- Matrix representation
- Randomized algorithm
- References
The set balancing problem in mathematics is the problem of dividing a set to two subsets that have roughly the same characteristics. It arises naturally in design of experiments.[1]{{rp|71–72}}
There is a group of subjects. Each subject has several features, which are considered binary. For example: each subject can be either young or old; either black or white; either tall or short; etc. The goal is to divide the subjects to two sub-groups: treatment group (T) and control group (C), such that for each feature, the number of subjects that have this feature in T is roughly equal to the number of subjects that have this feature in C. E.g., both groups should have roughly the same number of young people, the same number of black people, the same number of tall people, etc.
Matrix representation
Formally, the set balancing problem can be described as follows.
 is the number of subjects in the general population.
is the number of subjects in the general population.
 is the number of potential features.
is the number of potential features.
The subjects are described by  , an
, an 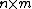 matrix with entries in
matrix with entries in 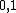 . Each column represents a subject and each row represents a feature.
. Each column represents a subject and each row represents a feature. 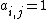 if subject
if subject  has feature
has feature 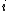 , and
, and 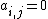 if subject does not have feature .
if subject does not have feature .
The partition to groups is described by  , an
, an 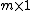 vector with entries in
vector with entries in 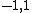 .
. 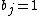 if subject is in the treatment group T and
if subject is in the treatment group T and 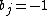 is subject is in the control group C.
is subject is in the control group C.
The balance of features is described by 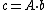 . This is an
. This is an  vector. The numeric value of
vector. The numeric value of  is the imbalance in feature : if
is the imbalance in feature : if 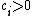 then there are more subjects with in T and if
then there are more subjects with in T and if 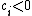 then there are more subjects with in C.
then there are more subjects with in C.
The imbalance of a given partition is defined as:
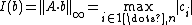
The set balancing problem is to find a vector which minimizes the imbalance 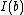 .
.
Randomized algorithm
An approximate solution can be found with the following very simple randomized algorithm:
Send each subject to the treatment group with probability 1/2.
In matrix formulation:
Choose the elements of
Surprisingly, although this algorithm completely ignores the matrix , it achieves a small imbalance with high probability when there are many features. Formally, for a random vector :
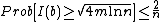
PROOF:
Let  be the total number of subjects that have feature (equivalently, the number of ones in the -th of the matrix ). Consider the following two cases:
be the total number of subjects that have feature (equivalently, the number of ones in the -th of the matrix ). Consider the following two cases:
Easy case: 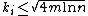 . Then, with probability 1, the imbalance in feature (that we marked by ) is at most
. Then, with probability 1, the imbalance in feature (that we marked by ) is at most  .
.
Hard case: 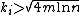 . For every , let
. For every , let 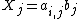 . Each such
. Each such  is a random variable that can be either 1 or -1 with probability 1/2. The imbalance in feature is:
is a random variable that can be either 1 or -1 with probability 1/2. The imbalance in feature is:  . Since the are independent random variables, by the Chernoff bound, for every
. Since the are independent random variables, by the Chernoff bound, for every  :
:
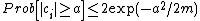
Select: 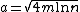 and get:
and get:
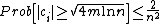
By the union bound,
.
References
- Destin–Fort Walton Beach Airport
- Destouches
- Destrado
- Destratification
- Destrehan, LA
- Destrehan, Louisiana
- Destrier
- Destrii
- Destriianatos
- Destromon
- Destron
- Destroy!
- Destroy 2
- Destroy All Humans
- Destroy All Humans! (video game)
- Destroy All Monsters
- Destroy All Monsters (band)
- Destroyer
- Destroy Erase Improve
- Destroyer (comics)
- Destroyer Command
- Destroyer (disambiguation)
- Destroyer Droid
- Destroyer escort
- Destroyer escorts