- Overview
- Linear model Ordinary least squares Weighted and generalized least squares
- Properties
- Blockwise formula
- See also
- References
In statistics, the projection matrix 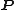 ,[1] sometimes also called the influence matrix[2] or hat matrix
,[1] sometimes also called the influence matrix[2] or hat matrix  , maps the vector of response values (dependent variable values) to the vector of fitted values (or predicted values). It describes the influence each response value has on each fitted value.[3][4] The diagonal elements of the projection matrix are the leverages, which describe the influence each response value has on the fitted value for that same observation.
, maps the vector of response values (dependent variable values) to the vector of fitted values (or predicted values). It describes the influence each response value has on each fitted value.[3][4] The diagonal elements of the projection matrix are the leverages, which describe the influence each response value has on the fitted value for that same observation.
Overview
If the vector of response values is denoted by  and the vector of fitted values by
and the vector of fitted values by 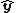 ,
,
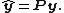
As is usually pronounced "y-hat", the projection matrix is also named hat matrix as it "puts a hat on ". The formula for the vector of residuals  can also be expressed compactly using the projection matrix:
can also be expressed compactly using the projection matrix:
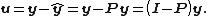
where  is the identity matrix. The matrix
is the identity matrix. The matrix 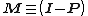 is sometimes referred to as the residual maker matrix. Moreover, the element in the ith row and jth column of is equal to the covariance between the jth response value and the ith fitted value, divided by the variance of the former:
is sometimes referred to as the residual maker matrix. Moreover, the element in the ith row and jth column of is equal to the covariance between the jth response value and the ith fitted value, divided by the variance of the former:
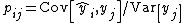
Therefore, the covariance matrix of the residuals , by error propagation, equals
,
where  is the covariance matrix of the error vector (and by extension, the response vector as well). For the case of linear models with independent and identically distributed errors in which
is the covariance matrix of the error vector (and by extension, the response vector as well). For the case of linear models with independent and identically distributed errors in which 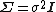 , this reduces to:[3]
, this reduces to:[3]
.
Linear model
Suppose that we wish to estimate a linear model using linear least squares. The model can be written as
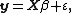
where X is a matrix of explanatory variables (the design matrix), β is a vector of unknown parameters to be estimated, and ε is the error vector.
Many types of models and techniques are subject to this formulation. A few examples are linear least squares, smoothing splines, regression splines, local regression, kernel regression, and linear filtering.
Ordinary least squares
{{further|Ordinary least squares}}When the weights for each observation are identical and the errors are uncorrelated, the estimated parameters are
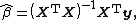
so the fitted values are
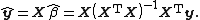
Therefore, the projection matrix (and hat matrix) is given by
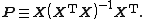
Weighted and generalized least squares
{{further|Weighted least squares|Generalized least squares}}The above may be generalized to the cases where the weights are not identical and/or the errors are correlated. Suppose that the covariance matrix of the errors is Ψ. Then since
.
the hat matrix is thus
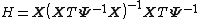
and again it may be seen that 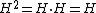 , though now it is no longer symmetric.
, though now it is no longer symmetric.
Properties
The projection matrix has a number of useful algebraic properties.[5][6] In the language of linear algebra, the projection matrix is the orthogonal projection onto the column space of the design matrix  .[4](Note that
.[4](Note that 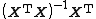 is the pseudoinverse of X.) Some facts of the projection matrix in this setting are summarized as follows:[4]
is the pseudoinverse of X.) Some facts of the projection matrix in this setting are summarized as follows:[4]
-
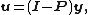 and
and 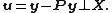
- is symmetric, and so is .
- is idempotent:
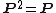 , and so is
, and so is  .
. - If is an {{nowrap|n × r}} matrix with
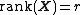 , then
, then 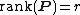
- The eigenvalues of consist of r ones and {{nowrap|n − r}} zeros, while the eigenvalues of consist of {{nowrap|n − r}} ones and r zeros.[7]
- is invariant under :
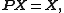 hence
hence 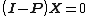 .
. -
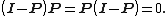
- is unique for certain subspace.
The projection matrix corresponding to a linear model is symmetric and idempotent, that is, . However, this is not always the case; in locally weighted scatterplot smoothing (LOESS), for example, the hat matrix is in general neither symmetric nor idempotent.
For linear models, the trace of the projection matrix is equal to the rank of , which is the number of independent parameters of the linear model. For other models such as LOESS that are still linear in the observations , the projection matrix can be used to define the effective degrees of freedom of the model.
Practical applications of the projection matrix in regression analysis include leverage and Cook's distance, which are concerned with identifying influential observations, i.e. observations which have a large effect on the results of a regression.
Blockwise formula
Suppose the design matrix 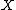 can be decomposed by columns as
can be decomposed by columns as 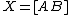 .
.
Define the hat or projection operator as 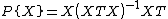 . Similarly, define the residual operator as
. Similarly, define the residual operator as 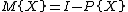 .
.
Then the projection matrix can be decomposed as follows:[8]
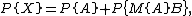
where, e.g., 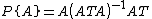 and
and  .
.
There are a number of applications of such a decomposition. In the classical application  is a column of all ones, which allows one to analyze the effects of adding an intercept term to a regression. Another use is in the fixed effects model, where is a large sparse matrix of the dummy variables for the fixed effect terms. One can use this partition to compute the hat matrix of without explicitly forming the matrix , which might be too large to fit into computer memory.
is a column of all ones, which allows one to analyze the effects of adding an intercept term to a regression. Another use is in the fixed effects model, where is a large sparse matrix of the dummy variables for the fixed effect terms. One can use this partition to compute the hat matrix of without explicitly forming the matrix , which might be too large to fit into computer memory.
See also
- Projection (linear algebra)
- Studentized residuals
- Effective degrees of freedom
- Mean and predicted response
References
2. ^{{cite web |title=Data Assimilation: Observation influence diagnostic of a data assimilation system |url=http://old.ecmwf.int/newsevents/training/lecture_notes/pdf_files/ASSIM/ObservationInfluence.pdf }}{{dead link|date=April 2018 |bot=InternetArchiveBot |fix-attempted=yes }}
3. ^1 {{Cite journal | title = The Hat Matrix in Regression and ANOVA| first1= David C. | last1= Hoaglin |first2= Roy E. | last2=Welsch |journal= The American Statistician | volume=32 |date=February 1978| pages=17–22 | doi = 10.2307/2683469 |issue=1| jstor = 2683469 |url=http://dspace.mit.edu/bitstream/1721.1/1920/1/SWP-0901-02752210.pdf }}
4. ^1 2 {{cite book |author=David A. Freedman |year=2009|title=Statistical Models: Theory and Practice |publisher=Cambridge University Press|quote= |page=}}
5. ^{{cite book |last=Gans |first=P. |year=1992 |title=Data Fitting in the Chemical Sciences |publisher=Wiley |isbn=0-471-93412-7 }}
6. ^{{cite book |last=Draper |first=N. R. |last2=Smith |first2=H. |year=1998 |title=Applied Regression Analysis |location= |publisher=Wiley |isbn=0-471-17082-8 }}
7. ^{{cite book |first=Takeshi |last=Amemiya |title=Advanced Econometrics |location=Cambridge |publisher=Harvard University Press |year=1985 |isbn=0-674-00560-0 |pages=460–461 |url=https://books.google.com/books?id=0bzGQE14CwEC&pg=PA460 }}
8. ^{{cite book|last1=Rao|first1=C. Radhakrishna|last2=Toutenburg|first2=Helge|author3=Shalabh|first4=Christian|last4=Heumann|title=Linear Models and Generalizations|year=2008|publisher=Springer|location=Berlin|isbn=978-3-540-74226-5|pages=323|edition=3rd}}
- Walkoffame.com
- Walk of Fame Philippines
- Walk-off hit
- Walk off the Earth
- Walk off the earth
- Walk Off the Earth
- Walk-off win
- Walk Of Life (song)
- Walk of My Life
- Walk of Punishment
- Walk of Shame (2013 film)
- Walk of shame (disambiguation)
- Walk of Shame (film)
- Walk Of Shame (P!nk song)
- Walk of Shame (song)
- Walk of the Stars
- Walk of the world
- Walkom
- Walk on Air
- Walk On (album)
- Walk On By (album)
- Walk On By (Burt Bacharach and Hal David song)
- Walk on By (song)
- Walk on Fire (album)
- Walk on Fire (film)