- History
- Algorithms
- Architectures
- Theories Universal approximation capability Classification capability
- Neurons Real domain Complex domain
- Reliability
- Controversy
- Open sources
- See also
- References
Extreme learning machines are feedforward neural networks for classification, regression, clustering, sparse approximation, compression and feature learning with a single layer or multiple layers of hidden nodes, where the parameters of hidden nodes (not just the weights connecting inputs to hidden nodes) need not be tuned. These hidden nodes can be randomly assigned and never updated (i.e. they are random projection but with nonlinear transforms), or can be inherited from their ancestors without being changed. In most cases, the output weights of hidden nodes are usually learned in a single step, which essentially amounts to learning a linear model. The name "extreme learning machine" (ELM) was given to such models by its main inventor Guang-Bin Huang.
According to their creators, these models are able to produce good generalization performance and learn thousands of times faster than networks trained using backpropagation.[1] In literature, it also shows that these models can outperform support vector machines (SVM) and SVM provides suboptimal solutions in both classification and regression applications.[2][3][3]
History
From 2001-2010, ELM research mainly focused on the unified learning framework for "generalized" single-hidden layer feedforward neural networks (SLFNs), including but not limited to sigmoid networks, RBF networks, threshold networks[4], trigonometric networks, fuzzy inference systems, Fourier series[5][6], Laplacian transform, wavelet networks[7], etc. One significant achievements made in those years is to successfully prove the universal approximation and classification capabilities of ELM in theory[5][8][9].
From 2010 to 2015, ELM research extended to the unified learning framework for kernel learning, SVM and a few typical feature learning methods such as Principal Component Analysis (PCA) and Non-negative Matrix Factorization (NMF). It is shown that SVM actually provides suboptimal solutions compared to ELM, and ELM can provide the whitebox kernel mapping, which is implemented by ELM random feature mapping, instead of the blackbox kernel used in SVM. PCA and NMF can be considered as special cases where linear hidden nodes are used in ELM[10][11].
From 2015 onwards, an increased focus has been placed on hierarchical implementations[12][13] of ELM. Additionally since 2011, significant biological studies have been made that support certain ELM theories[14][15][16].
In a recent announcement from Google Scholar: "[https://scholar.googleblog.com/2017/06/classic-papers-articles-that-have-stood.html Classic Papers: Articles That Have Stood The Test of Time]", two ELM papers have been listed in the "[https://scholar.google.com/citations?view_op=list_classic_articles&hl=en&by=2006&vq=eng_artificialintelligence Top 10 in Artificial Intelligence for 2006]," taking positions 2 and 7.
Algorithms
Given a single hidden layer of ELM, suppose that the output function of the 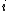 -th hidden node is
-th hidden node is 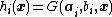 , where
, where  and
and  are the parameters of the -th hidden node. The output function of the ELM for SLFNs with
are the parameters of the -th hidden node. The output function of the ELM for SLFNs with  hidden nodes is:
hidden nodes is:
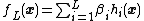 , where
, where 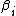 is the output weight of the -th hidden node.
is the output weight of the -th hidden node.
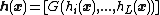 is the hidden layer output mapping of ELM. Given
is the hidden layer output mapping of ELM. Given  training samples, the hidden layer output matrix
training samples, the hidden layer output matrix  of ELM is given as:
of ELM is given as: 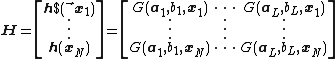
and  is the training data target matrix:
is the training data target matrix: 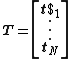
Generally speaking, ELM is a kind of regularization neural networks but with non-tuned hidden layer mappings (formed by either random hidden nodes, kernels or other implementations), its objective function is:
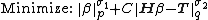
where 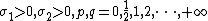 .
.
Different combinations of  ,
,  ,
,  and
and  can be used and result in different learning algorithms for regression, classification, sparse coding, compression, feature learning and clustering.
can be used and result in different learning algorithms for regression, classification, sparse coding, compression, feature learning and clustering.
As a special case, a simplest ELM training algorithm learns a model of the form (for single hidden layer sigmoid neural networks):
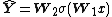
where {{math|W1}} is the matrix of input-to-hidden-layer weights,  is an activation function, and {{math|W2}} is the matrix of hidden-to-output-layer weights. The algorithm proceeds as follows:
is an activation function, and {{math|W2}} is the matrix of hidden-to-output-layer weights. The algorithm proceeds as follows:
- Fill {{math|W1}} with random values (e.g, Gaussian random noise);
- estimate {{math|W2}} by least-squares fit to a matrix of response variables {{math|Y}}, computed using the pseudoinverse {{math|⋅+}}, given a design matrix {{math|X}}:
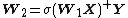
Architectures
In most cases, ELM is used as a single hidden layer feedforward network (SLFN) including but not limited to sigmoid networks, RBF networks, threshold networks, fuzzy inference networks, complex neural networks, wavelet networks, Fourier transform, Laplacian transform, etc. Due to its different learning algorithm implementations for regression, classification, sparse coding, compression, feature learning and clustering, multi ELMs have been used to form multi hidden layer networks, deep learning or hierarchical networks[12][13][21].
A hidden node in ELM is a computational elements, which need not be considered as classical neuron. A hidden node in ELM can be classical artificial neurons, basis functions, or a subnetwork formed by some hidden nodes.[8].
Theories
Both universal approximation and classification capabilities[2][3] have been proved for ELM in literature. Especially, Guang-Bin Huang and his team spent almost seven years (2001-2008) on the rigorous proofs of ELM's universal approximation capability[5][8][9].
Universal approximation capability
In theory, any nonconstant piecewise continuous function can be used as activation function in ELM hidden nodes, such an activation function need not be differential. If tuning the parameters of hidden nodes could make SLFNs approximate any target function  , then hidden node parameters can be randomly generated according to any continuous distribution probability, and
, then hidden node parameters can be randomly generated according to any continuous distribution probability, and 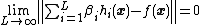 holds with probability one with appropriate output weights
holds with probability one with appropriate output weights 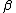 .
.
Classification capability
Given any nonconstant piecewise continuous function as the activation function in SLFNs, if tuning the parameters of hidden nodes can make SLFNs approximate any target function , then SLFNs with random hidden layer mapping 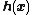 can separate arbitrary disjoint regions of any shapes.
can separate arbitrary disjoint regions of any shapes.
Neurons
Wide type of nonlinear piecewise continuous functions 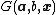 can be used in hidden neurons of ELM, for example:
can be used in hidden neurons of ELM, for example:
Real domain
Sigmoid function: 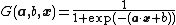
Fourier function: 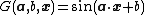
Hardlimit function: 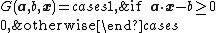
Gaussian function: 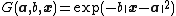
Multiquadrics function: 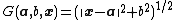
Wavelet: 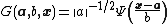 where
where  is a single mother wavelet function.
is a single mother wavelet function.
Complex domain
Circular functions:
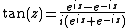
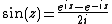
Inverse circular functions:
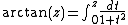
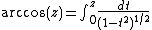
Hyperbolic functions:
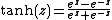
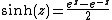
Inverse hyperbolic functions:
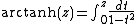

Reliability
{{see also|Explainable AI}}The black-box character of neural networks in general and extreme learning machines (ELM) in particular is one of the major concerns that repels engineers from application in unsafe automation tasks. This particular issue was approached by means of several different techniques. One approach is to reduce the dependence on the random input.[17][18] Another approach focuses on the incorporation of continuous constraints into the learning process of ELMs[19][20] which are derived from prior knowledge about the specific task. This is reasonable, because machine learning solutions have to guarantee a safe operation in many application domains. The mentioned studies revealed that the special form of ELMs, with its functional separation and the linear read-out weights, is particularly well suited for the efficient incorporation of continuous constraints in predefined regions of the input space.
Controversy
There are two main complaints from academic community concerning this work, the first one is about "reinventing and ignoring previous ideas", the second one is about "improper naming and popularizing", as shown in some debates in 2008 and 2015 [21]. In particular, it was pointed out in a letter[22] to the editor of IEEE Transactions on Neural Networks that the idea of using a hidden layer connected to the inputs by random untrained weights was already suggested in the original papers on RBF networks in the late 1980s; Guang-Bin Huang replied by pointing out subtle differences.[23] In a 2015 paper[3], Huang responded to complaints about his invention of the name ELM for already-existing methods, complaining of "very negative and unhelpful comments on ELM in neither academic nor professional manner due to various reasons and intentions" and an "irresponsible anonymous attack which intends to destroy harmony research environment", arguing that his work "provides a unifying learning platform" for various types of neural nets,[24] including hierarchical structured ELM.[25] In 2015, Huang also gave a formal rebuttal to what he considered as "malign and attack."[26] Recent research replaces the random weights with constrained random weights.[2][27]
Open sources
- Matlab Library
- Python Library[28]
See also
- Reservoir computing
- Random projection
- Random matrix
References
2. ^1 2 {{Cite journal|last=Huang|first=Guang-Bin; Hongming Zhou; Xiaojian Ding; and Rui Zhang|date=2012|title=Extreme Learning Machine for Regression and Multiclass Classification|url=http://www.ntu.edu.sg/home/egbhuang/pdf/ELM-Unified-Learning.pdf|journal=IEEE Transactions on Systems, Man and Cybernetics - Part B: Cybernetics|volume=42|issue=2|pages=513–529|via=|doi=10.1109/tsmcb.2011.2168604|pmid=21984515|citeseerx=10.1.1.298.1213}}
3. ^{{Cite journal|last=Huang|first=Guang-Bin|date=2014|title=An Insight into Extreme Learning Machines: Random Neurons, Random Features and Kernels|url=http://www.ntu.edu.sg/home/egbhuang/pdf/ELM-Randomness-Kernel.pdf|journal=Cognitive Computation|volume=6|issue=3|pages=376–390|via=|doi=10.1007/s12559-014-9255-2}}
4. ^{{Cite journal|last=Huang|first=Guang-Bin, Qin-Yu Zhu, K. Z. Mao, Chee-Kheong Siew, P. Saratchandran, and N. Sundararajan|date=2006|title=Can Threshold Networks Be Trained Directly?|url=http://www.ntu.edu.sg/home/egbhuang/pdf/TCASII-ELM-Threshold-Network.pdf|journal=IEEE Transactions on Circuits and Systems-II: Express Briefs|volume=53|issue=3|pages=187–191|via=|doi=10.1109/tcsii.2005.857540}}
5. ^1 2 {{Cite journal|last=Huang|first=Guang-Bin, Lei Chen, and Chee-Kheong Siew|date=2006|title=Universal Approximation Using Incremental Constructive Feedforward Networks with Random Hidden Nodes|url=http://www.ntu.edu.sg/home/egbhuang/pdf/I-ELM.pdf|journal=IEEE Transactions on Neural Networks|volume=17|issue=4|pages=879–892|via=|doi=10.1109/tnn.2006.875977|pmid=16856652}}
6. ^{{Cite journal|last=Rahimi|first=Ali, and Benjamin Recht|date=2008|title=Weighted Sums of Random Kitchen Sinks: Replacing Minimization with Randomization in Learning|url=https://people.eecs.berkeley.edu/~brecht/papers/08.rah.rec.nips.pdf|journal=Advances in Neural Information Processing Systems 21|volume=|pages=|via=}}
7. ^{{Cite journal|last=Cao|first=Jiuwen, Zhiping Lin, Guang-Bin Huang|title=Composite Function Wavelet Neural Networks with Extreme Learning Machine|journal=Neurocomputing|volume=73|issue=7–9|pages=1405–1416|doi=10.1016/j.neucom.2009.12.007|year=2010}}
8. ^1 2 {{Cite journal|last=Huang|first=Guang-Bin, Lei Chen|date=2007|title=Convex Incremental Extreme Learning Machine|url=http://www.ntu.edu.sg/home/egbhuang/pdf/CI-ELM.pdf|journal=Neurocomputing|volume=70|issue=16–18|pages=3056–3062|via=|doi=10.1016/j.neucom.2007.02.009}}
9. ^1 {{Cite journal|last=Huang|first=Guang-Bin, and Lei Chen|date=2008|title=Enhanced Random Search Based Incremental Extreme Learning Machine|url=http://www.ntu.edu.sg/home/egbhuang/pdf/EI-ELM.pdf|journal=Neurocomputing|volume=71|issue=16–18|pages=3460–3468|via=|doi=10.1016/j.neucom.2007.10.008|citeseerx=10.1.1.217.3009}}
10. ^{{Cite journal|last=He|first=Qing, Xin Jin, Changying Du, Fuzhen Zhuang, Zhongzhi Shi|date=2014|title=Clustering in Extreme Learning Machine Feature Space|url=http://www.intsci.ac.cn/users/jinxin/Mypapers/ELM-Neurocomputing-2013.pdf|journal=Neurocomputing|volume=128|pages=88–95|via=|doi=10.1016/j.neucom.2012.12.063}}
11. ^{{Cite journal|last=Kasun|first=Liyanaarachchi Lekamalage Chamara, Yan Yang, Guang-Bin Huang, and Zhengyou Zhang|date=2016|title=Dimension Reduction With Extreme Learning Machine|url=http://www.ntu.edu.sg/home/egbhuang/pdf/ELM-Dimensionality-Reduction.pdf|journal=IEEE Transactions on Image Processing|volume=25|issue=8|pages=3906–3918|via=|doi=10.1109/tip.2016.2570569|pmid=27214902}}
12. ^1 {{Cite journal|last=Huang|first=Guang-Bin, Zuo Bai, and Liyanaarachchi Lekamalage Chamara Kasun, and Chi Man Vong|date=2015|title=Local Receptive Fields Based Extreme Learning Machine|url=http://www.ntu.edu.sg/home/egbhuang/pdf/ELM-LRF.pdf|journal=IEEE Computational Intelligence Magazine|volume=10|issue=2|pages=18–29|via=|doi=10.1109/mci.2015.2405316}}
13. ^1 {{Cite journal|last=Tang|first=Jiexiong, Chenwei Deng, and Guang-Bin Huang|date=2016|title=Extreme Learning Machine for Multilayer Perceptron|url=http://www.ntu.edu.sg/home/egbhuang/pdf/Multiple-ELM.pdf|journal=IEEE Transactions on Neural Networks and Learning Systems|volume=27|issue=4|pages=809–821|via=|doi=10.1109/tnnls.2015.2424995|pmid=25966483}}
14. ^{{Cite journal|last=Barak|first=Omri; Rigotti, Mattia; and Fusi, Stefano|date=2013|title=The Sparseness of Mixed Selectivity Neurons Controls the Generalization-Discrimination Trade-off|journal=Journal of Neuroscience|volume=33|issue=9|pages=3844–3856|doi=10.1523/jneurosci.2753-12.2013|pmid=23447596|pmc=6119179}}
15. ^{{Cite journal|last=Rigotti|first=Mattia; Barak, Omri; Warden, Melissa R.; Wang, Xiao-Jing; Daw, Nathaniel D.; Miller, Earl K.; and Fusi, Stefano|date=2013|title=The Importance of Mixed Selectivity in Complex Cognitive Tasks|url=|journal=Nature|volume=497|issue=7451|pages=585–590|via=|doi=10.1038/nature12160|pmid=23685452|pmc=4412347}}
16. ^{{Cite journal|last=Fusi|first=Stefano, Earl K Miller and Mattia Rigotti|date=2015|title=Why Neurons Mix: High Dimensionality for Higher Cognition|url=http://www.ntu.edu.sg/home/egbhuang/pdf/Why-Neurons-Mix-ELM.pdf|journal=Current Opinion in Neurobiology|volume=37|pages=66–74|via=|doi=10.1016/j.conb.2016.01.010|pmid=26851755}}
17. ^{{Cite journal|last=Neumann|first=Klaus; Steil, Jochen J.|date=2011|title=Batch intrinsic plasticity for extreme learning machines|url=https://pub.uni-bielefeld.de/download/2141968/2904481|format=|journal=Proc. Of International Conference on Artificial Neural Networks|volume=|pages=339–346|via=}}
18. ^{{Cite journal|last=Neumann|first=Klaus; Steil, Jochen J.|date=2013|title=Optimizing extreme learning machines via ridge regression and batch intrinsic plasticity|url=https://pub.uni-bielefeld.de/download/2465823/2903542|format=|journal=Neurocomputing|volume=102|pages=23–30|via=|doi=10.1016/j.neucom.2012.01.041}}
19. ^{{Cite journal|last=Neumann|first=Klaus; Rolf, Matthias; Steil, Jochen J.|date=2013|title=Reliable integration of continuous constraints into extreme learning machines|journal=International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems|volume=21|issue=supp02|pages=35–50|doi=10.1142/S021848851340014X|issn=0218-4885}}
20. ^{{Cite book|url=https://pub.uni-bielefeld.de/download/2656403/2656405|title=Reliability|last=Neumann|first=Klaus|publisher=University Library Bielefeld|year=2014|isbn=|location=|pages=49–74}}
21. ^{{cite web |title=The Official Homepage on Origins of Extreme Learning Machines (ELM) |url=http://elmorigin.wixsite.com/originofelm |accessdate=15 December 2018}}
22. ^{{cite journal|last1=Wang|first1=Lipo P.|last2=Wan|first2=Chunru R.|title=Comments on "The Extreme Learning Machine"|journal=IEEE Trans. Neural Networks|citeseerx=10.1.1.217.2330}}
23. ^{{Cite journal|last=Huang|first=Guang-Bin|date=2008|title=Reply to "comments on 'the extreme learning machine' "|url=|journal=IEEE Transactions on Neural Networks|volume=19|issue=8|pages=1495–1496|via=|doi=10.1109/tnn.2008.2002275}}
24. ^1 2 3 {{cite journal |title=What are Extreme Learning Machines? Filling the Gap Between Frank Rosenblatt's Dream and John von Neumann's Puzzle |journal=Cognitive Computing |volume=7 |issue=3 |pages=263–278 |year=2015 |first=Guang-Bin |last=Huang |url=http://www.ntu.edu.sg/home/egbhuang/pdf/ELM-Rosenblatt-Neumann.pdf |doi=10.1007/s12559-015-9333-0}}
25. ^1 {{Cite book|last=Zhu|first=W.|last2=Miao|first2=J.|last3=Qing|first3=L.|last4=Huang|first4=G. B.|date=2015-07-01|title=Hierarchical Extreme Learning Machine for unsupervised representation learning|journal=2015 International Joint Conference on Neural Networks (IJCNN)|pages=1–8|doi=10.1109/IJCNN.2015.7280669|isbn=978-1-4799-1960-4}}
26. ^{{Cite web|url=http://www.ntu.edu.sg/home/egbhuang/pdf/Huang-GB-Statement.pdf|title=WHO behind the malign and attack on ELM, GOAL of the attack and ESSENCE of ELM|last=Guang-Bin|first=Huang|date=2015|website=www.extreme-learning-machines.org|archive-url=|archive-date=|dead-url=|access-date=}}
27. ^{{Cite book|last=Zhu|first=W.|last2=Miao|first2=J.|last3=Qing|first3=L.|date=2014-07-01|title=Constrained Extreme Learning Machine: A novel highly discriminative random feedforward neural network|journal=2014 International Joint Conference on Neural Networks (IJCNN)|pages=800–807|doi=10.1109/IJCNN.2014.6889761|isbn=978-1-4799-1484-5}}
28. ^{{Cite journal|last=Akusok|first=Anton; Bjork, Kaj-Mikael; Miche, Yoan; Lendasse, Amaury|date=2015|title=High-Performance Extreme Learning Machines: A Complete Toolbox for Big Data Applications|url=http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7140733|journal=IEEE Open Access|volume=3|pages=1011–1025|via=|doi=10.1109/access.2015.2450498}}
- United Nations Security Council Resolution 1452
- United Nations Security Council Resolution 1453
- United Nations Security Council Resolution 1454
- United Nations Security Council Resolution 1455
- United Nations Security Council Resolution 1456
- United Nations Security Council Resolution 1457
- United Nations Security Council Resolution 1458
- United Nations Security Council Resolution 1459
- United Nations Security Council Resolution 1460
- United Nations Security Council Resolution 1461
- United Nations Security Council Resolution 1462
- United Nations Security Council Resolution 1463
- United Nations Security Council Resolution 1464
- United Nations Security Council Resolution 1465
- United Nations Security Council Resolution 1466
- United Nations Security Council Resolution 1467
- United Nations Security Council Resolution 1468
- United Nations Security Council Resolution 1469
- United Nations Security Council Resolution 1470
- United Nations Security Council Resolution 1471
- United Nations Security Council Resolution 1472
- United Nations Security Council Resolution 1473
- United Nations Security Council Resolution 1474
- United Nations Security Council Resolution 1475
- United Nations Security Council Resolution 1476