- Description
- Implementation details
- Operations Search Insert Delete
- Fault tolerance Random failure Adversarial failure
- References
Description
A skip graph is a distributed data structure based on skip lists designed to resemble a balanced search tree. They are one of several methods to implement a distributed hash table, which are used to locate resources stored in different locations across a network, given the name (or key) of the resource.
Skip graphs offer several benefits over other distributed hash table schemes such as Chord (peer-to-peer) and Tapestry (DHT), including addition and deletion in expected logarithmic time, logarithmic space per resource to store indexing information, no required knowledge of the number of nodes in a set and support for complex range queries. A major distinction from Chord and Tapestry is that there is no hashing of search keys of resources, which allows related resources to be near each other in the skip graph; this property makes searches for values within a given range feasible. Another strength of skip graphs is the resilience to node failure in both random and adversarial failure models.
Implementation details
As with skip lists, nodes are arranged in increasing order in multiple levels; each node in level i is contained in level i+1 with some probability p (an adjustable parameter).
Level 0 consists of one doubly linked list containing all of the nodes in the set. Lists becoming increasingly sparse at higher levels, until the list is composed of just one node. Where skip graphs differ from skip lists is that each level i≥1, will contain multiple lists; membership of a key x in a list is defined by the membership vector {{tmath|m(x)}}. The membership vector is defined as an infinite random word over a fixed alphabet, each list in the skip graph is identified by a finite word w from the same alphabet, if that word is a prefix of {{tmath|m(x)}} then node x is a member of the list.[1]
Operations
Skip graphs support the basic operations of search, insert and delete. Skip graphs will also support the more complex range search operation.
Search
The search algorithm for skip graphs is almost identical to the search algorithm for skip lists but it is modified to run in a distributed system. Searches start at the top level and traverse through the structure. At each level, the search traverses the list until the next node contains a greater key. When a greater key is found, the search drops to the next level, continuing until the key is found or it is determined that the key is not contained in the set of nodes. If the key is not contained in the set of nodes the largest value less than the search key is returned.
Each node in a list has the following fields:
- {{code|key}}
The node's value.
- {{code|neighbor[R/L][level]}}
An array containing pointers to the right and left neighbor in the node's doubly linked at level i.
search(searchOp, startNode, searchKey, level) '''if''' (v.key = searchKey) '''then''' '''send'''(foundOp, v) to startNode '''if''' (v.key < searchKey) '''then''' '''while''' level ≥ 0 '''if''' (v.neighbor[R][level].key ≤ searchKey) '''then''' '''send'''(searchOp, startNode, searchKey, level) to v.neighbor[R][level] '''break''' '''else''' level = level - 1 '''else''' '''while''' level ≥ 0 '''if''' ((v.neighbor[L][level]).key ≥ searchKey) '''then''' '''send'''(searchOp, startNode, searchKey, level) to v.neighbor[L][level] '''break''' '''else''' level = level - 1 '''if''' (level < 0) '''then''' '''send'''(notFoundOp, v) to startNode
Analysis performed by William Pugh shows that on average, a skip list and by extension a skip graph contains  levels for a fixed value of {{mvar|p}}.[2] Given that at most
levels for a fixed value of {{mvar|p}}.[2] Given that at most  nodes are searched on average per level, the total expected number of messages sent is
nodes are searched on average per level, the total expected number of messages sent is 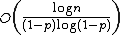 and the expected time for the search is .[1] Therefore, for a fixed value of {{mvar|p}}, the search operation is expected to take {{math|O(log n)}} time using {{math|O(log n)}} messages.[1]
and the expected time for the search is .[1] Therefore, for a fixed value of {{mvar|p}}, the search operation is expected to take {{math|O(log n)}} time using {{math|O(log n)}} messages.[1]
Insert
Insertion is done in two phases and requires that a new node {{mvar|u}} knows some introducing node {{mvar|v}}; the introducing node may be any other node currently in the skip graph. In the first phase the new node {{mvar|u}} uses the introducing node {{mvar|v}} to search for its own key; this search is expected to fail and return the node {{mvar|s}} with the largest key smaller than {{mvar|u}}. In the second phase {{mvar|u}} inserts itself in each level until it is the only element in a list at the top level.[1] Insertion at each level is performed using standard doubly linked list operations; the left neighbor's next pointer is changed to point to the new node and the right neighbor's previous pointer is changed to point to the node.
insert() search for {{var|s}} {{var|L}} = 0 '''while''' true insert {{var|u}} into level L from {{var|s}} Scan through level {{var|L}} to find {{var|s'}} such which has membership vector matching membership vector of {{var|u}} for first {{var|L}}+1 characters '''if''' no {{var|s'}} exists exit '''else''' {{var|s}} = {{var|s'}} {{var|L}} = {{var|L}} + 1Similar to the search, the insert operation takes expected O(log n) messages and O(log n) time. With a fixed value of p; the search operation in phase 1 is expected to take O(log n) time and messages. In phase 2 at each level L ≥ 0, {{mvar|u}} communicates with an average 1/p other nodes to locate {{mvar|s}}', this will require O(1/p) time and messages leading to O(1) time and messages for each step in phase 2.[1]
Delete
Nodes may be deleted in parallel at each level in O(1) time and O(log n) messages.[1] When a node wishes to leave the graph it must send messages to its immediate neighbors to rearrange their next and previous pointers.[1]
delete() '''for''' L = 1 to max level, in parallel '''delete''' ''u'' from each level. '''delete''' ''u'' from level 0
The skip graph contains an average of O(log n) levels; at each level u must send 2 messages to complete a delete operation on a doubly linked list. As operations on each level may be done in parallel the delete operation may be finished using O(1) time and expected O(log n) messages.
Fault tolerance
In skip graphs, fault tolerance describes the number of nodes which can be disconnected from the skip graph by failures of other nodes.[1] Two failure models have been examined; random failures and adversarial failures. In the random failure model any node may fail independently from any other node with some probability. The adversarial model assumes node failures are planned such that the worst possible failure is achieved at each step, the entire skip graph structure is known and failures are chosen to maximize node disconnection. A drawback of skip graphs is that there is no repair mechanism; currently the only way to remove and to repair a skip graph is to build a new skip graph with surviving nodes.
Random failure
Skip graphs are highly resistant to random failures. By maintaining information on the state of neighbors and using redundant links to avoid failed neighbors, normal operations can continue even with a large number of node failures. While the number of failed nodes is less than 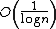 the skip graph can continue to function normally.[1] Simulations performed by James Aspnes show that a skip graph with 131072 nodes was able tolerate up to 60% of its nodes failing before surviving nodes were isolated.[1] While other distributed data structures may be able to achieve higher levels of resiliency they tend to be much more complex.
the skip graph can continue to function normally.[1] Simulations performed by James Aspnes show that a skip graph with 131072 nodes was able tolerate up to 60% of its nodes failing before surviving nodes were isolated.[1] While other distributed data structures may be able to achieve higher levels of resiliency they tend to be much more complex.
Adversarial failure
Adversarial failure is difficult to simulate in a large network as it becomes difficult to find worst case failure patterns.[1] Theoretical analysis shows that the resilience depends based on the vertex expansion ratio of the graph, defined as follows. For a set of nodes A in the graph G, the expansion factor is the number of nodes not in A but adjacent to a node in A divided by the number of nodes in A. If skip graphs have a sufficiently large expansion ratio of 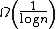 then at most {{tmath|O(f \\log n)}} nodes may be separated, even if up to f failures are specifically targeted.[1]
then at most {{tmath|O(f \\log n)}} nodes may be separated, even if up to f failures are specifically targeted.[1]
References
2. ^{{cite web | location = http://web.stanford.edu/class/cs161/skiplists.pdf | title = Skip Lists: A probabilistic Alternative to Balanced Trees | author = "William Pugh" | url = "http://web.stanford.edu/class/cs161/skiplists.pdf"}}
- Mesocyclogenesis
- Mesocyclolysis
- Mesocyclone detection algorithm
- Mesocyclones
- Mesocyparis
- Mesodapedon
- Mesodapedon kuttyi
- Mesodema
- Mesoderma laminae lateralis
- Mesodermal dysgenesis of cornea
- Mesodermochelys undulatus
- Mesodernochelys
- Mesodesma
- Mesodetra
- Mesodica
- Mesodica aggerata
- Mesodica dryas
- Mesodica infuscata
- Mesodineutes
- Mesodineutes amurensis
- Mesodinium chamaeleon
- Mesodinium rubrum
- Mesodiphlebia
- Mesodiphlebia crassivenia
- Mesodiphlebia merilesella