- Method
- References
A common example that illustrates the concept behind this method is the frequency of the bigram "San Francisco". If it appears several times in a training corpus, the frequency of the unigram "Francisco" will also be high. Relying on only the unigram frequency to predict the frequencies of n-grams leads to skewed results;[3] however, Kneser–Ney smoothing corrects this by considering the frequency of the unigram in relation to possible words preceding it.
Method
Let  be the number of occurrences of the word
be the number of occurrences of the word  followed by the word
followed by the word 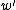 in the corpus.
in the corpus.
The equation for bigram probabilities is as follows:
 [4]
[4]Where the unigram probability  depends on how likely it is to see the word
depends on how likely it is to see the word  in an unfamiliar context, which is estimated as the number of times it appears after any other word divided by the number of distinct pairs of consecutive words in the corpus:
in an unfamiliar context, which is estimated as the number of times it appears after any other word divided by the number of distinct pairs of consecutive words in the corpus:

Please note that  is a proper distribution, as the values defined in above way are non-negative and sum to one.
is a proper distribution, as the values defined in above way are non-negative and sum to one.
The parameter  is a constant which denotes the discount value subtracted from the count of each n-gram, usually between 0 and 1.
is a constant which denotes the discount value subtracted from the count of each n-gram, usually between 0 and 1.
The value of the normalizing constant  is calculated to make the sum of conditional probabilities
is calculated to make the sum of conditional probabilities  over all equal to one.
over all equal to one.
Observe that (provided 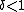 ) for each which occurs at least once in the context of
) for each which occurs at least once in the context of  in the corpus we discount the probability by exactly the same constant amount
in the corpus we discount the probability by exactly the same constant amount  ,
,
so the total discount depends linearly on the number of unique words that can occur after .
This total discount is a budget we can spread over all proportionally to .
As the values of sum to one, we can simply define to be equal to this total discount:

This equation can be extended to n-grams. Let  be the
be the  words before :
words before :
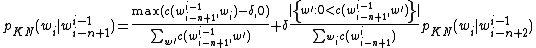 [5]
[5]This model uses the concept of absolute-discounting interpolation which incorporates information from higher and lower order language models. The addition of the term for lower order n-grams adds more weight to the overall probability when the count for the higher order n-grams is zero.[6] Similarly, the weight of the lower order model decreases when the count of the n-gram is non zero.
References
2. ^{{cite journal |last1=Ney |first1=Hermann |last2=Essen |first2=Ute |last3=Kneser |first3=Reinhard |title=On structuring probabilistic dependences in stochastic language modelling |journal=Computer Speech & Language |date=January 1994 |volume=8 |issue=1 |pages=1–38 |doi=10.1006/csla.1994.1001}}
3. ^'Brown University: Introduction to Computational Linguistics '
4. ^'Kneser Ney Smoothing Explained'
5. ^'NLP Tutorial: Smoothing'
6. ^'An empirical study of smoothing techniques for language modeling'
- Tillman Thomas
- Tillman Water Reclamation Plant
- Tillmitsch
- Till My Heartaches End
- Tillodont
- Tillodonta
- Tillodontia
- Tilloker
- Tilloloy
- Tillore
- Tillore Khurd
- Tillotama Shome
- Tillou
- 'Til Love Comes Again
- Tillowitz
- Tilloy
- Tilloy (disambiguation)
- Tilloy-et-Bellay
- Tilloy-Floriville
- Tilloy-les-Conty
- Tilloy-les-Hermaville
- Tilloy-les-Mofflaines
- Tilloy-Les-Mofflaines
- Tilloy-lez-Cambrai
- Tilloy-lez-Marchiennes