- 1 High-dimensional linear model
- 2 Generalized linear model
- References
1 High-dimensional linear model
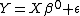
with  design matrix
design matrix 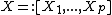 ( vectors
( vectors  ),
), 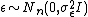 independent of
independent of 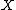 and unknown regression
and unknown regression 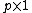 vector
vector 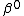 .
.
The usual method to find the parameter is by Lasso:
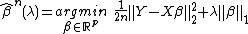
The de-sparsified lasso is a method modified from the Lasso estimator which fulfills the Karush-Kuhn-Tucker conditions[2] is as follows:
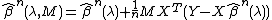
where 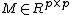 is an arbitrary matrix. The matrix
is an arbitrary matrix. The matrix 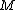 is generated using a surrogate inverse covariance matrix.
is generated using a surrogate inverse covariance matrix.
2 Generalized linear model
Desparsifying  -norm penalized estimators and corresponding theory can also be applied to models with convex loss functions such as generalized linear models.
-norm penalized estimators and corresponding theory can also be applied to models with convex loss functions such as generalized linear models.
Consider the following 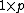 vectors of covariables
vectors of covariables 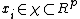 and univariate responses
and univariate responses  for
for 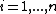
we have a loss function
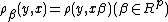
which is assumed to be strictly convex function in 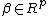
The -norm regularized estimator is
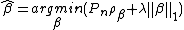
Similarly, the Lasso for node wise regression with matrix input is defined as follows:
Denote by 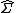 a matrix which we want to approximately invert using nodewise lasso.
a matrix which we want to approximately invert using nodewise lasso.
The de-sparsified -norm regularized estimator is as follows:
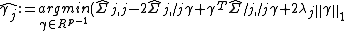
where 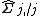 denotes the
denotes the  th row of without the diagonal element
th row of without the diagonal element 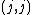 , and
, and 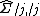 is the sub matrix without the th row and th column.
is the sub matrix without the th row and th column.
References
2. ^{{cite web|last1=Tibshirani|first1=Ryan|last2=Gordon|first2=Geoff|title=Karush-Kuhn-Tucker conditions|url=https://www.cs.cmu.edu/~ggordon/10725-F12/slides/16-kkt.pdf}}
- Robert Bidinotto
- Robert Bigelow
- Robert Birley
- Robert Bishop
- Robert Black (colonial administrator)
- Robert Blackwill
- Robert Blair
- Robert Blair (astronomer)
- Robert Blair (badminton)
- Robert Blair, judge
- Robert Blair Kaiser
- Robert Blair, Lord Avontoun
- Robert Blair (poet)
- Robert Blair (VC)
- Robert Blake
- Robert Blake, Actor
- Robert Blake (actor)
- Robert Blake (admiral)
- Robert Blake, Baron Blake
- Robert Blake (dentist)
- Robert Blake (management)
- Robert Blatchford
- Robert B. Laughlin
- Robert B. Leighton
- Robert B. Lindsay