- Algorithm Pseudo Code Complexity
- Sampling the data Oversampling Bucket Size Estimate
- Many Identical Keys
- Uses in parallel systems
- Efficient Implementation of Samplesort Determining Buckets Partitioning
- In-Place Samplesort Local Classification Block Permutation Cleanup
- See also
- References
- External links
Samplesort is a sorting algorithm that is a divide and conquer algorithm often used in parallel processing systems.[1] Conventional divide and conquer sorting algorithms partitions the array into sub-intervals or buckets. The buckets are then sorted individually and then concatenated together. However, if the array is non-uniformly distributed, the performance of these sorting algorithms can be significantly throttled. Samplesort addresses this issue by selecting a sample of size s from the n-element sequence, and determining the range of the buckets by sorting the sample and choosing m -1 elements from the result. These elements (called splitters) then divide the sample into m equal-sized buckets.[2] Samplesort is described in the 1970 paper, "Samplesort: A Sampling Approach to Minimal Storage Tree Sorting", by W. D. Frazer and A. C. McKellar.
Algorithm
Samplesort is a generalization of quicksort. Where quicksort partitions its input into two parts at each step, based on a single value called the pivot, samplesort instead takes a larger sample from its input and divides its data into buckets accordingly. Like quicksort, it then recursively sorts the buckets.
To devise a samplesort implementation, one needs to decide on the number of buckets {{mvar|p}}. When this is done, the actual algorithm operates in three phases:{{r|hill}}
- Sample {{math|p−1}} elements from the input (the splitters). Sort these; each pair of adjacent splitters then defines a bucket.
- Loop over the data, placing each element in the appropriate bucket. (This may mean: send it to a processor, in a multiprocessor system.)
- Sort each of the buckets.
The full sorted output is the concatenation of the buckets.
A common strategy is to set {{mvar|p}} equal to the number of processors available. The data is then distributed among the processors, which perform the sorting of buckets using some other, sequential, sorting algorithm.
Pseudo Code
The following listing shows the above mentioned three step algorithm as pseudo code and shows how the algorithm works in principle.[3] In the following,  is the unsorted data,
is the unsorted data,  is the oversampling factor, discussed later, and
is the oversampling factor, discussed later, and  is the number of splitters.
is the number of splitters.

 // if average bucket size is below a threshold switch to e.g. quicksort
// if average bucket size is below a threshold switch to e.g. quicksort
 // select samples
// select samples
 // sort sample
// sort sample
 // select splitters
// select splitters




The pseudo code is different from the original Frazer and McKellar algorithm.[4] In the pseudo code, samplesort is called recursively. Frazer and McKellar called samplesort just once and used quicksort in all following iterations.
Complexity
The complexity, given in Big O notation:
Find the splitters.

Send to buckets.
for reading all nodes
for broadcasting
for binary search for all keys
to send keys to bucket
Sort buckets.
where
is the complexity of the underlying sequential sorting method[1]
The number of comparisons, performed by this algorithm, approaches the information theoretical optimum  for big input sequences. In experiments, conducted by Frazer and McKellar, the algorithm needed 15% less comparisons than quicksort.
for big input sequences. In experiments, conducted by Frazer and McKellar, the algorithm needed 15% less comparisons than quicksort.
Sampling the data
The data may be sampled through different methods. Some methods include:
- Pick evenly spaced samples.
- Pick randomly selected samples.
Oversampling
The oversampling ratio determines how many times more data elements to pull as samples, before determining the splitters. The goal is to get a good representation of the distribution of the data. If the data values are widely distributed, in that there are not many duplicate values, then a small sampling ratio is sufficient. In other cases where there are many duplicates in the distribution, a larger oversampling ratio will be necessary. In the ideal case, after step 2, each bucket contains 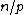 elements. In this case, no bucket takes longer to sort than the others, because all buckets are of equal size.
elements. In this case, no bucket takes longer to sort than the others, because all buckets are of equal size.
After pulling times more samples than necessary, the samples are sorted. Thereafter, the splitters used as bucket boundaries are the samples at position  of the sample sequence (together with
of the sample sequence (together with  and
and  as left and right boundaries for the left most and right most buckets respectively). This provides a better heuristic for good splitters than just selecting splitters randomly.
as left and right boundaries for the left most and right most buckets respectively). This provides a better heuristic for good splitters than just selecting splitters randomly.
Bucket Size Estimate
With the resulting sample size, the expected bucket size and especially the probability of a bucket exceeding a certain size can be estimated. The following will show that for an oversampling factor of  the probability that no bucket has more than
the probability that no bucket has more than  elements is larger than
elements is larger than  .
.
To show this let  be the input as a sorted sequence. For a processor to get more than
be the input as a sorted sequence. For a processor to get more than  elements, there has to exist a subsequence of the input of length , of which a maximum of
elements, there has to exist a subsequence of the input of length , of which a maximum of  samples are picked. These cases constitute the probability
samples are picked. These cases constitute the probability  . This can be represented as the random variable:
. This can be represented as the random variable:

For the expected value of  holds:
holds:

This will be used to estimate :

Using the chernoff bound now, it can be shown:

Many Identical Keys
In case of many identical keys, the algorithm goes through many recursion levels where sequences are sorted, because the whole sequence consists of identical keys. This can be counteracted by introducing equality buckets. Elements equal to a pivot are sorted into their respective equality bucket, which can be implemented with only one additional conditional branch. Equality buckets are not further sorted. This works, since keys occurring more than  times are likely to become pivots.
times are likely to become pivots.
Uses in parallel systems
Samplesort is often used in parallel systems, including distributed systems such as bulk synchronous parallel machines.[5][6][7] Due to the variable amount of splitters (in contrast to only one pivot in Quicksort), Samplesort is very well suited and intuitive for parallelization and scaling. Furthermore Samplesort is also more cache-efficient than implementations of e.g. quicksort.
Parallelization is implemented by splitting the sorting for each processor or node, where the number of buckets is equal to the number of processors . Samplesort is efficient in parallel systems because each processor receives approximately the same bucket size . Since the buckets are sorted concurrently, the processors will complete the sorting at approximately the same time, thus not having a processor wait for others.
On distributed systems, the splitters are chosen by taking elements on each processor, sorting the resulting  elements with a distributed sorting algorithm, taking every -th element and broadcasting the result to all processors. This costs
elements with a distributed sorting algorithm, taking every -th element and broadcasting the result to all processors. This costs  for sorting the elements on processors, as well as
for sorting the elements on processors, as well as  for distributing the chosen splitters to processors.
for distributing the chosen splitters to processors.
With the resulting splitters, each processor places its own input data into local buckets. This takes  with binary search. Thereafter, the local buckets are redistributed to the processors. Processor
with binary search. Thereafter, the local buckets are redistributed to the processors. Processor 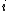 gets the local buckets
gets the local buckets  of all other processors and sorts these locally. The distribution takes
of all other processors and sorts these locally. The distribution takes  time, where
time, where  is the size of the biggest bucket. The local sorting takes
is the size of the biggest bucket. The local sorting takes  .
.
Experiments performed in the early 1990s on Connection Machine supercomputers showed samplesort to be particularly good at sorting large datasets on these machines, because its incurs little interprocessor communication overhead.[8] On latter-day GPUs, the algorithm may be less effective than its alternatives.[9]{{Citation needed|reason=The data are outdated in this paper since both GPU and CPU versions are much more efficient nowadays.|date=January 2018}}
Efficient Implementation of Samplesort
As described above, the samplesort algorithm splits the elements according to the selected splitters. An efficient implementation strategy is proposed in the paper "Super Scalar Sample Sort".[3] The implementation proposed in the paper uses two arrays of size  (the original array containing the input data and a temporary one) for an efficient implementation. Hence, this version of the implementation is not an in-place algorithm.
(the original array containing the input data and a temporary one) for an efficient implementation. Hence, this version of the implementation is not an in-place algorithm.
In each recursion step, the data gets copied to the other array in a partitioned fashion. If the data is in the temporary array in the last recursion step, then the data is copied back to the original array.
Determining Buckets
In a comparison based sorting algorithm the comparison operation is the most performance critical part. In Samplesort this corresponds to determining the bucket for each element. This needs  time for each element.
time for each element.
Super Scalar Sample Sort uses a balanced search tree which is implicitly stored in an array  . The root is stored at 0, the left successor of
. The root is stored at 0, the left successor of 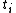 is stored at
is stored at  and the right successor is stored at
and the right successor is stored at  . Given the search tree , the algorithm calculates the bucket number
. Given the search tree , the algorithm calculates the bucket number  of element
of element  as follows (assuming
as follows (assuming  evaluates to 1 if it is true and 0 otherwise):
evaluates to 1 if it is true and 0 otherwise):




Since the number of buckets is known at compile time, this loop can be unrolled by the compiler. The comparison operation is implemented with predicated instructions. Thus, there occur no branch mispredictions, which would slow down the comparison operation significantly.
Partitioning
For an efficient partitioning of the elements, the algorithm needs to know the sizes of the buckets in advance. To partition the elements of the sequence and put them into the array, we need to know the size of the buckets in advance. A naive algorithm could count the number of elements of each bucket. Then the elements could be inserted to the other array at the right place. Using this, one has to determine the bucket for each elements twice (one time for counting the number of elements in a bucket, and one time for inserting them).
To avoid this doubling of comparisons, Super Scalar Sample Sort uses an additional array  (called oracle) which assigns each index of the elements to a bucket. First, the algorithm determines the contents of by determining the bucket for each element and the bucket sizes, and then placing the elements into the bucket determined by . The array also incurs cost in storage space, but as it only needs to store
(called oracle) which assigns each index of the elements to a bucket. First, the algorithm determines the contents of by determining the bucket for each element and the bucket sizes, and then placing the elements into the bucket determined by . The array also incurs cost in storage space, but as it only needs to store  bits, these cost are small compared to the space of the input array.
bits, these cost are small compared to the space of the input array.
In-Place Samplesort
A key disadvantage of the efficient Samplesort implementation shown above is that it is not in-place and requires a second temporary array of the same size as the input sequence during sorting. Efficient implementations of e.g. quicksort are in-place and thus more space efficient. However, Samplesort can be implemented in-place as well.[10]
The in-place algorithm is separated into four phases:
- Sampling which is equivalent to the sampling in the above mentioned efficient implementation.
- Local Classification on each processor, which groups the input into blocks such that all elements in each block belong to the same bucket, but buckets are not necessarily continuous in memory.
- Block permutation brings the blocks into the globally correct order.
- Cleanup moves some elements on the edges of the buckets.
One obvious disadvantage of this algorithm is that it reads and writes every element twice, once in the classification phase and once in the block permutation phase. However, the algorithm performs up to three times faster than other state of the art in-place competitors and up to 1.5 times faster than other state of the art sequential competitors. As sampling was already discussed above, the three later stages will be further detailed in the following.
Local Classification
In a first step, the input array is split up into stripes of blocks of equal size, one for each processor. Each processor additionally allocates buffers that are of equal size to the blocks, one for each bucket. Thereafter, each processor scans its stripe and moves the elements into the buffer of the according bucket. If a buffer is full, the buffer is written into the processors stripe, beginning at the front. There is always at least one buffer size of empty memory, because for a buffer to be written (i.e. buffer is full), at least a whole buffer size of elements more than elements written back had to be scanned. Thus, every full block contains elements of the same bucket. While scanning, the size of each bucket is kept track of.
Block Permutation
Firstly, a prefix sum operation is performed that calculates the boundaries of the buckets. However, since only full blocks are moved in this phase, the boundaries are rounded up to a multiple of the block size and a single overflow buffer is allocated. Before starting the block permutation, some empty blocks might have to be moved to the end of its bucket. Thereafter, a write pointer  is set to the start of the bucket subarray for each bucket and a read pointer
is set to the start of the bucket subarray for each bucket and a read pointer  is set to the last non empty block in the bucket subarray for each bucket.
is set to the last non empty block in the bucket subarray for each bucket.
To limit work contention, each processor is assigned a different primary bucket  and two swap buffers that can each hold a block. In each step, if both swap buffers are empty, the processor decrements the read pointer
and two swap buffers that can each hold a block. In each step, if both swap buffers are empty, the processor decrements the read pointer  of its primary bucket and reads the block at
of its primary bucket and reads the block at  and places it in one of its swap buffers. After determining the destination bucket
and places it in one of its swap buffers. After determining the destination bucket  of the block by classifying the first element of the block, it increases the write pointer
of the block by classifying the first element of the block, it increases the write pointer  , reads the block at
, reads the block at  into the other swap buffer and writes the block into its destination bucket. If
into the other swap buffer and writes the block into its destination bucket. If  , the swap buffers are empty again. Otherwise the block remaining in the swap buffers has to be inserted into its destination bucket.
, the swap buffers are empty again. Otherwise the block remaining in the swap buffers has to be inserted into its destination bucket.
If all blocks in the subarray of the primary bucket of a processor are in the correct bucket, the next bucket is chosen as the primary bucket. If a processor chose all buckets as primary bucket once, the processor is finished.
Cleanup
Since only whole blocks were moved in the block permutation phase, some elements might still be incorrectly placed around the bucket boundaries. Since there has to be enough space in the array for each element, those incorrectly placed elements can be moved to empty spaces from left to right, lastly considering the overflow buffer.
See also
- Flashsort
- Quicksort
References
2. ^{{cite web |url=http://parallelcomp.uw.hu/ch09lev1sec5.html |title=Bucket and Samplesort}}
3. ^1 {{cite book|last1=Sanders|first1=Peter|last2=Winkel|first2=Sebastian|title=Super Scalar Sample Sort|journal=Algorithms - ESA 2004|volume=3221|date=2004-09-14|issue=Lecture Notes in Computer Science|pages=784–796|doi=10.1007/978-3-540-30140-0_69|series=Lecture Notes in Computer Science|isbn=978-3-540-23025-0|citeseerx=10.1.1.68.9881}}
4. ^{{cite journal|last1=Frazer|first1=W. D.|last2=McKellar|first2=A. C.|title=Samplesort: A Sampling Approach to Minimal Storage Tree Sorting|journal=Journal of the ACM|date=1970-07-01|volume=17|issue=3|pages=496–507|doi=10.1145/321592.321600|url=http://dl.acm.org/citation.cfm?id=321592.321600|accessdate=2018-03-22}}
5. ^{{cite journal |first1=Alexandros V. |last1=Gerbessiotis |first2=Leslie G. |last2=Valiant |title=Direct Bulk-Synchronous Parallel Algorithms |year=1992 |journal=J. Parallel and Distributed Computing |volume=22 |pages=22–251 |citeseerx=10.1.1.51.9332}}
6. ^{{cite journal |first1=Jonathan M. D. |last1=Hill |first2=Bill |last2=McColl |first3=Dan C. |last3=Stefanescu |first4=Mark W. |last4=Goudreau |first5=Kevin |last5=Lang |first6=Satish B. |last6=Rao |first7=Torsten |last7=Suel |first8=Thanasis |last8=Tsantilas |first9=Rob H. |last9=Bisseling |title=BSPlib: The BSP Programming Library |journal=Parallel Computing |volume=24 |issue=14 |year=1998 |pages=1947–1980 |citeseerx=10.1.1.48.1862}}
7. ^{{cite conference |first1=William L. |last1=Hightower |first2=Jan F. |last2=Prins |first3=John H. |last3=Reif |year=1992 |title=Implementations of randomized sorting on large parallel machines |conference=ACM Symp. on Parallel Algorithms and Architectures |url=https://users.cs.duke.edu/~reif/paper/proteus/randsort.pdf}}
8. ^{{cite conference |title=A Comparison of Sorting Algorithms for the Connection Machine CM-2 |first1=Guy E. |last1=Blelloch |authorlink1=Guy Blelloch |first2=Charles E. |last2=Leiserson |authorlink2=Charles E. Leiserson |first3=Bruce M. |last3=Maggs |first4=C. Gregory |last4=Plaxton |first5=Stephen J. |last5=Smith |first6=Marco |last6=Zagha |conference=ACM Symp. on Parallel Algorithms and Architectures |year=1991 |url=https://www.cs.cmu.edu/~scandal/papers/cm-sort-SPAA91.html |citeseerx=10.1.1.131.1835}}
9. ^{{cite conference |first1=Nadathur |last1=Satish |first2=Mark |last2=Harris |first3=Michael |last3=Garland |title=Designing Efficient Sorting Algorithms for Manycore GPUs |conference=Proc. IEEE Int'l Parallel and Distributed Processing Symp. |citeseerx=10.1.1.190.9846}}
10. ^{{cite journal|last1=Axtmann|first1=Michael|last2=Witt|first2=Sascha|last3=Ferizovic|first3=Daniel|last4=Sanders|first4=Peter|title=In-Place Parallel Super Scalar Samplesort (IPSSSSo)|journal=25th Annual European Symposium on Algorithms (ESA 2017)|date=2017|volume=87|issue=Leibniz International Proceedings in Informatics (LIPIcs)|pages=9:1–9:14|doi=10.4230/LIPIcs.ESA.2017.9|url=http://drops.dagstuhl.de/opus/volltexte/2017/7854|accessdate=29 March 2018}}
External links
Frazer and McKellar's samplesort and derivatives:
- Frazer and McKellar's original paper
- http://www.springerlink.com/content/p70564506802n575/
- http://www.springerlink.com/content/l211p1q526j84174/
Adapted for use on parallel computers:
- http://citeseer.ist.psu.edu/91922.html
- http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.49.214
- Ellis, Stephen
- Ellis, Steuben County, Indiana
- Ellis, Steven
- Ellis Stouffer
- Elli Stamatiadou
- Ellis Thomas Davies
- Ellis Tinios
- El Listo
- Elliston and Southern Railroad
- Elliston Massacre
- Ellis unit
- Ellis Usher
- Ellis Verdi
- Ellis v. United States of America (1907)
- Ellis v. United States of America (1969)
- Ellis W. Carter
- Ellis William Davies
- Ellis wormhole
- Ellis W. Williamson
- Ellis, Xavier
- Ellis Zacharias
- El Litri
- El Litri y su sombra
- Elli von Kropiwnicki
- Elli Von Kropiwnicki