- Data mining Structured fields Advantages
- Text-mining Principle Advantages
- Visualisations Data mining visualisation Text mining visualisation Visualisation for both data-mining and text-mining
- Uses
- See also
- References
Patent visualisation is an application of information visualisation. The number of patents has been increasing steadily,[1] thus forcing companies to consider intellectual property as a part of their strategy.[2] Patent visualisation, like patent mapping, is used to quickly view a patent portfolio.
Software dedicated to patent visualisation began to appear in 2000, for example Aureka from Aurigin (now owned by Thomson Reuters).[3] Many patent and portfolio analytics platforms, such as PatSnap, Patentcloud, Relecura, and Patent iNSIGHT Pro,[4] offer options to visualise specific data within patent documents by creating Topic Maps,[5] Priority Maps, IP Landscape reports,[6] etc. Software converts patents into infographics or maps, to allow the analyst to "get insight into the data" and draw conclusions.[7] Also called patinformatics,[8] it is the "science of analysing patent information to discover relationships and trends that would be difficult to see when working with patent documents on a one-and-one basis".{{Citation needed|date = January 2016}}
Patents contain structured data (like publication numbers) and unstructured text (like title, abstract, claims and visual info). Structured data are processed by data-mining and unstructured data are processed with text-mining.[9]
Data mining
The main step in processing structured information is data-mining,[10] which emerged in the late 1980s. Data mining involves statistics, artificial intelligence, and machine learning.[11] Patent data mining extracts information from the structured data of the patent document.[12] These structured data are bibliographic fields such as location, date or status.
Structured fields
| Structured data | Description | Business Intelligence use |
|---|---|---|
| Data | Patents contain identifying data including priority, publication data and the issue date.
| Crossing dates and locations fields offer a global vision of a technology in time and space. |
| Assignee | Patent assignees are organizations or individuals - the owners of the patent. | The field can offer a ranking of the principal actors of the environment, thus allowing us to visualise potential competitors or partners. |
| Inventor | Inventors develop the invention/patent. | Inventors' field combined with the assignee field can create a social network and provide a method to follow field experts. |
| Classification | The classification can regroup inventions with similar technologies. The most commonly used is the International Patent Classification (IPC). However, patent organizations have their own classification; for instance, the European Patent Office has framed the ECLA. | Grouping patents by theme offers an overview of the corpus and the potential applications of studied technology. |
| Status | The legal status indicates whether an application is filed, approved, or rejected. | Patent family and legal status searching is very important for litigation and competitive intelligence. |
Advantages
Data mining allows study of filing patterns of competitors and locates main patent filers within a specific area of technology. This approach can be helpful to monitor competitors' environments, moves and innovation trends and gives a macro view of a technology status.
Text-mining
Principle
Text mining is used to search through unstructured text documents.[13][14] This technique is widely used on the Internet, its success in bioinformatics and now in the intellectual property environment.[15]
Text mining is based on a statistical analysis of word recurrence in a corpus.[16] An algorithm extracts words and expressions from title, summary and claims and gathers them by declension. "And" and "if" are labeled as non-information bearing words and are stored in the stopword list. Stoplists can be specialized in order to create an accurate analysis. Next, the algorithm ranks the words by weight, according to their frequency in the patent's corpus and the document frequency containing this word. The score for each word is calculated using a formula such as:[17][18]
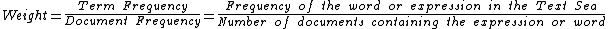
A frequently-used word in several documents has less weight than a word used frequently in a few patents. Words under a minimum weight are eliminated, leaving a list of pertinent words or descriptors. Each patent is associated to the descriptors found in the selected document. Further, in the process of clusterization, these descriptors are used as subsets, in which the patent are regrouped or as tags to place the patents in predetermined categories, for example keywords from International Patent Classifications.
Four text parts can be processed with text-mining :
- Title
- Abstract
- Claim
- Patent Full-Text
Software offer different combinations but title, abstract and claim are generally the most used, providing a good balance between interferences and relevancy.
Advantages
Text-mining can be used to narrow a search or quickly evaluate a patent corpus. For instance, if a query produces irrelevant documents, a multi-level clustering hierarchy identifies them in order to delete them and refine the search. Text-mining can also be used to create internal taxonomies specific to a corpus for possible mapping.
Visualisations
{{Further|Patent map}}Allying patent analysis and informatic tools offers an overview of the environment through value-added visualisations. As patents contain structured and unstructured information, visualisations fall in two categories. Structured data can be rendered with data mining in macrothematic maps and statistical analysis. Unstructured information can be shown in like clouds, cluster maps and 2D keyword maps.
Data mining visualisation
| Visualisation | Picture | Description | Business Intelligence use |
|---|---|---|---|
| Matrix chart | Picture | Graphic organizer used to summarize a multidimensional data set in a grid | Data comparison |
| Location map | Picture | Map with overlaid data values on geographic regions
| |
| Bar chart | Picture | Graph with rectangular bars proportional to the values that they represent, useful for numerical comparisons. | Data evolution |
| Line graph | Picture | Graph used to summarize how two parameters are related and how they vary. | Data evolution and relationships |
| Pie chart | Picture | Circular chart divided into sections, to illustrate proportions. | Data comparison |
| Bubble chart | Picture | 3-axis 2D chart which enables visualization similar to the Magic quadrant chart.
|
Text mining visualisation
| Visualisation | Description | Business Intelligence use |
|---|---|---|
| Tree list | Hierarchy list
| |
| Tag cloud | Full text of concepts. The size of each word is determined by its frequency in the corpus
| |
| 2D keyword map[19] | Tomographic map with quantitative representation of relief, usually using contour lines and colors. Distance on map is proportional to the difference between themes.[12]
| |
2D hierarchical cluster map with quantitative and qualitative representation of document set association to topic, usually using quantized cells and colors. Size of topic cells may represent patent count per topic relative to overall document set. Density and distribution inside of a topic cell may be proportional to document count relative to association to the topic and strength of association, respectively.
| ||
Text is decomposed into logical groupings and sub-groupings, then represented as a navigable hierarchy of those groupings by means of proportionate circle arcs.
|
Visualisation for both data-mining and text-mining
Mapping visualisations can be used for both text-mining and data-mining results.
| Visualisation | Picture | Description | Business Intelligence use |
|---|---|---|---|
| Tree Map | Picture | Visualization of hierarchical structures. Each data item, or row in the data set is represented by a rectangle, whose area is proportional to selected parameters.
| |
| Network map | Picture | In a network diagram, entities are connected to each other in the form of a node and link diagram.
| |
| Citation Map | Picture | In the citation map, the date of citation is visualized on the x axis and each individual citation takes an entry on the y axis. A strong vertical line indicates the filing date, showing which citations are cited by the patent as opposed to those which cite the patent.
|
Uses
What can patent visualisation highlight:[20][21]- Competitors
- Partners
- New innovations
- Technologic environment description[22]
- Networks
- R&D strategy management
- Competitive intelligence
- Licensing
- Strategy
See also
- Wiki Patent Information User Group : Review of Patent Analysis Tools
References
2. ^Kevin G. Rivette, David Kline, "Discovering new value in intellectual property", Harvard Business Review (January–February 2000)
3. ^ {{dead link|date=January 2016}}
4. ^{{cite web|url=http://www.intellogist.com/wiki/Patent_iNSIGHT_Pro|title=Patent iNSIGHT Pro|publisher=}}
5. ^Conduct patent portfolio analysis using comparative Topic Maps
6. ^Graphene Technology Insight Report
7. ^Daniel A Keim et IEEE Computer Society, "Information visualization and visual data mining," IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS 8 (2002): 1--8.
8. ^Anthony J. Trippe, "Patinformatics: Tasks to tools," World Patent Information 25, n°. 3 (September 2003): 211-221.
9. ^Laura Ruotsalainen, "Data mining tools for technology and competitive intelligence" VTT Research Notes 2451(October 2008)
10. ^ {{webarchive |url=https://web.archive.org/web/20100612094951/http://www.data-mining-software.com/data_mining_history.htm |date=June 12, 2010 }}
11. ^{{cite web|url=http://www.exforsys.com/tutorials/data-mining/how-data-mining-is-evolving.html|title=How Data Mining is Evolving|publisher=}}
12. ^1 Sungjoo Lee, Byungun Yoon, et Yongtae Park, "An approach to discovering new technology opportunities: Keyword-based patent map approach," Technovation 29, n°. 6 (Juin): 481-497.
13. ^ {{webarchive |url=https://web.archive.org/web/20101017010444/http://comminfo.rutgers.edu/~msharp/text_mining.htm |date=October 17, 2010 }}
14. ^{{cite journal| doi=10.1016/j.wpi.2009.05.008 | volume=32 | title=Review of the state-of-the-art in patent information and forthcoming evolutions in intelligent patent informatics | year=2010 | journal=World Patent Information | pages=30–38 | last1 = Bonino | first1 = Dario | last2 = Ciaramella | first2 = Alberto | last3 = Corno | first3 = Fulvio}}
15. ^Sholom Weiss and al, Text Mining : Predictive Methods for Analyzing Unstructured Information, 1er ed. (Springer 2004).
16. ^Antoine Blanchard "La cartographie des brevets" La Recherche n°.398 (2006) : 82-83
17. ^Gerard Salton et Christopher Buckley, "Term-weighting approaches in automatic text retrieval," Information Processing & Management 24, n°. 5 (1988): 513-523.
18. ^Y Kim, J Suh, et S Park, "Visualization of patent analysis for emerging technology," Expert Systems with Applications 34, no. 3 (4, 2008): 1804–1812.
19. ^{{cite web|url=http://www.infovis.net/printMag.php?num=160&lang=2 |accessdate=April 28, 2017 |deadurl=yes |archiveurl=https://web.archive.org/web/20100708040634/http://www.infovis.net/printMag.php?num=160&lang=2 | title=Newsmap|archivedate=July 8, 2010 }}
20. ^Miyake, M., Mune, Y. and Himeno, K. "Strategic Intellectual Property Portfolio Management: Technology Appraisal by Using the 'Technology Heat Map'", Nomura Research Institute (NRI) Papers, n°. 83, (December 2004).
21. ^1 Charles Boulakia "Patent mapping"
22. ^Richard Seymour, "Platinum Group Metals Patent Analysis and Mapping," Platinum Metals Review 52, n°. 4 (10, 2008): 231-240.
23. ^Susan E Cullen, "Introduction, From acorns to oak trees : how patent audits help innovations reach their full potential" IP Value 2010 - An International Guide for the Boardroom : 26--30
- Newtown (Powys) station
- Newtown Presbyterian Church
- Newtown, Queensland (Ipswich)
- Newtown railway station (disambiguation)
- Newtown R.F.C.
- Newtown RFC
- Newtown Road station
- New Towns Act (disambiguation)
- New towns in England
- New towns in Northern Ireland
- New towns in Scotland
- New towns in the united kingdom
- New towns in Wales
- New towns movement
- New towns of Singapore
- New Towns of Singapore
- Newtown Square
- Newtown Square Branch
- Newtown, Staffordshire
- Newtown St. Boswells
- Newtown, Stockton-on-Tees
- Newtown Township
- Newtown Township, Pennsylvania (disambiguation)
- Newtown Turnpike
- Newtown United F.C.