- Motivation
- Problem definition
- Popular methods Proto-value basis Krylov basis Bellman error basis Bellman average reward bases
- Discussion and analysis
- See also
- References
- External links
Automatic basis function construction (or basis discovery) is the mathematical method of looking for a set of task-independent basis functions that map the state space to a lower-dimensional embedding, while still representing the value function accurately. Automatic basis construction is independent of prior knowledge of the domain, which allows it to perform well where expert-constructed basis functions are difficult or impossible to create.
Motivation
In reinforcement learning (RL), most real-world Markov Decision Process (MDP) problems have large or continuous state spaces, which typically require some sort of approximation to be represented efficiently.
Problem definition
A Markov decision process with finite state space and fixed policy is defined with a 5-tuple  , which includes the finite state space
, which includes the finite state space  , the finite action space
, the finite action space  , the reward function
, the reward function  , discount factor
, discount factor  , and the transition model
, and the transition model  .
.
Bellman equation is defined as:

When the number of elements in  is small,
is small,  is usually maintained as tabular form. While grows too large for this kind of representation. is commonly being approximated via a linear combination of basis function
is usually maintained as tabular form. While grows too large for this kind of representation. is commonly being approximated via a linear combination of basis function 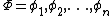 ,[2] so that we have:
,[2] so that we have:
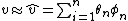
Here  is a
is a  matrix in which every row contains a feature vector for corresponding row,
matrix in which every row contains a feature vector for corresponding row,  is a weight vector with n parameters and usually
is a weight vector with n parameters and usually  .
.
Basis construction looks for ways to automatically construct better basis function which can represent the value function well.
A good construction method should have the following characteristics:
- Small error bounds between the estimate and real value function
- Form orthogonal basis in the value function space
- Converge to stationary value function fast
Popular methods
Proto-value basis
In this approach, Mahadevan analyzes the connectivity graph between states to determine a set of basis functions.[3]
The normalized graph Laplacian is defined as:
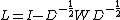
Here W is an adjacency matrix which represents the states of fixed policy MDP which forms an undirected graph (N,E). D is a diagonal matrix related to nodes' degrees.
In discrete state space, the adjacency matrix  could be constructed by simply checking whether two states are connected, and D could be calculated by summing up every row of W. In continuous state space, we could take random walk Laplacian of W.
could be constructed by simply checking whether two states are connected, and D could be calculated by summing up every row of W. In continuous state space, we could take random walk Laplacian of W.
This spectral framework can be used for value function approximation (VFA). Given the fixed policy, the edge weights are determined by corresponding states' transition probability. To get smooth value approximation, diffusion wavelets are used.[3]
Krylov basis
Krylov basis construction uses the actual transition matrix instead of random walk Laplacian. The assumption of this method is that transition model P and reward r are available.
The vectors in Neumann series are denoted as
 for all
for all  .
.
It shows that Krylov space spanned by  is enough to represent any value function,[4] and m is the degree of minimal polynomial of
is enough to represent any value function,[4] and m is the degree of minimal polynomial of 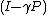 .
.
Suppose the minimal polynomial is  , and we have
, and we have 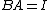 , the value function can be written as:
, the value function can be written as:
[6]
Algorithm Augmented Krylov Method[5]
are top real eigenvectors of P

fordo
ifthen
;
end if
fordo
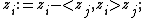
end for
ifthen
break;
end if
end for
- k: number of eigenvectors in basis
- l: total number of vectors
Bellman error basis
Bellman error (or BEBFs) is defined as:  .
.
Loosely speaking, Bellman error points towards the optimal value function.[6] The sequence of BEBF form a basis space which is orthogonal to the real value function space; thus with sufficient number of BEBFs, any value function can be represented exactly.
Algorithm BEBF
stage stage i=1,;
stage
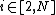
compute the weight vectoraccording to current basis function
;
compute new bellman error by;
add bellman error to form new basis function:;
- N represents the number of iterations till convergence.
- ":" means juxtaposing matrices or vectors.
Bellman average reward bases
Bellman Average Reward Bases (or BARBs)[7] is similar to Krylov Bases, but the reward function is being dilated by the average adjusted transition matrix  . Here
. Here  can be calculated by many methods in.[8]
can be calculated by many methods in.[8]
BARBs converges faster than BEBFs and Krylov when  is close to 1.
is close to 1.
Algorithm BARBs
stage stage i=1,;
stage
compute the weight vector
compute new basis:, and add it to form new bases matrix
;
- N represents the number of iterations till convergence.
- ":" means juxtaposing matrices or vectors.
Discussion and analysis
There are two principal types of basis construction methods.
The first type of methods are reward-sensitive, like Krylov and BEBFs; they dilate the reward function geometrically through transition matrix. However, when discount factor approaches to 1, Krylov and BEBFs converge slowly. This is because the error Krylov based methods are restricted by Chebyshev polynomial bound.[5] To solve this problem, methods such as BARBs are proposed. BARBs is an incremental variant of Drazin bases, and converges faster than Krylov and BEBFs when becomes large.
Another type is reward-insensitive proto value basis function derived from graph Lapalacian. This method uses graph information, but the construction of adjacency matrix makes this method hard to analyze.[5]
See also
- Dynamic programming
- Bellman equation
- Optimal control
References
2. ^Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction.(1998) MIT Press, Cambridge, MA, chapter 8
3. ^1 Mahadevan,Sridhar;Maggioni,Mauro. (2005) Value function approximation with diffusion wavelets and Laplacian eigenfuctions. Proceedings of Advances in Neural Information Processing Systems.
4. ^Ilse C. F. Ipsen and Carl D. Meyer. The idea behind Krylov methods. American Mathematical Monthly, 105(10):889–899, 1998.
5. ^1 2 3 M. Petrik. An analysis of Laplacian methods for value function approximation in MDPs. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), pages 2574–2579, 2007
6. ^R. Parr, C. Painter-Wakefield, L.-H. Li, and M. Littman. Analyzing feature generation for value-function approximation. In ICML’07, 2007.
7. ^S. Mahadevan and B. Liu. Basis construction from power series expansions of value functions. In NIPS’10, 2010
8. ^William J. Stewart. Numerical methods for computing stationary distributions of finite irreducible Markov chains. In Advances in Computational Probability. Kluwer Academic Publishers, 1997.
External links
- UMASS ALL lab
- Potamia, Cyprus
- Potamia, Elassona
- Potamiaena
- Potamia, Evrytania
- Potamiana
- Potamia, Thasos
- Potamia (Thasos), Greece
- Potamia, Xanthi
- Potamidae
- Potamididae
- Potamilus
- Potamilus alatus
- Potamilus amphichaenus
- Potamilus capax
- Potamilus inflatus
- Potamkin Prize
- Potamochoerus
- Potamochoerus larvatus
- Potamochori
- Potamodromous
- Potamodromous fish
- Potamogalidae
- Potamogeton crispus
- Potamogeton natans community
- Potamoi