- Techniques
- Related concepts
- Prefix codes in use today Techniques
- Notes
- References
- External links
A prefix code is a type of code system (typically a variable-length code) distinguished by its possession of the "prefix property", which requires that there is no whole code word in the system that is a prefix (initial segment) of any other code word in the system. For example, a code with code words {9, 55} has the prefix property; a code consisting of {9, 5, 59, 55} does not, because "5" is a prefix of "59" and also of "55". A prefix code is a uniquely decodable code: given a complete and accurate sequence, a receiver can identify each word without requiring a special marker between words. However, there are uniquely decodable codes that are not prefix codes; for instance, the reverse of a prefix code is still uniquely decodable (it is a suffix code), but it is not necessarily a prefix code.
Prefix codes are also known as prefix-free codes, prefix condition codes and instantaneous codes. Although Huffman coding is just one of many algorithms for deriving prefix codes, prefix codes are also widely referred to as "Huffman codes", even when the code was not produced by a Huffman algorithm. The term comma-free code is sometimes also applied as a synonym for prefix-free codes[1][2] but in most mathematical books and articles (e.g.[3][4]) a comma-free code is used to mean a self-synchronizing code, a subclass of prefix codes.
Using prefix codes, a message can be transmitted as a sequence of concatenated code words, without any out-of-band markers or (alternatively) special markers between words to frame the words in the message. The recipient can decode the message unambiguously, by repeatedly finding and removing sequences that form valid code words. This is not generally possible with codes that lack the prefix property, for example {0, 1, 10, 11}: a receiver reading a "1" at the start of a code word would not know whether that was the complete code word "1", or merely the prefix of the code word "10" or "11"; so the string "10" could be interpreted either as a single codeword or as the concatenation of the words "1" then "0".
The variable-length Huffman codes, country calling codes, the country and publisher parts of ISBNs, the Secondary Synchronization Codes used in the UMTS W-CDMA 3G Wireless Standard, and the instruction sets (machine language) of most computer microarchitectures are prefix codes.
Prefix codes are not error-correcting codes. In practice, a message might first be compressed with a prefix code, and then encoded again with channel coding (including error correction) before transmission.
For any uniquely decodable code there is a prefix code that has the same code word lengths.[5] Kraft's inequality characterizes the sets of code word lengths that are possible in a uniquely decodable code.[6]
Techniques
If every word in the code has the same length, the code is called a fixed-length code, or a block code (though the term block code is also used for fixed-size error-correcting codes in channel coding). For example, ISO 8859-15 letters are always 8 bits long. UTF-32/UCS-4 letters are always 32 bits long. ATM cells are always 424 bits (53 bytes) long. A fixed-length code of fixed length k bits can encode up to 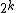 source symbols.
source symbols.
A fixed-length code is necessarily a prefix code. It is possible to turn any code into a fixed-length code by padding fixed symbols to the shorter prefixes in order to meet the length of the longest prefixes. Alternately, such padding codes may be employed to introduce redundancy that allows autocorrection and/or synchronisation. However, fixed length encodings are inefficient in situations where some words are much more likely to be transmitted than others.
Truncated binary encoding is a straightforward generalization of fixed-length codes to deal with cases where the number of symbols n is not a power of two. Source symbols are assigned codewords of length k and k+1, where k is chosen so that 2k < n ≤ 2k+1.
Huffman coding is a more sophisticated technique for constructing variable-length prefix codes. The Huffman coding algorithm takes as input the frequencies that the code words should have, and constructs a prefix code that minimizes the weighted average of the code word lengths. (This is closely related to minimizing the entropy.) This is a form of lossless data compression based on entropy encoding.
Some codes mark the end of a code word with a special "comma" symbol, different from normal data.[7] This is somewhat analogous to the spaces between words in a sentence; they mark where one word ends and another begins. If every code word ends in a comma, and the comma does not appear elsewhere in a code word, the code is automatically prefix-free. However, modern communication systems send everything as sequences of "1" and "0" – adding a third symbol would be expensive, and using it only at the ends of words would be inefficient. Morse code is an everyday example of a variable-length code with a comma. The long pauses between letters, and the even longer pauses between words, help people recognize where one letter (or word) ends, and the next begins. Similarly, Fibonacci coding uses a "11" to mark the end of every code word.
Self-synchronizing codes are prefix codes that allow frame synchronization.
Related concepts
A suffix code is a set of words none of which is a suffix of any other; equivalently, a set of words which are the reverse of a prefix code. As with a prefix code, the representation of a string as a concatenation of such words is unique. A bifix code is a set of words which is both a prefix and a suffix code.[8]
An optimal prefix code is a prefix code with minimal average length. That is, assume an alphabet of {{mvar|n}} symbols with probabilities 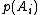 for a prefix code {{mvar|C}}. If {{mvar|C'}} is another prefix code and
for a prefix code {{mvar|C}}. If {{mvar|C'}} is another prefix code and  are the lengths of the codewords of {{mvar|C'}}, then
are the lengths of the codewords of {{mvar|C'}}, then 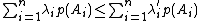 .[9]
.[9]
Prefix codes in use today
Examples of prefix codes include:
- variable-length Huffman codes
- country calling codes
- Chen–Ho encoding
- the country and publisher parts of ISBNs
- the Secondary Synchronization Codes used in the UMTS W-CDMA 3G Wireless Standard
- VCR Plus+ codes
- Unicode Transformation Format, in particular the UTF-8 system for encoding Unicode characters, which is both a prefix-free code and a self-synchronizing code[10]
Techniques
Commonly used techniques for constructing prefix codes include Huffman codes and the earlier Shannon-Fano codes, and universal codes such as:
- Elias delta coding
- Elias gamma coding
- Elias omega coding
- Fibonacci coding
- Levenshtein coding
- Unary coding
- Golomb Rice code
- Straddling checkerboard (simple cryptography technique which produces prefix codes)
- Vbinary coding[11]
Notes
2. ^{{citation|title=ATIS Telecom Glossary 2007|url=http://www.atis.org/glossary/definition.aspx?id=6416|accessdate=December 4, 2010}}
3. ^{{citation|last1=Berstel|first1=Jean|last2=Perrin|first2=Dominique|title=Theory of Codes|publisher=Academic Press|year=1985}}
4. ^{{citation|doi=10.4153/CJM-1958-023-9|last1=Golomb|first1=S. W.|author1-link=Solomon W. Golomb|last2=Gordon|first2=Basil|author2-link=Basil Gordon|last3=Welch|first3=L. R.|title=Comma-Free Codes|journal=Canadian Journal of Mathematics|volume=10|issue=2|pages=202–209|year=1958|url=https://books.google.com/books?id=oRgtS14oa-sC&pg=PA202}}
5. ^Le Boudec, Jean-Yves, Patrick Thiran, and Rüdiger Urbanke. Introduction aux sciences de l'information: entropie, compression, chiffrement et correction d'erreurs. PPUR Presses polytechniques, 2015.
6. ^Berstel et al (2010) p.75
7. ^"Development of Trigger and Control Systems for CMS" by J. A. Jones: "Synchronisation" p. 70
8. ^Berstel et al (2010) p.58
9. ^McGill COMP 423 Lecture notes
10. ^{{cite web | url = http://www.cl.cam.ac.uk/~mgk25/ucs/utf-8-history.txt | title = UTF-8 history | first = Rob | last = Pike | date = 2003-04-03}}
11. ^{{citation|doi=10.25209/2079-3316-2018-9-4-239-252|last1=Shevchuk|first1=Y. V.|author1-link=Yury V. Shevchuk|title=Vbinary: variable length integer coding revisited|journal=Program Systems: Theory and Applications|volume=9|issue=4|pages=239-252|year=2018|url=http://psta.psiras.ru//read/psta2018_4_239-252.pdf}}
References
- {{cite book | last1=Berstel | first1=Jean | last2=Perrin | first2=Dominique | last3=Reutenauer | first3=Christophe | title=Codes and automata | series=Encyclopedia of Mathematics and its Applications | volume=129 | location=Cambridge | publisher=Cambridge University Press | year=2010 | url=http://www-igm.univ-mlv.fr/~berstel/LivreCodes/Codes.html | isbn=978-0-521-88831-8 | zbl=1187.94001 }}
- {{cite journal | last=Elias | first=Peter | authorlink=Peter Elias | title=Universal codeword sets and representations of the integers | journal=IEEE Trans. Inf. Theory | volume=21 | number=2 | year=1975 | pages=194–203 | issn=0018-9448 | zbl=0298.94011 }}
- D.A. Huffman, "A method for the construction of minimum-redundancy codes", Proceedings of the I.R.E., Sept. 1952, pp. 1098–1102 (Huffman's original article)
- [https://web.archive.org/web/20070220234037/http://www.huffmancoding.com/david/scientific.html Profile: David A. Huffman], Scientific American, Sept. 1991, pp. 54–58 (Background story)
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, Second Edition. MIT Press and McGraw-Hill, 2001. {{ISBN|0-262-03293-7}}. Section 16.3, pp. 385–392.
- {{FS1037C}}
External links
- Codes, trees and the prefix property by Kona Macphee
- Daniel L. Haulman
- Daniel Librado Azcona
- Daniel Liczko
- Danielli-Davson model
- Daniel Liddle
- Daniel Lieberman
- Daniel Liebskind
- Daniel Lienert-Brown
- Daniel Liew
- Daniel Ligeti
- Daniel Liljenquist
- Daniel Lindemann
- Daniel Lind Lagerlof
- Daniel Lind Lagerlöf
- Daniel Lindley
- Daniel Lindsay
- Daniel Lissing
- Daniel Littlefield
- Daniel Littman
- Daniel Liwimbi
- Daniell, John
- Daniel Ljunggren
- Daniel Llambrich Gabriel
- Daniel L. LaRocque
- Daniel Lleufer Thomas