- Introduction Geometric features Feature space Learning algorithms Geometric feature extraction methods
- Feature learning algorithm
- PAC model based feature learning algorithm Learning framework Evaluation framework
- Applications
- References
Geometric feature learning is a technique combining machine learning and computer vision to solve visual tasks. The main goal of this method is to find a set of representative features of geometric form to represent an object by collecting geometric features from images and learning them using efficient machine learning methods. Humans solve visual tasks and can give fast response to the environment by extracting perceptual information from what they see. Researchers simulate humans' ability of recognizing objects to solve computer vision problems. For example, M. Mata et al.(2002) [1] applied feature learning techniques to the mobile robot navigation tasks in order to avoid obstacles. They used genetic algorithms for learning features and recognizing objects (figures). Geometric feature learning methods can not only solve recognition problems but also predict subsequent actions by analyzing a set of sequential input sensory images, usually some extracting features of images. Through learning, some hypothesis of the next action are given and according to the probability of each hypothesis give a most probable action. This technique is widely used in the area of artificial intelligence.
Introduction
Geometric feature learning methods extract distinctive geometric features from images. Geometric features are features of objects constructed by a set of geometric elements like points, lines, curves or surfaces. These features can be corner features, edge features, Blobs, Ridges, salient points image texture and so on, which can be detected by feature detection methods.
Geometric features
- Primitive features
- Corners: Corners is a very simple but significant feature of objects. Especially, Complexe objects usually have different corner features with each other. Corners of an object can be extracted by using the technique, calling Corner detection. Cho and Dunn [2] used a different way to define a corner by the distance and angle between two straight line segments. This is a new way by defining features as a parameterized composition of several components.
- Edges: Edges are one-dimensional structure features of an image. They represent the boundary of different image regions. The outline of an object can be easily detected by finding the edge using the technique of edge detection.
- Blobs: Blobs represent regions of images, which can be detected using blob detection method.
- Ridges: From a practical viewpoint, a ridge can be thought of as a one-dimensional curve that represents an axis of symmetry. Ridges detection method-see ridge detection
- salient points-see Kadir–Brady saliency detector
- image texture
- Compound features[
- //#3'>3]
- Geometric composition
Geometric component feature is a combination of several primitive features and it always consists more than 2 primitive features like edges, corners or blobs. Extracting geometric feature vector at location x can be computed according to the reference point, which is shown below:
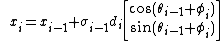
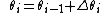
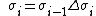
x means the location of the location of features, 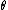 means the orientation,
means the orientation,  means the intrinsic scale.
means the intrinsic scale.
- Boolean Composition
Boolean compound feature consists of two sub-features which can be primitive features or compound features. There are two type of boolean features: conjunctive feature whose value is the product of two sub-features and disjunctive features whose value is the maximum of the two sub-features.
Feature space
Feature space was firstly considered in computer vision area by Segen.[4] He used multilevel graph to represent the geometric relations of local features.
Learning algorithms
There are many learning algorithms which can be applied to learn to find distinctive features of objects in an image. Learning can be incremental, meaning that the object classes can be added at any time.
Geometric feature extraction methods
- Corner detection
- Curve fitting
- Edge detection
- Global structure extraction
- Feature histograms
- Line detection
- Connected-component labeling
- Image texture
- Motion estimation
Feature learning algorithm
1.Acquire a new training image "I".
2.According to the recognition algorithm, evaluate the result. If the result is true, new object classes are recognised.
- recognition algorithm
The key point of recognition algorithm is to find the most distinctive features among all features of all classes. So using below equation to maximise the feature 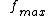
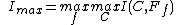
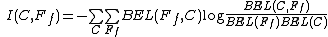
Measure the value of a feature in images, and 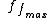 , and localise a feature:
, and localise a feature:
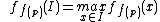
Where 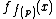 is defined as
is defined as
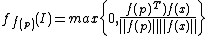
- evaluation
After recognise the features, the results should be evaluated to determine whether the classes can be recognised, There are five evaluation categories of recognition results: correct, wrong, ambiguous, confused and ignorant. When the evaluation is correct, add a new training image and train it. If the recognition failed, the feature nodes should be maximise their distinctive power which is defined by the Kolmogorov-Smirno distance (KSD).
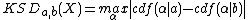
3.Feature learning algorithm
After a feature is recognised, it should be applied to Bayesian network to recognise the image, using the feature learning algorithm to test.
- The main purpose of feature learning algorithm is to find a new feature from sample image to test whether the classes are recognised or not. Two cases should be consider: Searching for new feature of true class and wrong class from sample image respectively. If new feature of true class is detected and the wrong class is not recognised, then the class is recognised and the algorithm should terminate. If feature of true class is not detected and of false class is detected in the sample image, false class should be prevented from being recognised and the feature should be removed from Bayesian network.
- Using Bayesian network to realise the test process
PAC model based feature learning algorithm
Learning framework
The probably approximately correct (PAC) model was applied by D. Roth (2002) to solve computer vision problem by developing a distribution-free learning theory based on this model.[5] This theory heavily relied on the development of feature-efficient learning approach. The goal of this algorithm is to learn an object represented by some geometric features in an image. The input is a feature vector and the output is 1 which means successfully detect the object or 0 otherwise. The main point of this learning approach is collecting representative elements which can represent the object through a function and testing by recognising an object from image to find the representation with high probability.
The learning algorithm aims to predict whether the learned target concept 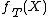 is belongs to a class, where X is the instance space consists with parameters and then test whether the prediction is correct.
is belongs to a class, where X is the instance space consists with parameters and then test whether the prediction is correct.
Evaluation framework
After learning features, there should be some evaluation algorithms to evaluate the learning algorithms. D. Roth applied two learning algorithms:
- 1.Sparse Network of Winnows(SNoW) system
- SNoW-Train
- Initial step: initial the set of features
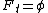 which linked to target t for all
which linked to target t for all 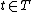 . T is a set of object targets whose elements are
. T is a set of object targets whose elements are 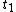 to
to 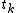
- If each target object in set T belongs to a list of active features, link feature to target and set initial weight at the same time.
- Evaluate the targets : compare targets
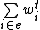 with
with 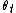 , where
, where 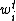 is the weight on one position connecting the features i to target t. \\theta_{t} is the threshold for the target not t.
is the weight on one position connecting the features i to target t. \\theta_{t} is the threshold for the target not t. - Update weight according to the result of evaluation. There are two cases: predicted positive on negative example (
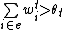 and targets are not in the list of active features) and predicted negative on positive example(
and targets are not in the list of active features) and predicted negative on positive example(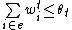 and targets are in the list of active features).
and targets are in the list of active features).
- Initial step: initial the set of features
- SNoW-Evaluation
- Evaluate the each target using same function as introduced above
- Prediction: Make a decision to select the dominant active target node.
- 2.
- //support vector machines">support vector machines
The main purpose of SVM is to find a hyperplane to separate the set of samples 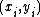 where
where  is an input vector which is a selection of features
is an input vector which is a selection of features 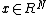 and
and 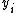 is the label of . The hyperplane has the following form:
is the label of . The hyperplane has the following form:
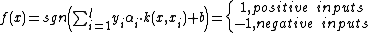
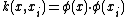 is a kernel function
is a kernel function
Both algorithms separate training data by finding a linear function.
Applications
- Landmarks learning for topological navigation[6]
- Simulation of detecting object process of human vision behaviour[7]
- Learning self-generated action [8]
- Vehicle tracking[9]
References
2. ^Cho, K., and Dunn, S.M "Learning shape classes". IEEE Transactions on Pattern Analysis and Machine Intelligence 16,9(1994), 882-888
3. ^Justus H Piater, "Visual feature learning" (January 1, 2001). Electronic Doctoral Dissertations for UMass Amherst. Paper AAI3000331.
4. ^Segen, J., Learning graph models of shape. In Proceedings of the 5th International Conference on Machine Learning(Ann Arbor, June 12–14, 1988), J. Larid, Ed., Morgan Kaufmann
5. ^D. Roth, M-H. Yang, and N. Ahuja. Learning to recognise three-dimensional objects. Neural Computation, 14(5): 1071–1104, 2002.
6. ^M. Mata, J. M. Armingol, Learning Visual Landmarks for Mobile Robot Navigation, Division of Systems Engineering and Automation, Madrid, Spain, 2002
7. ^I. A. Rybak, BMV: [https://www.spiedigitallibrary.org/conference-proceedings-of-spie/1913/0000/Behavioral-model-of-visual-perception-and-recognition/10.1117/12.152729.short Behavioral Model of Visual Perception and Recognition], Human Vision, Visual Processing, and Digital Display IV
8. ^P. Fitzpatrick, G. Metta, L. Natale, S. Rao, and G. Sandini, “Learning About Objects Through Action - Initial Steps Towards Artificial Cognition,” in IEEE Int. Conf on Robotics and Automation, 2003, pp. 3140–3145.
9. ^J.M. Ferryman, A.D. Worrall, and S.J. Maybank. Learning enhanced 3d models for vehicle tracking. In Proc. of the British Machine Vision Conference, 1998
- Boris Mints
- Boris Mironov (historian)
- Boris Mirski Gallery
- Boris Mityagin
- Boris Moltenis
- Boris Moubhibo Ngonga
- Boris Mouravieff
- Boris Murmann
- Boris Nartsissov
- Boris Naumovich Ginsburg
- Boris Nemtsov Plaza
- Boris Nesterenko
- Boris Nevzorov
- Boris Nešović
- Boris Nikanorov
- Boris Nik'it'ini
- Boris Nikolaevich Poliakov
- Boris Nikolaevsky
- Boris Nikolayevsky
- Boris Nikolic
- Boris Nikolić
- Boris Nikonorov
- Boris Novikov
- Boris Nuraliev
- Boris Nzebo