- See also
- References
- External links
A simple regression example has the independent variable appearing at a higher frequency than the dependent variable:
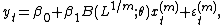
where y is the dependent variable, x is the regressor, m denotes the frequency – for instance if y is yearly 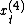 is quarterly –
is quarterly –  is the disturbance and
is the disturbance and 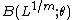 is a lag distribution, for instance the Beta function or the Almon Lag.
is a lag distribution, for instance the Beta function or the Almon Lag.
The regression models can be viewed in some cases as substitutes for the Kalman filter when applied in the context of mixed frequency data. Bai, Ghysels and Wright (2010) examine the relationship between MIDAS regressions and Kalman filter state space models applied to mixed frequency data. In general, the latter involve a system of equations, whereas in contrast MIDAS
regressions involve a (reduced form) single equation. As a consequence, MIDAS regressions might be less efficient, but also less prone to specification errors. In cases where the MIDAS regression is only an approximation, the approximation errors tend to be small.
See also
- Distributed lag
- ARMAX
References
2. ^Andreou, Elena & Eric Ghysels & Andros Kourtellos "Should macroeconomic forecasters use daily financial data and how?", Journal of Business and Economic Statistics 31, 240-251.
- Bai, J., Eric Ghysels and Jonathan Wright (2010), State Space Models and MIDAS Regressions, Discussion Paper UNC.
- Eric Ghysels, Sinko, A., Valkanov, R. (2007) MIDAS Regressions: Further Results and New Directions. Econometric Reviews, 26 (1), 53–90
External links
- Eric Ghysels
- [https://mpiktas.github.io/midasr// R code for midas regression models]
- Matlab code for midas regression models
- Thomas Scott (Manitoba)
- Thomas Scott (Manitoba politician)
- Thomas Scott (Ohio judge)
- Thomas Scott (poet)
- Thomas Scott (preacher)
- Thomas Scott Preston
- Thomas Scott Turnbull
- Thomas Scott William
- Thomas Scourfield
- Thomas scoville
- Thomas Scoville
- Thomas Scrimenti
- Thomas Scrope
- Thomas Scrope (disambiguation)
- Thomas S. Cullen
- Thomas Scully
- Thomas Scully (disambiguation)
- Thomas Sebastian Byrne
- Thomas Sedgwick
- Thomas Seeliger
- Thomas Seget
- Thomas Sehl
- Thomas Selby (cricketer, born 1791)
- Thomas Selby (disambiguation)
- Thomas Selby Egan