- Formal definition
- Naive solution
- HyperLogLog algorithm
- Streaming algorithms Min/max sketches Bottom-m sketches
- Weighted count-distinct problem
- Solving the weighted count-distinct problem
- See also
- References
In computer science, the count-distinct problem[1]
(also known in applied mathematics as the cardinality estimation problem) is the problem of finding the number of distinct elements in a data stream with repeated elements.
This is a well-known problem with numerous applications. The elements might represent IP addresses of packets passing through a router, unique visitors to a web site, elements in a large database, motifs in a DNA sequence, or elements of RFID/sensor networks.
Formal definition
Instance: A stream of elementswith repetitions, and an integer
. Let
be the number of distinct elements, namely
, and let these elements be
.
Objective: Find an estimateof
.
An example of an instance for the cardinality estimation problem is the stream:  . For this instance,
. For this instance,  .
.
Naive solution
The naive solution to the problem is as follows:
Initialize a counter, {{mvar|c}}, to zero, {{nowrap| .}} Initialize an efficient dictionary data structure, {{mvar|D}}, such as hash table or search tree in which insertion and membership can be performed quickly. {{nowrap|For each element
.}} Initialize an efficient dictionary data structure, {{mvar|D}}, such as hash table or search tree in which insertion and membership can be performed quickly. {{nowrap|For each element  }}, a membership query is issued. {{nowrap|If is not a member of {{mvar|D}}}} {{nowrap|(
}}, a membership query is issued. {{nowrap|If is not a member of {{mvar|D}}}} {{nowrap|( )}} {{nowrap|Add to {{mvar|D}}}} Increase {{mvar|c}} by one, {{nowrap|
)}} {{nowrap|Add to {{mvar|D}}}} Increase {{mvar|c}} by one, {{nowrap| }} Otherwise {{nowrap|(
}} Otherwise {{nowrap|( )}} do nothing. {{nowrap|Output
)}} do nothing. {{nowrap|Output  .}}
.}}As long as the number of distinct elements is not too big, {{mvar|D}} fits in main memory and an exact answer can be retrieved.
However, this approach does not scale for bounded storage, or if the computation performed for each element should be minimized. In such a case, several streaming algorithms have been proposed that use a fixed number of storage units.
HyperLogLog algorithm
{{main|HyperLogLog}}Streaming algorithms
To handle the bounded storage constraint, streaming algorithms use a randomization to produce a non-exact estimation of the distinct number of elements, .
State-of-the-art estimators hash every element  into a low-dimensional data sketch using a hash function,
into a low-dimensional data sketch using a hash function,  .
.
The different techniques can be classified according to the data sketches they store.
Min/max sketches
Min/max sketches [2][3] store only the minimum/maximum hashed values. Examples of known min/max sketch estimators: Chassaing et al. [4] presents max sketch which is the minimum-variance unbiased estimator for the problem. The continuous max sketches estimator [5] is the maximum likelihood estimator. The estimator of choice in practice is the HyperLogLog algorithm.[6]
The intuition behind such estimators is that each sketch carries information about the desired quantity. For example, when every element is associated with a uniform RV, 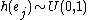 , the expected minimum value of
, the expected minimum value of  is
is  . The hash function guarantees that is identical for all the appearances of . Thus, the existence of duplicates does not affect the value of the extreme order statistics.
. The hash function guarantees that is identical for all the appearances of . Thus, the existence of duplicates does not affect the value of the extreme order statistics.
There are other estimation techniques other than min/max sketches. The first paper on count-distinct estimation by Flajolet et al. [7] describes a bit pattern sketch. In this case, the elements are hashed into a bit vector and the sketch holds the logical OR of all hashed values. The first asymptotically space- and time-optimal algorithm for this problem was given by Daniel M. Kane, Jelani Nelson, and David P. Woodruff.[8]
Bottom-m sketches
Bottom-m sketches
[9]are a generalization of min sketches, which maintain the minimal values, where  .
.
See Cosma et al.[2] for a theoretical overview of count-distinct estimation algorithms, and Metwally
[10]for a practical overview with comparative simulation results.
Weighted count-distinct problem
In its weighted version, each element is associated with a weight and the goal is to estimate the total sum of weights.
Formally,
Instance: A stream of weighted elementsbe the weight of
Objective: Find an estimateof
using only
An example of an instance for the weighted problem is: 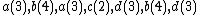 . For this instance,
. For this instance,  , the weights are
, the weights are  and
and  .
.
As an application example, could be IP packets received by a server. Each packet belongs to one of IP flows  . The weight can be the load imposed by flow on the server. Thus,
. The weight can be the load imposed by flow on the server. Thus,  represents the total load imposed on the server by all the flows to which packets belong.
represents the total load imposed on the server by all the flows to which packets belong.
Solving the weighted count-distinct problem
Any extreme order statistics estimator (min/max sketches) for the unweighted problem can be generalized to an estimator for the weighted problem
.[11]
For example, the weighted estimator proposed by Cohen et al.[5] can be obtained when the continuous max sketches estimator is extended to solve the weighted problem.
In particular, the HyperLogLog algorithm [6] can be extended to solve the weighted problem. The extended HyperLogLog algorithm offers the best performance, in terms of statistical accuracy and memory usage, among all the other known algorithms for the weighted problem.
See also
- Count–min sketch
- Streaming algorithm
- Maximum likelihood
- Minimum-variance unbiased estimator
References
2. ^1 {{cite journal | last1=Cosma | first1=Ioana A. | last2 = Clifford | first2 = Peter | year=2011 | title=A statistical analysis of probabilistic counting algorithms | journal=Scandinavian Journal of Statistics}}
3. ^{{cite book | last1=Giroire | first1=Frederic | title=2007 Proceedings of the Fourth Workshop on Analytic Algorithmics and Combinatorics (ANALCO) | pages=223–231 | last2 = Fusy | first2 = Eric | year=2007 |citeseerx=10.1.1.214.270 |doi=10.1137/1.9781611972979.9| isbn=978-1-61197-297-9 }}
4. ^{{cite journal | last1=Chassaing | first1=Philippe | last2=Gerin | first2=Lucas | year=2006| title=Efficient estimation of the cardinality of large data sets | journal=Proceedings of the 4th Colloquium on Mathematics and Computer Science| bibcode=2007math......1347C | arxiv=math/0701347 }}
5. ^1 {{cite journal | last1=Cohen | first1=Edith |authorlink=Edith Cohen| year=1997| title=Size-estimation framework with applications to transitive closure and reachability | journal=J. Comput. Syst. Sci.}}
6. ^1 {{cite journal | last1=Flajolet | first1=Philippe|author1-link=Philippe Flajolet | last2 = Fusy | first2 = Eric | last3=Gandouet | first3=Olivier | last4=Meunier | first4=Frederic | title=HyperLoglog: the analysis of a near-optimal cardinality estimation algorithm | journal=Analysis of Algorithms |year=2007}}
7. ^{{cite journal | last1=Flajolet | first1=Philippe|author1-link=Philippe Flajolet | last2 = Martin | first2 = G. Nigel | year=1985 | title=Probabilistic counting algorithms for data base applications | journal=J. Comput. Syst. Sci. }}
8. ^{{cite journal | last1=Kane | first1=Daniel M. | last2 = Nelson | first2 = Jelani | last3=Woodruff | first3=David P. | year=2010 | title=An Optimal Algorithm for the Distinct Elements Problem | journal=Proceedings of the 29th Annual ACM Symposium on Principles of Database Systems (PODS)}}
9. ^{{cite journal | last1=Cohen | first1=Edith|author1-link=Edith Cohen | last2 = Kaplan | first2 = Haim | year=2008 | title=Tighter estimation using bottom k sketches | journal=PVLDB | url=http://www.vldb.org/pvldb/1/1453884.pdf}}
10. ^{{Citation | last1=Metwally | first1=Ahmed | last2=Agrawal | first2=Divyakant | last3=Abbadi | first3= Amr El | year=2008 | title=Why go logarithmic if we can go linear?: Towards effective distinct counting of search traffic | series=Proceedings of the 11th international conference on Extending Database Technology: Advances in Database Technology }}
11. ^{{cite journal | last1=Cohen |author1-link=Edith Cohen| first1=Reuven | last2 = Katzir | first2 = Liran | last3=Yehezkel | first3=Aviv | year=2014| title=A Unified Scheme for Generalizing Cardinality Estimators to Sum Aggregation | journal=Information Processing Letters|doi=10.1016/j.ipl.2014.10.009 | volume=115 |issue=2| pages=336–342}}
- Collins, New York
- Collinson
- Collinsonia canadensis
- Collins Radio
- Collins Radio Company
- Collins River
- Collins Scrabble Words
- Collins Street
- Collins Street, Melbourne
- Collinston, LA
- Collinston, Louisiana
- Collinstown, North Carolina
- Collins Township, McLeod County, Minnesota
- Collins Township, MN
- Collinsville
- Collinsville, AL
- Collinsville, Alabama
- Collinsville, Connecticut
- Collinsville (CT)
- Collinsville, IL
- Collinsville, Illinois
- Collinsville, Mississippi
- Collinsville, MS
- Collinsville, OK
- Collinsville, Oklahoma