- Definitions
- Uniform convergence theorem
- Sauer–Shelah lemma
- Proof of uniform convergence theorem Symmetrization Permutations Reduction to a finite class
- References
Uniform convergence in probability is a form of convergence in probability in statistical asymptotic theory and probability theory. It means that, under certain conditions, the empirical frequencies of all events in a certain event-family converge to their theoretical probabilities. Uniform convergence in probability has applications to statistics as well as machine learning as part of statistical learning theory.
The law of large numbers says that, for each single event, its empirical frequency in a sequence of independent trials converges (with high probability) to its theoretical probability. But in some applications, we are interested not in a single event but in a whole family of events. We would like to know whether the empirical frequency of every event in the family converges to its theoretical probability simultaneously. The Uniform Convergence Theorem gives a sufficient condition for this convergence to hold. Roughly, if the event-family is sufficiently simple (its VC dimension is sufficiently small) then uniform convergence holds.
{{TOC limit|3}}Definitions
For a class of predicates  defined on a set
defined on a set 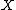 and a set of samples
and a set of samples  , where
, where 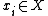 , the empirical frequency of
, the empirical frequency of  on
on  is
is

The theoretical probability of is defined as 
The Uniform Convergence Theorem states, roughly, that if is "simple" and we draw samples independently (with replacement) from according to any distribution  , then with high probability, the empirical frequency will be close to its expected value, which is the theoretical probability.
, then with high probability, the empirical frequency will be close to its expected value, which is the theoretical probability.
Here "simple" means that the Vapnik–Chervonenkis dimension of the class is small relative to the size of the sample. In other words, a sufficiently simple collection of functions behaves roughly the same on a small random sample as it does on the distribution as a whole.
The Uniform Convergence Theorem was first proved by Vapnik and Chervonenkis[1] using the concept of growth function.
Uniform convergence theorem
The statement of the uniform convergence theorem is as follows:[2]
If is a set of  -valued functions defined on a set and is a probability distribution on then for
-valued functions defined on a set and is a probability distribution on then for  and
and  a positive integer, we have:
a positive integer, we have:

where, for any,

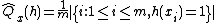
and.
indicates that the probability is taken over
is defined as: For any
,

And for any natural number , the shattering number 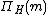 is defined as:
is defined as:

From the point of Learning Theory one can consider to be the Concept/Hypothesis class defined over the instance set . Before getting into the details of the proof of the theorem we will state Sauer's Lemma which we will need in our proof.
Sauer–Shelah lemma
The Sauer–Shelah lemma[3] relates the shattering number  to the VC Dimension.
to the VC Dimension.
Lemma:  , where
, where  is the VC Dimension of the concept class .
is the VC Dimension of the concept class .
Corollary: 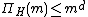 .
.
Proof of uniform convergence theorem
[1] and [2] are the sources of the proof below. Before we get into the details of the proof of the Uniform Convergence Theorem we will present a high level overview of the proof.
- Symmetrization: We transform the problem of analyzing
 into the problem of analyzing
into the problem of analyzing  , where
, where  and
and  are i.i.d samples of size drawn according to the distribution . One can view as the original randomly drawn sample of length , while may be thought as the testing sample which is used to estimate
are i.i.d samples of size drawn according to the distribution . One can view as the original randomly drawn sample of length , while may be thought as the testing sample which is used to estimate  .
. - Permutation: Since and are picked identically and independently, so swapping elements between them will not change the probability distribution on and . So, we will try to bound the probability of for some
 by considering the effect of a specific collection of permutations of the joint sample
by considering the effect of a specific collection of permutations of the joint sample 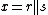 . Specifically, we consider permutations
. Specifically, we consider permutations 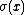 which swap
which swap  and
and  in some subset of
in some subset of  . The symbol
. The symbol 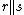 means the concatenation of and .
means the concatenation of and . - Reduction to a finite class: We can now restrict the function class to a fixed joint sample and hence, if has finite VC Dimension, it reduces to the problem to one involving a finite function class.
We present the technical details of the proof.
Symmetrization
Lemma: Let 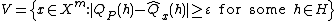 and
and

Then for  ,
,  .
.
Proof:
By the triangle inequality,
if 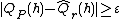 and
and  then
then  .
.
Therefore,

since and are independent.
Now for  fix an such that
fix an such that  . For this
. For this  , we shall show that
, we shall show that

Thus for any ,  and hence
and hence  . And hence we perform the first step of our high level idea.
. And hence we perform the first step of our high level idea.
Notice, 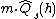 is a binomial random variable with expectation
is a binomial random variable with expectation  and variance
and variance  . By Chebyshev's inequality we get
. By Chebyshev's inequality we get
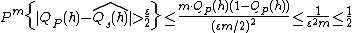
for the mentioned bound on . Here we use the fact that  for .
for .
Permutations
Let  be the set of all permutations of
be the set of all permutations of  that swaps
that swaps 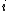 and
and 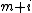
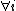 in some subset of
in some subset of  .
.
Lemma: Let  be any subset of
be any subset of  and any probability distribution on . Then,
and any probability distribution on . Then,
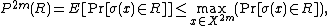
where the expectation is over chosen according to 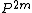 , and the probability is over
, and the probability is over  chosen uniformly from .
chosen uniformly from .
Proof:
For any 
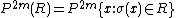
(since coordinate permutations preserve the product distribution .)

The maximum is guaranteed to exist since there is only a finite set of values that probability under a random permutation can take.
Reduction to a finite class
Lemma: Basing on the previous lemma,
.
Proof:
Let us define  and
and  which is at most
which is at most 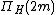 . This means there are functions
. This means there are functions  such that for any
such that for any  between
between  and
and  with
with 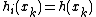 for
for 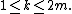
We see that 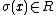 iff for some in satisfies,
iff for some in satisfies,
 .
.
Hence if we define  if
if  and
and  otherwise.
otherwise.
For  and
and 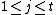 , we have that iff for some
, we have that iff for some  in
in  satisfies
satisfies 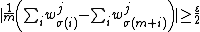 . By union bound we get
. By union bound we get


Since, the distribution over the permutations is uniform for each , so 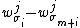 equals
equals  , with equal probability.
, with equal probability.
Thus,

where the probability on the right is over  and both the possibilities are equally likely. By Hoeffding's inequality, this is at most
and both the possibilities are equally likely. By Hoeffding's inequality, this is at most  .
.
Finally, combining all the three parts of the proof we get the Uniform Convergence Theorem.
References
2. ^1 [https://books.google.com/books?id=OiSJYwp4lzYC&dq=neural+network+learning+theoretical+foundations&printsec=frontcover&source=bn&hl=en&ei=kF32SZDNG8TgtgeXxpSfDw&sa=X&oi=book_result&ct=result&resnum=4 Martin Anthony Peter, l. Bartlett. Neural Network Learning: Theoretical Foundations, pages 46–50. First Edition, 1999. Cambridge University Press] {{ISBN|0-521-57353-X}}
3. ^Sham Kakade and Ambuj Tewari, CMSC 35900 (Spring 2008) Learning Theory, Lecture 11
- Broughton RUFC
- Broughton, Shropshire
- Broughton Skeog railway station
- Broughton (surname)
- Broughton, Thomas
- Broughton, Vale of Glamorgan
- Broughton, William
- Broughty
- Brough under Stainmore
- Brough with St. Giles
- Brough, Yell
- Brouhaha
- Broulidakis
- Broun Baronets
- Brouncker
- Brouncker, William
- Brounland, West Virginia
- Broun-Ramsay
- Broun, Richard
- Brousko
- Brousseau
- Brousse (cheese)
- Broussier
- Broussonetia secundiflora
- Brou's Underwing