数据处理data processing
对获得大量的试验数据进行科学整理和分析,从中提取有用信息的过程。根据农机试验鉴定中所测得的数据的性质可分为静态(包括稳态)试验数据和动态试验数据。静态试验数据所表征的被测参量真值不随时间变化,可以用静态测量仪器进行测量,并直接从仪器上读取和记录所得的数据。如拖拉机机组的重心,物料的重量,试件在静载荷作用下某测点的应变等数据都属于静态数据。动态试验数据所表征的被测参量本身是随时间变化的量,需要用动态测量仪器与记录器配合连续记录所测得的数据。如拖拉机的牵引力,农机构件的随机振动,旋转轴的扭矩,管道的动压力及农机作业质量如耕深稳定性、排种的均匀性等数据都属动态试验数据。两类数据的性质不同,处理的方法也不同。静态数据处理是根据误差理论来估计和消除测量误差的影响,确定被测参量的真值及其测量误差的范围。动态试验数据处理是根据数理统计的方法分别在幅值阈、时差阈、频率阈内求取统计特征函数。
静态试验数据处理 算术平均处理步骤为:
第一步,计算测量数据列x1,x2,…,xi,…,xn的统计量,即算术平均和标准差 。
。
第二步,检验和剔除异常数据。测量中含有过失误差所引起过大过小的数据称为异常数据。怀疑数据中混有异常数据,又无法分析出物理或工程技术上的原因时,则当某可疑数据的残差绝对值|xi-|大于3 判据时,就确定为异常数据,应予剔除。
判据时,就确定为异常数据,应予剔除。
第三步,剔除异常数据后,应根据剩下的数据重新计算、 和算术平均值的标准差(或标准误差)
和算术平均值的标准差(或标准误差) 。
。
对于直接测量参量, 的计算方法:
的计算方法:
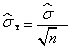
对于间接测量,即被测参量与几个变量成函数关系:
x=f(x1,x2,…,xi,…,xn)
则间接测量的算术平均和算术平均的标准差(或标准误差) 分别按下式求得:
分别按下式求得: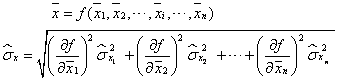
算术平均的表示方法:一是点估计,仅给出统计量x以估计被测参量的真值μ。二是区间估计,在一定的概率P下,估计被测参量的真值可能在内的一个区间,在总体标准差σ未知时遵循t分布。即:
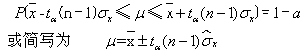
 。
。动态试验数据处理 动态试验数据根据其所表征的参量变化特征,可分为确定性的和随机性的两类(图1)。能够用明确的数学关系式描述的数据称为确定性数据,如多缸往复式发动机的振动响应,旋转件的偏心质量引起的周期性干扰力等。相反,在合理误差范围内,不可能用明确数学关系式来描述的数据称为随机性数据,农业机械动态测量的数据几乎全属这类数据。
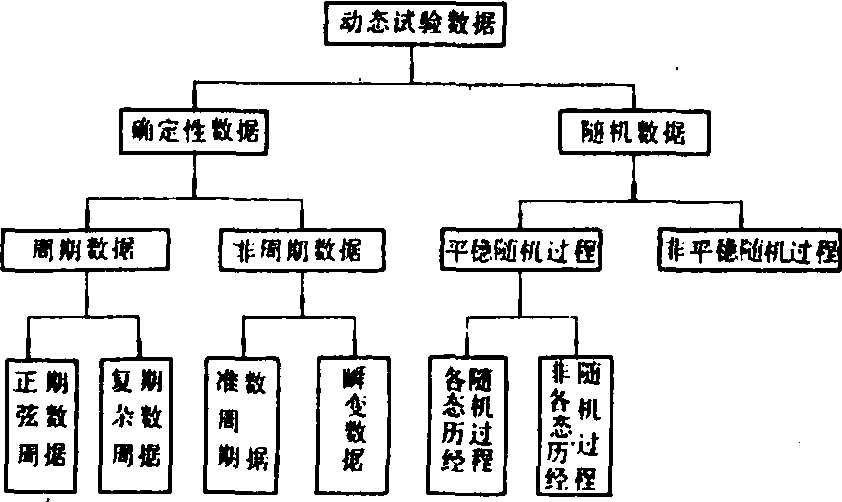
图1 动态试验数据分类
随机数据处理的一般步骤 随机数据处理一般要经过数据准备、数据检验、数据分析和确定统计函数等步骤:❶数据准备,首先对数据进行编排,对磁带机上记录的模拟信号,通过人工或示波器来检测和剔除测量过程中因严重的噪声、仪器失灵等原因造成过高或过低的信号,并为数据数字化处理选择合理的采样频率;
❷数据检验,对随机数据是否满足周期性、正态性、平稳性三个基本特性进行检验;
❸数据分析,对测量结果进行正确的分析和判断;
❹根据数据处理的工程目的来确定需要处理的统计函数。
随机数据的统计函数 理论上需要无穷多个样本函数的集合平均求得随机过程的统计函数。对于各态历经的随机过程可以用实测到的单个样本记录来推断整个随机过程统计特征,以其时间平均来估计集合平均。工程上常假设在各态历经过程的前提下讨论各种统计函数。统计函数共有十几种,它们之间存在着一定的内在关系(图2),处理时可进行互相转换。图中μ、σ2和2是在时阈内的均值、方差和均方值。如计算出农机具拉力的均值、方差和均方值,就可知拉力的平均水平、波动程度和能量等信息。
p(x)和P(x)为概率密度函数和概率分布函数。概率密度函数p(x)定义为瞬时数据值落在某一窄区间内的概率,它是随机数据沿幅值阈分布的规律。工程上常见的概率密度分布函数为正态分布。而瞬时值X(t)小于或等于某值X的概率定义为P(x)。它等于概率密度函数从-∞到X的积分。函数P(x)称为概率分布函数或累积频率函数。如计算出农机具拉力的概率密度函数,就可确定拉力的幅值落在某指定区间内的概率Prob〔X1
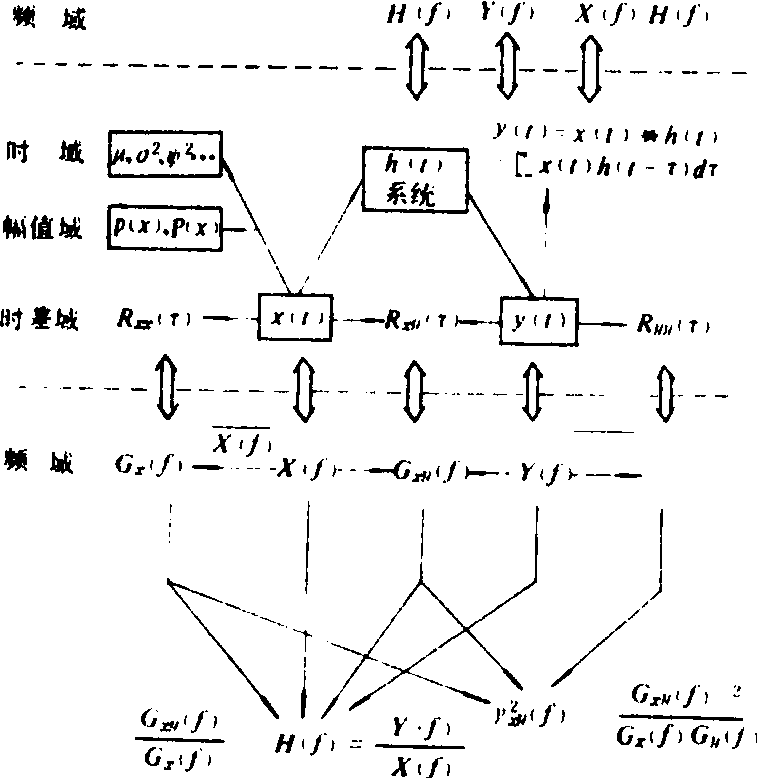
图2 随机数据常用统计函数相互转换关系
Gx(f)和Gxy(f)为自谱密度函数和互谱密度函数。它们分别由自相关函数和互相关函数的傅里叶变换得到,或直接从样本记录的有限傅里叶变换得到。自谱反映随机数据的频率结构及能量在频率域中的分布规律。互谱同样提供了频率的函数,又可以提供输入、输出之间的相位特性,是近代谱分析工程中重要的参数,如寻找振源或评价自走式农业机械的平顺性时均采用谱分析。
h(t)是在时阈中表示系统的脉冲响应函数,如果物理上可行的稳定系统对应的在频阈中用H(f)来表示系统的频率响应函数。它们之间互为傅里叶变换的关系,图中用符号“⇕”表示。频率响应函数定义为初始条件为零时,作用于系统的输出Y(t)与输入X(t)的傅里叶变换函数之比,它是描述系统传递特性的重要函数。如研究运输机械悬架系统减振效能时,测定前桥与车身间的频率响应函数后就可分析出悬架系统对其振动的衰减性能。
γxy2(f)为凝聚函数,又称相干函数。定义为互谱模的平方与输入、输出自谱乘积之比。它是从频阈角度来反映输出与输入之间的凝聚程度。当γxy2 (f) >0.7~0.8时,就认为彼此是凝聚的。
谱分析的关键是分析精度估计,也称谱估计,是分析结果的置信度问题。采集的动态数据为瞬态过程,进行谱分析时,由于FFT的周期图的局限性,宜采用Burg法(或称最大熵法),能获得良好的结果。对于非平稳的随机过程处理,如作为平稳的处理误差较大。同样,对于非线性系统的响应分析,如作为线性系统处理,也会产生较大的误差,甚至是错误。
随机数据统计函数的分析计算,可以在微型计算机上进行,也可以采用分析速度快的专用信号处理机。
数据处理
用计算机收集、记录数据,对数据进行综合分析、经加工产生新的信息形式的技术。主要包括:数据的采集、转换、分组、组织、计算、存贮、检索、排序等。与科学计算相比,原始数据量大时间性强,但计算的数学问题较简单。
数据处理
数据处理是指非科工程方面的对任何形式的数据资料的各种计算、管理和操作。例如,企业管理、库存管理、报表统计、帐目计算、信息情报检索等方面的应用都是数据处理。数据处理的特点是,存储数据所需要的存储空间,远远大于操作数据的程序所需要的空间,数据处理的关键不在于数据处理机的计算能力,而是与程度语言、编程工具和存储设备的容量以及存取速度相关。办公室的中心任务就是处理信息,而最大量的信息是数据信息,如人们熟悉的产品数量、生产指标、原材料数字、计划数字、人口登记数字、消费增长率、城乡储蓄、煤、油、燃料需要量和实际消耗量等。数据处理就是把这些原始资料收集起来,输入到计算机中,让计算机按照一定的数学方法,对它们进行各种加工、计算、分类、排序,最后得到有用的信息。数据库技术是办公自动化系统进行数据处理的有力工具。它为用户提供最充分、最彻底的数据共享和方便易用的数据检索、查询、修改能力。需要进行大型的统计分析和数据模型分析时,还要使用模型库和方法库技术。其中办公活动中最常见的数据处理形式是机关行政事务处理和国际联机情报检索系统。
(1) 机关行政事务处理。任何一个机关中都有行政管理、后勤服务、人事管理部门,工作量大而繁杂。包括食堂、幼儿园、办公用品、机关用房、车辆调度、工资发放、财务管理等。有的大机关还包括宾馆、招待所管理。这些行政事务处理工作是早期的办公自动化系统研究的主要内容,现在已经成熟,并可提供商品化的软件包,如工资管理软件、人事档案管理软件等。它们往往是通过建立各种小型数据库,如人事档案数据库、工资管理数据库系统等,提供了比人工计算、统计快得多的处理能力。它具有统计、查询、排序、求和功能,并可以通过计算、作图、制表等手段对干部队伍进行结构分析,以及对以上结果进行显示、打印或删改,为数据库建立保密等功能。
(2) 国际联机情报检索。一个较大的领导机关的办公活动,不仅可以通过建立本系统信息管理的数据库获得企业内部信息,还需要企业外部的信息,包括国内的、国际上的信息,为了更好地获取有关国际上的经济、社会、民族文化的动态,先进科技水平、产品发展方向、企业经营等的情报,必须建立联机的情报检索系统。建立这种系统的方式有多种,如将国内的计算机网络与国际网络直接连接起来。这种建立方式耗资巨大、技术复杂、信息转换困难。比较简单的是建立联机情报检索终端,这是在本地用一个计算机终端,通过电话线路、长途电话线路、卫星通讯与国际上的计算机网络系统相连接,成为它的检索终端。