is a sum of products, again easier to differentiate than the original function.
An exponential family is one whose probability density function is of the form (for some functions, writing  for the inner product):
for the inner product):
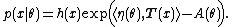
Each of these terms has an interpretation,{{efn|See {{slink|Exponential family|Interpretation}}}} but simply switching from probability to likelihood and taking logarithms yields the sum:

The  and
and  each correspond to a change of coordinates, so in these coordinates, the log-likelihood of an exponential family is given by the simple formula:
each correspond to a change of coordinates, so in these coordinates, the log-likelihood of an exponential family is given by the simple formula:

In words, the log-likelihood of an exponential family is inner product of the natural parameter {{tmath|\\boldsymbol\\eta}} and the sufficient statistic {{tmath|\\mathbf{T}(x)}}, minus the normalization factor (log-partition function) {{tmath|A({\\boldsymbol \\eta})}}. Thus for example the maximum likelihood estimate can be computed by taking derivatives of the sufficient statistic {{math|T}} and the log-partition function {{math|A}}.
Example: the gamma distribution
The gamma distribution is an exponential family with two parameters,  and
and 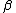 . The likelihood function is
. The likelihood function is

Finding the maximum likelihood estimate of for a single observed value looks rather daunting. Its logarithm is much simpler to work with:

To maximize the log-likelihood, we first take the partial derivative with respect to :

If there are a number of independent observations  , then the joint log-likelihood will be the sum of individual log-likelihoods, and the derivative of this sum will be a sum of derivatives of each individual log-likelihood:
, then the joint log-likelihood will be the sum of individual log-likelihoods, and the derivative of this sum will be a sum of derivatives of each individual log-likelihood:

To complete the maximization procedure for the joint log-likelihood, the equation is set to zero and solved for :

Here  denotes the maximum-likelihood estimate, and
denotes the maximum-likelihood estimate, and  is the sample mean of the observations.
is the sample mean of the observations.
Likelihood function of a parameterized model
Among many applications, we consider here one of broad theoretical and practical importance. Given a parameterized family of probability density functions (or probability mass functions in the case of discrete distributions)

where is the parameter, the likelihood function is
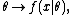
written

where is the observed outcome of an experiment. In other words, when  is viewed as a function of with fixed, it is a probability density function, and when viewed as a function of with fixed, it is a likelihood function.
is viewed as a function of with fixed, it is a probability density function, and when viewed as a function of with fixed, it is a likelihood function.
This is not the same as the probability that those parameters are the right ones, given the observed sample. Attempting to interpret the likelihood of a hypothesis given observed evidence as the probability of the hypothesis is a common error, with potentially disastrous consequences in medicine, engineering or jurisprudence. See prosecutor's fallacy for an example of this.
From a geometric standpoint, if we consider as a function of two variables then the family of probability distributions can be viewed as a family of curves parallel to the -axis, while the family of likelihood functions is the orthogonal curves parallel to the -axis.
Likelihoods for continuous distributions
The use of the probability density in specifying the likelihood function above is justified as follows. Given an observation  , the likelihood for the interval
, the likelihood for the interval  , where
, where  is a constant, is given by
is a constant, is given by  . Observe that
. Observe that  ,
,
since  is positive and constant. Because
is positive and constant. Because
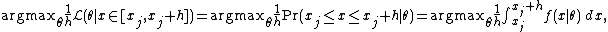
where 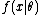 is the probability density function, it follows that
is the probability density function, it follows that
.
The first fundamental theorem of calculus and the l'Hôpital's rule together provide that
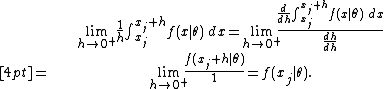
Then
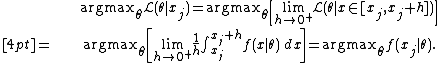
Therefore,

and so maximizing the probability density at amounts to maximizing the likelihood of the specific observation .
Likelihoods for mixed continuous–discrete distributions
The above can be extended in a simple way to allow consideration of distributions which contain both discrete and continuous components. Suppose that the distribution consists of a number of discrete probability masses  and a density , where the sum of all the 's added to the integral of is always one. Assuming that it is possible to distinguish an observation corresponding to one of the discrete probability masses from one which corresponds to the density component, the likelihood function for an observation from the continuous component can be dealt with in the manner shown above. For an observation from the discrete component, the likelihood function for an observation from the discrete component is simply
and a density , where the sum of all the 's added to the integral of is always one. Assuming that it is possible to distinguish an observation corresponding to one of the discrete probability masses from one which corresponds to the density component, the likelihood function for an observation from the continuous component can be dealt with in the manner shown above. For an observation from the discrete component, the likelihood function for an observation from the discrete component is simply
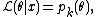
where  is the index of the discrete probability mass corresponding to observation , because maximizing the probability mass (or probability) at amounts to maximizing the likelihood of the specific observation.
is the index of the discrete probability mass corresponding to observation , because maximizing the probability mass (or probability) at amounts to maximizing the likelihood of the specific observation.
The fact that the likelihood function can be defined in a way that includes contributions that are not commensurate (the density and the probability mass) arises from the way in which the likelihood function is defined up to a constant of proportionality, where this "constant" can change with the observation , but not with the parameter .
Example 2
{{Main|German tank problem}}Consider a jar containing N lottery tickets numbered from 1 through N. If you pick a ticket randomly, then you get positive integer n, with probability 1/N if n ≤ N and with probability 0 if n > N. This can be written

where the Iverson bracket [n ≤ N] is 1 when n ≤ N and 0 otherwise.
When considered a function of n for fixed N, this is the probability distribution. When considered a function of N for fixed n, this is a likelihood function. The maximum likelihood estimate for N is n (by contrast, the unbiased estimate is 2n − 1).
This likelihood function is not a probability distribution for  . To see this, note that the total
. To see this, note that the total

is a divergent series, and so is  , not 1 as it would have to be if they were probabilities.
, not 1 as it would have to be if they were probabilities.
Suppose, however, that you pick two tickets (without replacement), rather than one. Then the probability of the outcome {n1, n2}, where n1 < n2, is

When considered a function of N for fixed n2, this is a likelihood function. The maximum likelihood estimate for N is n2. The total
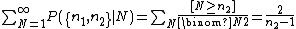
is a convergent series, and so this likelihood function can be normalized into a probability distribution.
If you pick 3 or more tickets, the likelihood function has a well defined mean value, which is larger than the maximum likelihood estimate. If you pick 4 or more tickets, the likelihood function has a well defined standard deviation too.
With 2 or more tickets, the probability distributions just derived match the results from a Bayesian analysis assuming an improper, uniform prior for N over all positive integers. The use of improper priors is often justified by saying that the information from the data dominates the information from the prior. If only a very few tickets are available, and a precise answer is important, this can justify the work of collecting relevant information from other sources to use as an informative prior.
Relative likelihood
Relative likelihood function
Suppose that the maximum likelihood estimate for the parameter {{mvar|θ}} is  . Relative plausibilities of other {{mvar|θ}} values may be found by comparing the likelihoods of those other values with the likelihood of . The relative likelihood of {{mvar|θ}} is defined to be[15][16][17][18][19]
. Relative plausibilities of other {{mvar|θ}} values may be found by comparing the likelihoods of those other values with the likelihood of . The relative likelihood of {{mvar|θ}} is defined to be[15][16][17][18][19]

Thus, the relative likelihood is the likelihood ratio (discussed above) with the fixed denominator  . This corresponds to normalizing the likelihood to have a maximum of 1.
. This corresponds to normalizing the likelihood to have a maximum of 1.
Likelihood region
A likelihood region is the set of all values of {{mvar|θ}} whose relative likelihood is greater than or equal to a given threshold. In terms of percentages, a {{mvar|p}}% likelihood region for {{mvar|θ}} is defined to be[15][17]

If {{mvar|θ}} is a single real parameter, a {{mvar|p}}% likelihood region will usually comprise an interval of real values. If the region does comprise an interval, then it is called a likelihood interval.[15][17][20]
Likelihood intervals, and more generally likelihood regions, are used for interval estimation within likelihoodist statistics: they are similar to confidence intervals in frequentist statistics and credible intervals in Bayesian statistics. Likelihood intervals are interpreted directly in terms of relative likelihood, not in terms of coverage probability (frequentism) or posterior probability (Bayesianism).
Given a model, likelihood intervals can be compared to confidence intervals. If {{mvar|θ}} is a single real parameter, then under certain conditions, a 14.65% likelihood interval (about 1:7 likelihood) for {{mvar|θ}} will be the same as a 95% confidence interval (19/20 coverage probability).[15] In a slightly different formulation suited to the use of log-likelihoods (see Wilks' theorem), the test statistic is twice the difference in log-likelihoods and the probability distribution of the test statistic is approximately a chi-squared distribution with degrees-of-freedom (df) equal to the difference in df's between the two models (therefore, the {{mvar|e}}−2 likelihood interval is the same as the 0.954 confidence interval; assuming difference in df's to be 1).[20]
Relative likelihood of models
The definition of relative likelihood can be generalized to compare different statistical models. This generalization is based on AIC (Akaike information criterion), or sometimes AICc (Akaike Information Criterion with correction).
Suppose that, for some dataset, we have two statistical models, {{math|M1}} and {{math|M2}}. Also suppose that {{math|AIC(M1 ) ≤ AIC(M2 )}}. Then the relative likelihood of {{math|M2}} with respect to {{math|M1}} is defined as follows.[21]
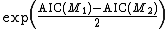
To see that this is a generalization of the earlier definition, suppose that we have some model {{math|M}} with a (possibly multivariate) parameter {{mvar|θ}}. Then for any {{mvar|θ}}, set {{math|M2 {{=}} M({{mvar|θ}})}}, and also set {{math|M1 {{=}} M(}}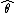 {{math|)}}. The general definition now gives the same result as the earlier definition.
{{math|)}}. The general definition now gives the same result as the earlier definition.
Likelihoods that eliminate nuisance parameters
In many cases, the likelihood is a function of more than one parameter but interest focuses on the estimation of only one, or at most a few of them, with the others being considered as nuisance parameters. Several alternative approaches have been developed to eliminate such nuisance parameters, so that a likelihood can be written as a function of only the parameter (or parameters) of interest: the main approaches are marginal, conditional, and profile likelihoods.[22][23]
These approaches are useful because standard likelihood methods can become unreliable or fail entirely when there are many nuisance parameters or when the nuisance parameters are high-dimensional. This is particularly true when the nuisance parameters can be considered to be "missing data"; they represent a non-negligible fraction of the number of observations and this fraction does not decrease when the sample size increases. Often these approaches can be used to derive closed-form formulae for statistical tests when direct use of maximum likelihood requires iterative numerical methods. These approaches find application in some specialized topics such as sequential analysis.
Conditional likelihood
Sometimes it is possible to find a sufficient statistic for the nuisance parameters, and conditioning on this statistic results in a likelihood which does not depend on the nuisance parameters.
One example occurs in 2×2 tables, where conditioning on all four marginal totals leads to a conditional likelihood based on the non-central hypergeometric distribution. This form of conditioning is also the basis for Fisher's exact test.
Marginal likelihood
{{Main|Marginal likelihood}}Sometimes we can remove the nuisance parameters by considering a likelihood based on only part of the information in the data, for example by using the set of ranks rather than the numerical values. Another example occurs in linear mixed models, where considering a likelihood for the residuals only after fitting the fixed effects leads to residual maximum likelihood estimation of the variance components.
Profile likelihood
When the likelihood function depends on many parameters, depending on the application, we might be interested in only a subset of these parameters. It is often possible to reduce the number of the uninteresting (nuisance) parameters by writing them as functions of the parameters of interest.[24][25][26] For example, the functions might be the value of the nuisance parameter which maximizes the likelihood given the value of the other (interesting) parameters.
This procedure is called concentration of the parameters and results in the concentrated likelihood function,[27] also occasionally known as the maximized likelihood function, but most often called the profile likelihood function. It is then possible (and simpler) to find the values of the parameters which maximizes the profile likelihood function (similar to the maximum likelihood).
For example, consider a regression analysis model with normally distributed errors. The most likely value of the error variance is the variance of the residuals. The residuals depend on all other parameters. Hence the variance parameter can be written as a function of the other parameters.
Unlike conditional and marginal likelihoods, profile likelihood methods can always be used, even when the profile likelihood cannot be written down explicitly. However, the profile likelihood is not a true likelihood, as it is not based directly on a probability distribution, and this leads to some less satisfactory properties. Attempts have been made to improve this, resulting in modified profile likelihood.{{citation needed|date=March 2016}}
The idea of profile likelihood can also be used to compute confidence intervals that often have better small-sample properties than those based on asymptotic standard errors calculated from the full likelihood. In the case of parameter estimation in partially observed systems, the profile likelihood can be also used for identifiability analysis.[28]
Results from profile likelihood analysis can be incorporated in uncertainty analysis of model predictions.[29]
Partial likelihood
A partial likelihood is an adaption of the full likelihood such that only a part of the parameters (the parameters of interest) occur in it.[30] It is a key component of the proportional hazards model: using a restriction on the hazard function, the likelihood does not contain the shape of the hazard over time.
Historical remarks
{{see also|History of statistics|History of probability}}The term "likelihood" has been in use in English since at least late Middle English.[31] Its formal use to refer to a specific function in mathematical statistics was proposed by Ronald Fisher,[32] in two research papers published in 1921[33] and 1922.[34] The 1921 paper introduced what is today called a "likelihood interval"; the 1922 paper introduced the term "method of maximum likelihood". Quoting Fisher:
[I]n 1922, I proposed the term ‘likelihood,’ in view of the fact that, with respect to [the parameter], it is not a probability, and does not obey the laws of probability, while at the same time it bears to the problem of rational choice among the possible values of [the parameter] a relation similar to that which probability bears to the problem of predicting events in games of chance. . . .Whereas, however, in relation to psychological judgment, likelihood has some resemblance to probability, the two concepts are wholly distinct. . . .”[35]
The concept of likelihood should not be confused with probability as mentioned by Sir Ronald Fisher "I stress this because in spite of the emphasis that I have always laid upon the difference between probability and likelihood there is still a tendency to treat likelihood as though it were a sort of probability. The first result is thus that there are two different measures of rational belief appropriate to different cases. Knowing the population we can express our incomplete knowledge of, or expectation of, the sample in terms of probability; knowing the sample we can express our incomplete knowledge of the population in terms of likelihood".[36] Fisher's invention of statistical likelihood was in reaction against an earlier form of reasoning called inverse probability.[37] His use of the term "likelihood" fixed the meaning of the term within mathematical statistics.
A. W. F. Edwards established the axiomatic basis for use of the log-likelihood ratio as a measure of relative support for one hypothesis against another.[38] The support function is then the natural logarithm of the likelihood function. Both terms are used in phylogenetics, but were not adopted in a general treatment of the topic of statistical evidence.[39]See also
{{Columns-list|colwidth=20em|- Bayes factor
- Conditional entropy
- Conditional probability
- Empirical likelihood
- Likelihood principle
- Likelihood-ratio test
- Likelihoodist statistics
- Maximum likelihood
- Principle of maximum entropy
- Pseudolikelihood
- Score (statistics)
}}
Notes
{{notelist}}References
2. ^The quotation is from §1.2 of the book. The wording of the quotation varies slightly among editions of the book; the wording presented here is from the last edition. The phrase "[lack of confidence]" is, in all editions of the book, "diffidence", the usual definition of which makes little sense in the context to modern readers. A rare/obsolete definition of "diffidence", though, is "lack of confidence" (see e.g. SOED), which makes excellent sense in the context. Ergo, the quotation is presented as here.
3. ^{{cite book |first=Patrick |last=Billingsley | author-link= Patrick Billingsley|title=Probability and Measure |publisher= John Wiley & Sons |edition=Third |year=1995 |pages=422–423 }}
4. ^{{cite book| first= Jun| last= Shao| year= 2003 | title= Mathematical Statistics | edition= 2nd | publisher= Springer | at= §4.4.1}}
5. ^1 2 3 I. J. Good: Probability and the Weighing of Evidence (Griffin 1950), §6.1
6. ^1 2 3 H. Jeffreys: Theory of Probability (3rd ed., Oxford University Press 1983), §1.22
7. ^1 2 3 4 E. T. Jaynes: Probability Theory: The Logic of Science (Cambridge University Press 2003), §4.1
8. ^1 2 3 D. V. Lindley: Introduction to Probability and Statistics from a Bayesian Viewpoint. Part 1: Probability (Cambridge University Press 1980), §1.6
9. ^1 2 3 A. Gelman, J. B. Carlin, H. S. Stern, D. B. Dunson, A. Vehtari, D. B. Rubin: Bayesian Data Analysis (3rd ed., Chapman & Hall/CRC 2014), §1.3
10. ^H. C. Sox, M. C. Higgins, D. K. Owens: Medical Decision Making (2nd ed., Wiley, 2013), http://doi.org/10.1002/9781118341544, chapters 3–4
11. ^{{Citation | first=H. |last=Akaike |authorlink=Hirotugu Akaike | contribution = Prediction and entropy | pages=1–24 | title= A Celebration of Statistics | editor1-first= A. C. | editor1-last= Atkinson | editor2-first= S. E. | editor2-last= Fienberg | editor2-link= Stephen Fienberg | year = 1985 | publisher= Springer}}.
12. ^{{Citation | author1-first= Y. | author1-last= Sakamoto | author2-first= M. | author2-last= Ishiguro | author3-first= G. | author3-last= Kitagawa | title= Akaike Information Criterion Statistics | year= 1986 | publisher= D. Reidel | at= Part I }}.
13. ^{{Citation |last=Burnham |first=K. P. |last2=Anderson |first2=D. R. |year=2002 |title=Model Selection and Multimodel Inference: A practical information-theoretic approach |edition=2nd |publisher= Springer-Verlag | at= chap. 7 }}.
14. ^{{cite journal |first1=Youngjo |last1=Lee |first2=John A. |last2=Nelder |authorlink2=John Nelder|journal=Statistics & Operations Research Transactions|title=Likelihood for random-effect models|volume=29 |number=2 |year=2005|p=143|quote=... log likelihood which we shall abbreviate to loglihood (a useful contraction which we owe to Michael Healy).}}
15. ^1 2 3 {{citation | author-link= James G. Kalbfleisch | last= Kalbfleisch | first= J. G. | year=1985 | title= Probability and Statistical Inference | publisher= Springer}} (§9.3).
16. ^{{citation| last= Azzalini | first= A. | title= Statistical Inference—Based on the likelihood | year= 1996 | publisher= Chapman & Hall | url= https://books.google.co.uk/books?id=hyN6gXHvSo0C | isbn= 9780412606502 }} (§1.4.2).
17. ^1 2 Sprott, D. A. (2000), Statistical Inference in Science, Springer (chap. 2).
18. ^Davison, A. C. (2008), Statistical Models, Cambridge University Press (§4.1.2).
19. ^{{citation|first1= L. | last1= Held | first2= D. S. | last2= Sabanés Bové | title= Applied Statistical Inference—Likelihood and Bayes | year= 2014 | publisher= Springer}} (§2.1).
20. ^1 {{Citation| last1 = Hudson | first1 = D. J.| title = Interval estimation from the likelihood function| journal = Journal of the Royal Statistical Society, Series B| volume = 33| issue = 2| pages = 256–262| doi = | year = 1971}}.
21. ^Burnham K. P. & Anderson D.R. (2002), Model Selection and Multimodel Inference: A practical information-theoretic approach, Springer (§2.8).
22. ^{{cite book | title=In All Likelihood: Statistical Modelling and Inference Using Likelihood | first=Yudi | last=Pawitan | year=2001| publisher=Oxford University Press|isbn=978-0-19-850765-9}}
23. ^{{cite web | author = Wen Hsiang Wei | url= http://web.thu.edu.tw/wenwei/www/glmpdfmargin.htm | title = Generalized Linear Model - course notes | pages = Chapter 5 | publisher = Tunghai University, Taichung, Taiwan | accessdate = 2017-10-01 }}
24. ^{{cite book |first=Takeshi |last=Amemiya |authorlink=Takeshi Amemiya |title=Advanced Econometrics |chapter=Concentrated Likelihood Function |location=Cambridge |publisher=Harvard University Press |year=1985 |pages=125–127 |isbn=978-0-674-00560-0 |chapterurl=https://books.google.com/books?id=0bzGQE14CwEC&pg=PA125 }}
25. ^{{cite book |first=Russell |last=Davidson |first2=James G. |last2=MacKinnon |authorlink2=James G. MacKinnon |title=Estimation and Inference in Econometrics |chapter=Concentrating the Loglikelihood Function |location=New York |publisher=Oxford University Press |year=1993 |pages=267–269 |isbn=978-0-19-506011-9 }}
26. ^{{cite book |first=Christian |last=Gourieroux |first2=Alain |last2=Monfort |title=Statistics and Econometric Models |chapter=Concentrated Likelihood Function |location=New York |publisher=Cambridge University Press |year=1995 |isbn=978-0-521-40551-5 |pages=170–175 |chapterurl=https://books.google.com/books?id=gqI-pAP2JZ8C&pg=PA170 }}
27. ^{{cite journal|last1=Montoya|first1=Jose A.|last2=Díaz-Francés|first2=Eloísa|last3=Sprott|first3=David A.|title=On a criticism of the profile likelihood function|journal=Statistical Papers|date=2009|volume=50|issue=1|pages=195–202|doi=10.1007/s00362-007-0056-5}}
28. ^{{cite journal |last = Raue |first = A |title = Structural and practical identifiability analysis of partially observed dynamical models by exploiting the profile likelihood |url = https://academic.oup.com/bioinformatics/article/25/15/1923/213246 |journal = Bioinformatics |year = 2009 |doi = 10.1093/bioinformatics/btp358 |pmid = 19505944 |last2 = Kreutz |first2 = C |last3 = Maiwald |first3 = T |last4 = Bachmann |first4 = J |last5 = Schilling |first5 = M |last6 = Klingmüller |first6 = U |last7 = Timmer |first7 = J |volume = 25 |issue = 15 |pages = 1923–29}}
29. ^{{cite journal |last=Vanlier |first=J |title=An integrated strategy for prediction uncertainty analysis |url=http://bioinformatics.oxfordjournals.org/content/28/8/1130.long |journal=Bioinformatics |year=2012 |doi=10.1093/bioinformatics/bts088 |pmid=22355081 |last2=Tiemann |first2=C |last3=Hilbers |first3=P |last4=van Riel |first4=N |volume=28 |issue=8 |pages=1130–35 |pmc=3324512}}
30. ^{{cite journal |last=Cox |first=D. R. |authorlink=David Cox (statistician) |title=Partial likelihood |journal=Biometrika |year=1975 |volume=62 |issue=2 |pages=269–276 |doi=10.1093/biomet/62.2.269 |mr=0400509}}
31. ^"likelihood", Shorter Oxford English Dictionary (2007).
32. ^{{Citation | title=On the history of maximum likelihood in relation to inverse probability and least squares| first= A. | last=Hald |authorlink=Anders Hald |journal=Statistical Science |volume= 14| issue=2 |year=1999 | pages =214–222 | doi=10.1214/ss/1009212248 | jstor = 2676741|url=http://projecteuclid.org/download/pdf_1/euclid.ss/1009212248}}.
33. ^{{citation | last=Fisher | first=R.A. |authorlink=Ronald Fisher | journal= Metron | title= On the "probable error" of a coefficient of correlation deduced from a small sample | volume=1 | year=1921 | pages=3–32}}.
34. ^{{citation | last=Fisher | first=R.A. |authorlink=Ronald Fisher | journal= Philosophical Transactions of the Royal Society A | title=On the mathematical foundations of theoretical statistics | volume=222 | issue=594–604 | year=1922 | pages=309–368 | url=http://digital.library.adelaide.edu.au/dspace/handle/2440/15172 | jstor=91208 | jfm = 48.1280.02 |doi=10.1098/rsta.1922.0009}}.
35. ^{{cite book |last=Klemens |first=Ben |title=Modeling with Data: Tools and Techniques for Scientific Computing |location= |publisher=Princeton University Press |year=2008 |page=329 }}
36. ^{{cite journal | last = Fisher | first = Ronald | title = Inverse Probability | year = 1930 | journal = Mathematical Proceedings of the Cambridge Philosophical Society | volume = 26 | issue = 4 | pages= 528–535 | doi = 10.1017/S0305004100016297 | url = https://www.cambridge.org/core/journals/mathematical-proceedings-of-the-cambridge-philosophical-society/article/inverse-probability/C9AB0A7C4566A3F9FCCEC489CA854814 }}
37. ^{{cite journal | last1 = Fienberg | first1 = Stephen E | year = 1997 | title = Introduction to R.A. Fisher on inverse probability and likelihood | url = https://projecteuclid.org/euclid.ss/1030037905 | journal = Statistical Science | volume = 12 | issue = 3| page = 161 | doi = 10.1214/ss/1030037905 }}
38. ^{{cite book |last=Edwards |first=A. W. F. |authorlink=A. W. F. Edwards |year=1972 |title=Likelihood |publisher=Cambridge University Press |isbn=978-0-8018-4443-0 |postscript=, (expanded edition, 1992, Johns Hopkins University Press).}}
39. ^{{cite book |last=Royall |first=R. |year=1997 |title=Statistical Evidence |location= |publisher=Chapman & Hall |isbn= }}
Further reading
- {{citation |first=A. W. F. |last=Edwards |authorlink=A. W. F. Edwards |title=The history of likelihood |journal= International Statistical Review |volume=42 |number=1 |year=1974 |pages=9–15 |doi=10.2307/1402681 |jstor=1402681}}
- {{citation| first1=D. A. S. |last1=Fraser | first2= P. | last2= McDunnough | first3= A. | last3= Naderi | first4= A. | last4= Plante | author1-link= Donald A. S. Fraser| title= On the definition of probability densities and sufficiency of the likelihood map | journal= Probability and Mathematical Statistics | volume=15 | page= 301–310| year= 1995| url= http://www.math.uni.wroc.pl/~pms/files/15/Article/15.21.pdf}}.
- {{citation | first= T. A. | last= Severini | title= Integrated likelihood functions for non-Bayesian inference | journal= Biometrika | volume= 94 | pages= 529–542 | year= 2007 | doi= 10.1093/biomet/asm040}}
External links
{{Wiktionary|likelihood}}- Likelihood function at Planetmath
- La Rochelle Confession
- La Rochelle, France
- La Rochelle - Ile de Re Airport
- La Rochelle – Île de Ré Airport
- La Rochepot
- La Roche sur Yon
- La Roche Sur Yon
- La Roche, Switzerland
- Larochette
- La Rochette
- La Rochette, Seine-et-Marne
- Laroche Wines
- La rochville university
- La Rochville university
- Larocilin
- LaRocque
- Larocque (surname)
- La Roda
- La Roda de Andalucía
- La Rogivue
- La Roldana
- La Romaine
- La Romaine Airport
- La Romaine, Quebec
- La Romana